
图生LoRA-V2 开源:上传几张图、一次前向生成风格 LoRA,免训练即用,可导出到魔搭 AIGC 专区
构建图像生成模型的风格 LoRA,过去要在 GPU 上跑数百上千步训练。魔搭社区 DiffSynth-Studio 团队开源的 i2L(image-to-LoRA)V2,把这个任务压缩成一次模型前向推理:上传 1 到 8 张风格一致的图,模型直接预测出文生图模型的 LoRA 权重,无需逐风格优化即可即时套用风格。
在 Z-Image、FLUX.2、Hidream-O1 三个基座上,i2L 在风格保真、prompt 一致性与感知质量上全面领先 IP-Adapter、InstantStyle 等以往的图像风格迁移方法。
模型与代码已开源,魔搭创空间可直接在线体验,生成的 LoRA 还能一键上传魔搭、导出后在 AIGC 专区继续使用或下载。
开源地址:
- 模型权重:https://modelscope.cn/collections/DiffSynth-Studio/Image-to-LoRA-V2
- 创空间:
- Z-Image 版:https://modelscope.cn/models/DiffSynth-Studio/ZImage-i2L-v2
- FLUX.2 版:https://modelscope.cn/models/DiffSynth-Studio/KleinBase4B-i2L-v2
- Hidream-O1 版:https://modelscope.cn/models/DiffSynth-Studio/HidreamO1-i2L-v2
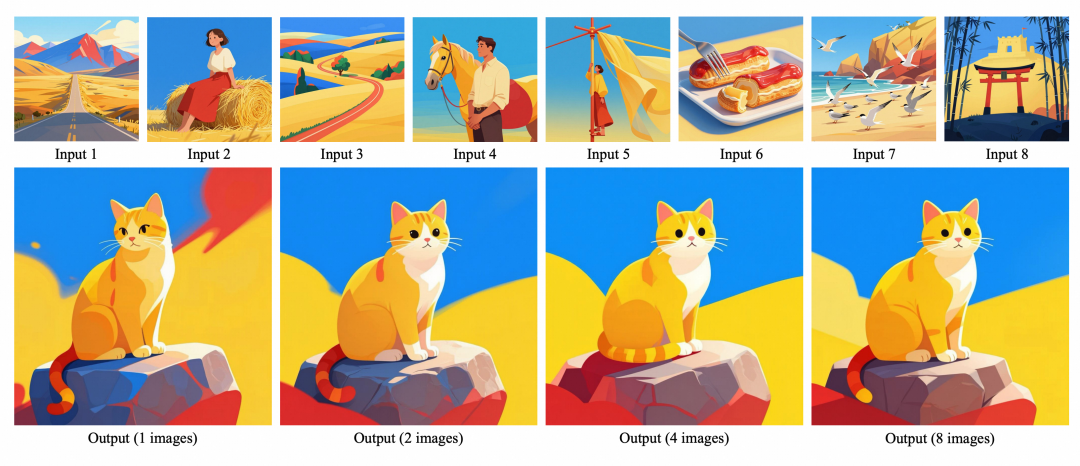
01效果展示与组合能力
输入 4 张风格图片,配合提示词 “A cat is sitting on a stone.“,i2L 在保留参考风格的同时,生成与 prompt 对齐的清晰图像:


因为 i2L 输出的是显式 LoRA 而非临时条件,它天然具备模块化能力,可存储、插值、复用,并通过标准 LoRA 接口与其他模块组合:
• 多风格融合:
从多张不同风格参考图预测出单个 LoRA,让生成图同时继承多种风格来源的视觉属性。

• 与 ControlNet 组合:
深度控制决定空间结构,预测出的 LoRA 提供参考风格。

• 与 AttriCtrl 组合:
AttriCtrl 调整亮度等属性,i2L 维持从参考图提取的风格。

• 与 Inpainting 组合:
编辑遵循 mask 与参考图,同时继承 LoRA 编码的视觉风格。

02技术细节
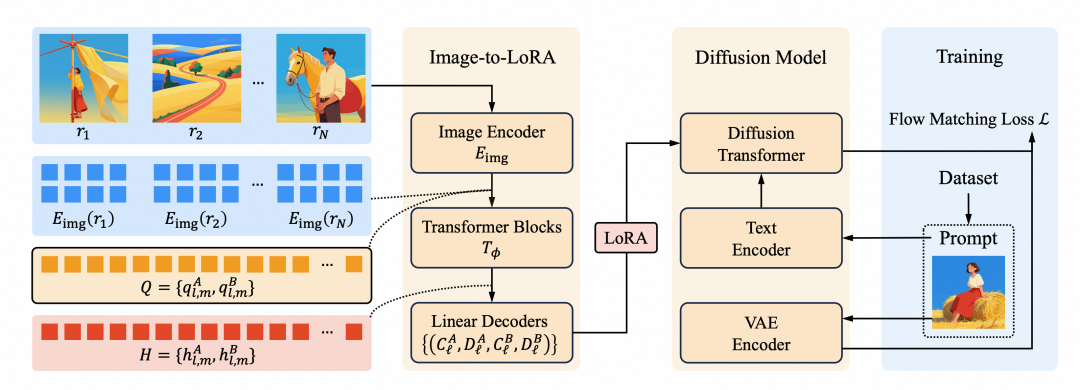
传统路线有两类局限:适配器类(IP-Adapter、ControlNet 等)效率高,但风格只是外部条件,prompt 与参考差异大时容易风格化不彻底或语义污染;优化类(LoRA、DreamBooth)能更好内化风格,但每种新风格都要单独训练。i2L 走第三条路——直接预测生成器的权重更新,把昂贵的逐风格训练循环,替换为一个只训练一次的元模型。
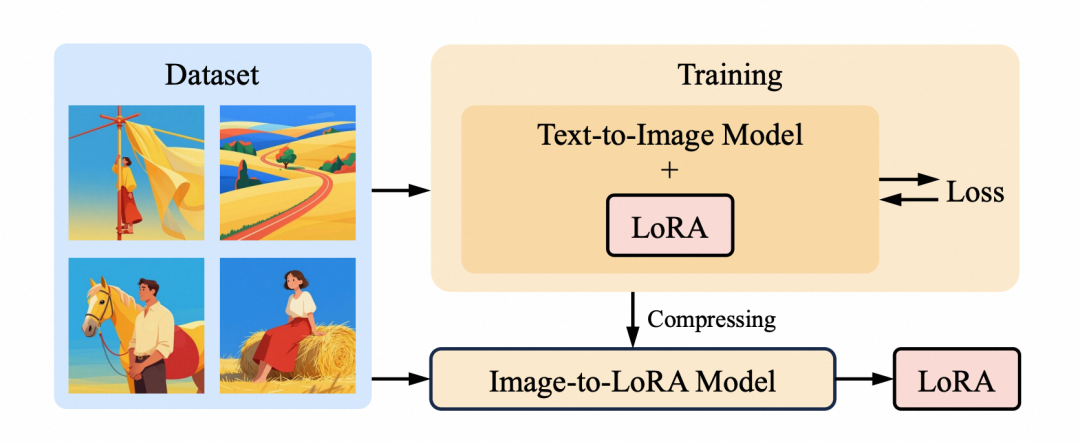
结构化 LoRA query 设计
现代扩散 Transformer 有大量待适配的全链接层,而参考信号可能只有几张图,存在明显的规模不匹配。i2L 不从单个池化向量生成全部权重,而是让每个 LoRA query 对应 LoRA 矩阵的某一行或某一列:对每个适配层,k 个 query 生成矩阵 A 的行、k 个 query 生成矩阵 B 的列,总 query 数为 2kL。参考图经 SigLIP2 编码器编码为图像 token,与 LoRA query 拼接后送入单流 Transformer 聚合,再由每层独立的压缩线性解码头还原出 LoRA 矩阵。
风格-内容解耦的数据构造
普通图文对会诱导模型把参考语义也编码进 LoRA(猫的参考图会让生成的狗也带猫的特征)。i2L 在 MegaStyle-1M 上训练,构造”风格一致、内容不同”的训练元组,且 prompt 只描述目标内容而非参考图,使损失奖励风格一致性、抑制把物体或身份当作捷径复制。
非对称 LoRA 引导
令参考风格 LoRA 作用于 CFG 正分支,由同一 i2L 网络从纯灰图预测的中性 LoRA 作用于负分支。两个分支参数化相近,其差异主要反映参考图带来的风格更新,从而让引导方向放大风格相关效果,而非通用去噪行为——这一切无需额外优化或修改采样器。
训练采用标准 flow-matching 目标,梯度只回传更新 i2L 参数,SigLIP2 编码器与基座文生图模型全程冻结。每个基座在 8 张 A100 上训练约 7 天,学习率 1×10⁻⁵,全局 batch size 为 8,训练框架基于 Diffusion Templates 构建。
03性能表现
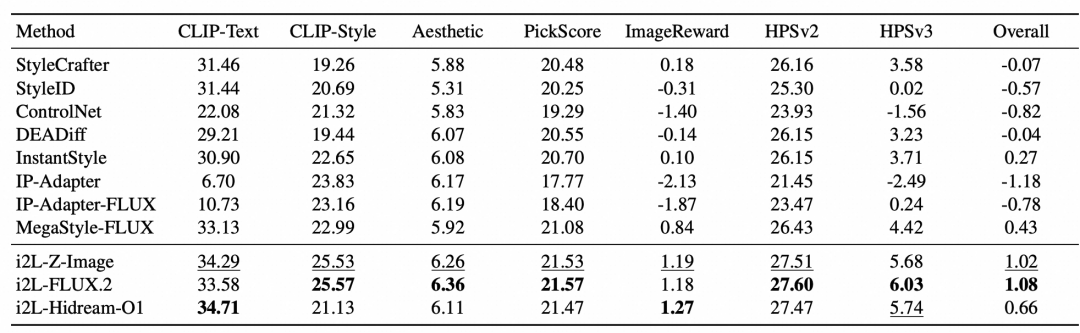
因风格迁移无单一真值,采用多维评测:CLIP-Text 衡量与目标 prompt 的对齐(内容一致性),CLIP-Style 衡量与风格描述的一致性,Aesthetic 估计美学质量,PickScore、ImageReward、HPSv2、HPSv3 提供人类偏好信号,Overall 为各指标归一化后的均值。验证集为 MegaStyle-1M 中留出的 1000 个样本,每个含一条 prompt 和四张输入图。
i2L-FLUX.2 取得最高 Overall(1.08),i2L-Z-Image、i2L-Hidream-O1 在互补指标上同样领先。三个 i2L 变体一致超越特征注入类基线,印证了”用 LoRA 权重表征风格”优于”仅用条件特征”;i2L-Hidream-O1 的高 CLIP-Text 分也说明预测出的 LoRA 较好地保留了内容可控性。
下面为定性的效果对比:


消融实验显示,参考图从 1 张增加到 8 张输出风格基本一致,说明 i2L 学到的是风格层级因子而非逐图复制;开启非对称 LoRA 引导后,特征性的配色、轮廓、表面纹理更突出。
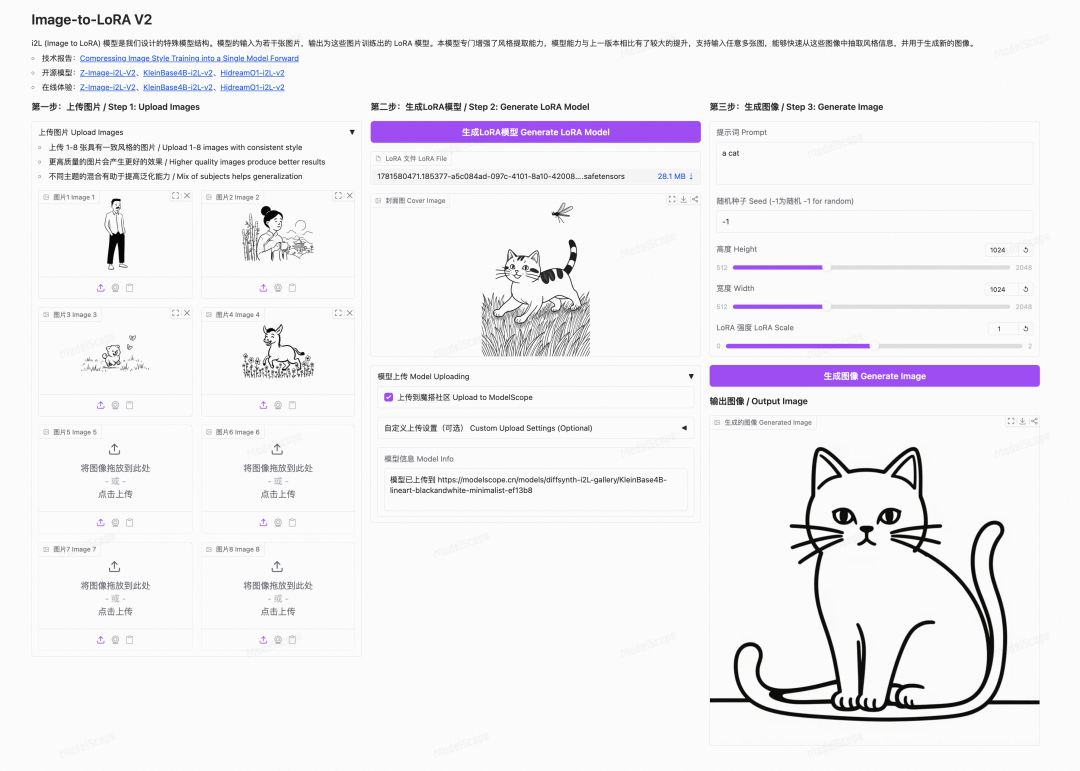
04在魔搭使用
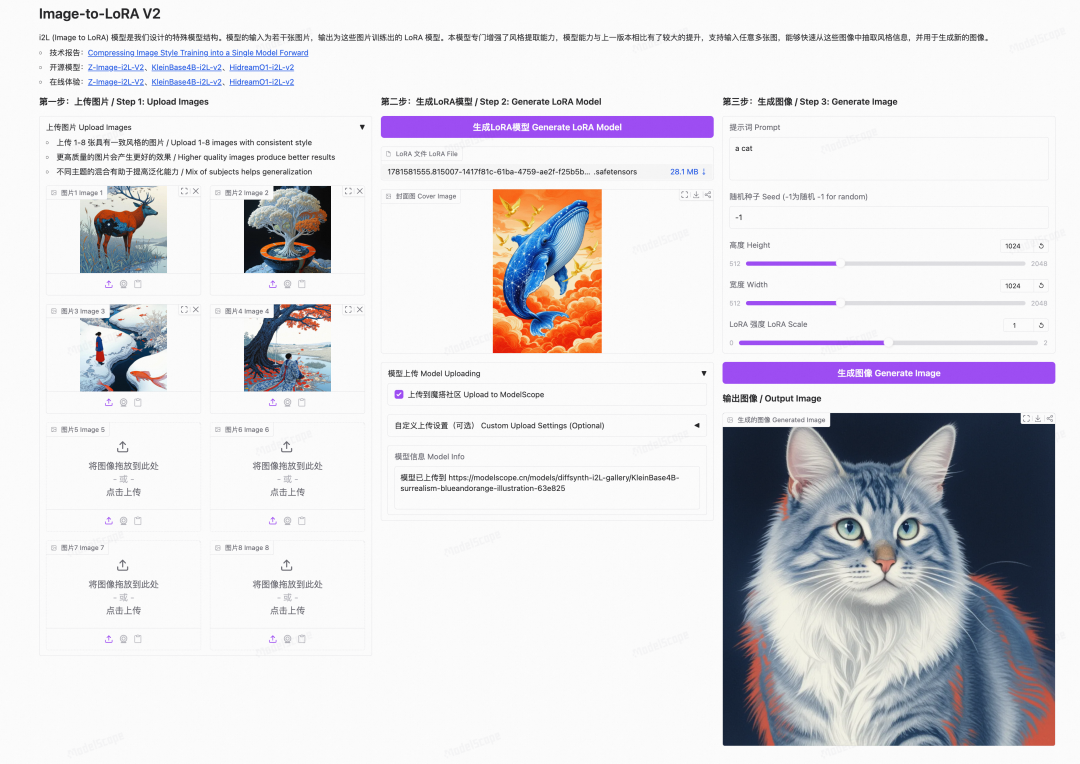
无需写代码,打开任一版本的魔搭创空间即可三步完成风格迁移:
第一步 上传图片 上传 1-8 张风格一致的图片。图片质量越高效果越好,混合不同主题有助于提升泛化能力。
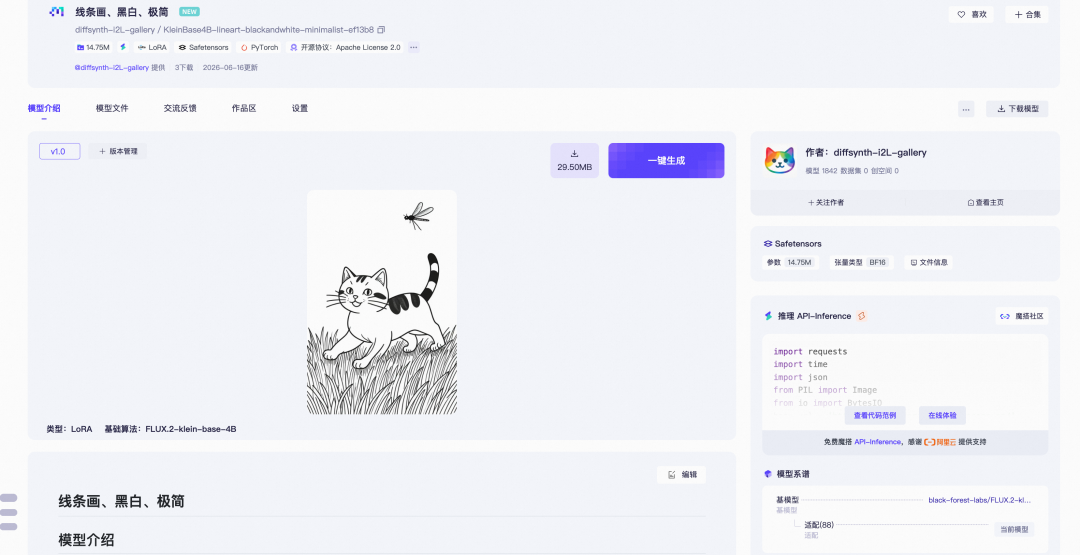
第二步 生成 LoRA 模型 点击”生成 LoRA 模型”,i2L 一次前向预测出 LoRA 文件。可勾选”上传到魔搭社区”,把生成的 LoRA 连同封面图、模型信息自动发布到魔搭,方便复用与分享。
第三步 生成图像 输入提示词,设置随机种子、分辨率(512–2048)与 LoRA 强度,一键生成图像。
生成的 LoRA 既可直接下载到本地,也能在上传魔搭后,作为预加载 LoRA 在魔搭 AIGC 专区一键生成图像,或导入模型训练继续微调,把”一次前向得到的风格”沉淀为可持续迭代的资产。
05代码实践
安装 DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
以 Z-Image 版为例,开启 CFG 增强进行推理(用四张参考图预测 LoRA 并生成):
from diffsynth.diffusion.template import TemplatePipeline
from diffsynth.pipelines.z_image import ZImagePipeline, ModelConfig
from modelscope import snapshot_download
from PIL import Image
import numpy as np, torch
# 加载 Z-Image 基座
pipe = ZImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16, device="cuda",
model_configs=[
ModelConfig(model_id="Tongyi-MAI/Z-Image", origin_file_pattern="transformer/*.safetensors"),
ModelConfig(model_id="Tongyi-MAI/Z-Image-Turbo", origin_file_pattern="text_encoder/*.safetensors"),
ModelConfig(model_id="Tongyi-MAI/Z-Image-Turbo", origin_file_pattern="vae/diffusion_pytorch_model.safetensors"),
],
tokenizer_config=ModelConfig(model_id="Tongyi-MAI/Z-Image-Turbo", origin_file_pattern="tokenizer/"),
)
pipe.enable_lora_hot_loading(pipe.dit) # 开启 LoRA 热加载
# 加载 i2L 预测模型
template = TemplatePipeline.from_pretrained(
torch_dtype=torch.bfloat16, device="cuda",
model_configs=[ModelConfig(model_id="DiffSynth-Studio/ZImage-i2L-v2")],
)
预测 LoRA 并生成(负分支用灰图实现非对称引导):
snapshot_download("DiffSynth-Studio/ZImage-i2L-v2", allow_file_pattern="assets/*", local_dir="data")
images = [Image.open(f"data/assets/multi_input_{i}.jpg") for i in range(4)] # 参考风格图
image = template(
pipe, prompt="A cat is sitting on a stone",
seed=0, cfg_scale=4, num_inference_steps=50,
template_inputs=[{"image": images}],
# 负分支用纯灰图(128)触发非对称 LoRA 引导
negative_template_inputs=[{"image": [Image.fromarray(np.zeros_like(np.array(i)) + 128) for i in images]}],
)
image.save("image_output.jpg")
导出 LoRA 模型文件:
from diffsynth.diffusion.template import TemplatePipeline, ModelConfig
from modelscope import snapshot_download
from safetensors.torch import save_file
from PIL import Image
import torch
template = TemplatePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[ModelConfig(model_id="DiffSynth-Studio/ZImage-i2L-v2")],
)
snapshot_download("DiffSynth-Studio/ZImage-i2L-v2", allow_file_pattern="assets/*", local_dir="data")
images = [Image.open(f"data/assets/multi_input_{i}.jpg") for i in range(4)]
lora = template.call_single_side(inputs=[{"image": images}])["lora"]
save_file(lora, "lora.safetensors"
FLUX.2、Hidream-O1 版本用法一致,仅需替换对应基座与 i2L 模型 id。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献993条内容
已为社区贡献993条内容

所有评论(0)