
GLM-5.2 开源!1M 上下文专攻长程任务,Code Arena 全球可用模型第一
今天,GLM-5.2 正式上线并开源。
在全球百万用户参与盲测的前端开发评估系统Code Arena上,GLM-5.2取得全球可用模型第一的表现。
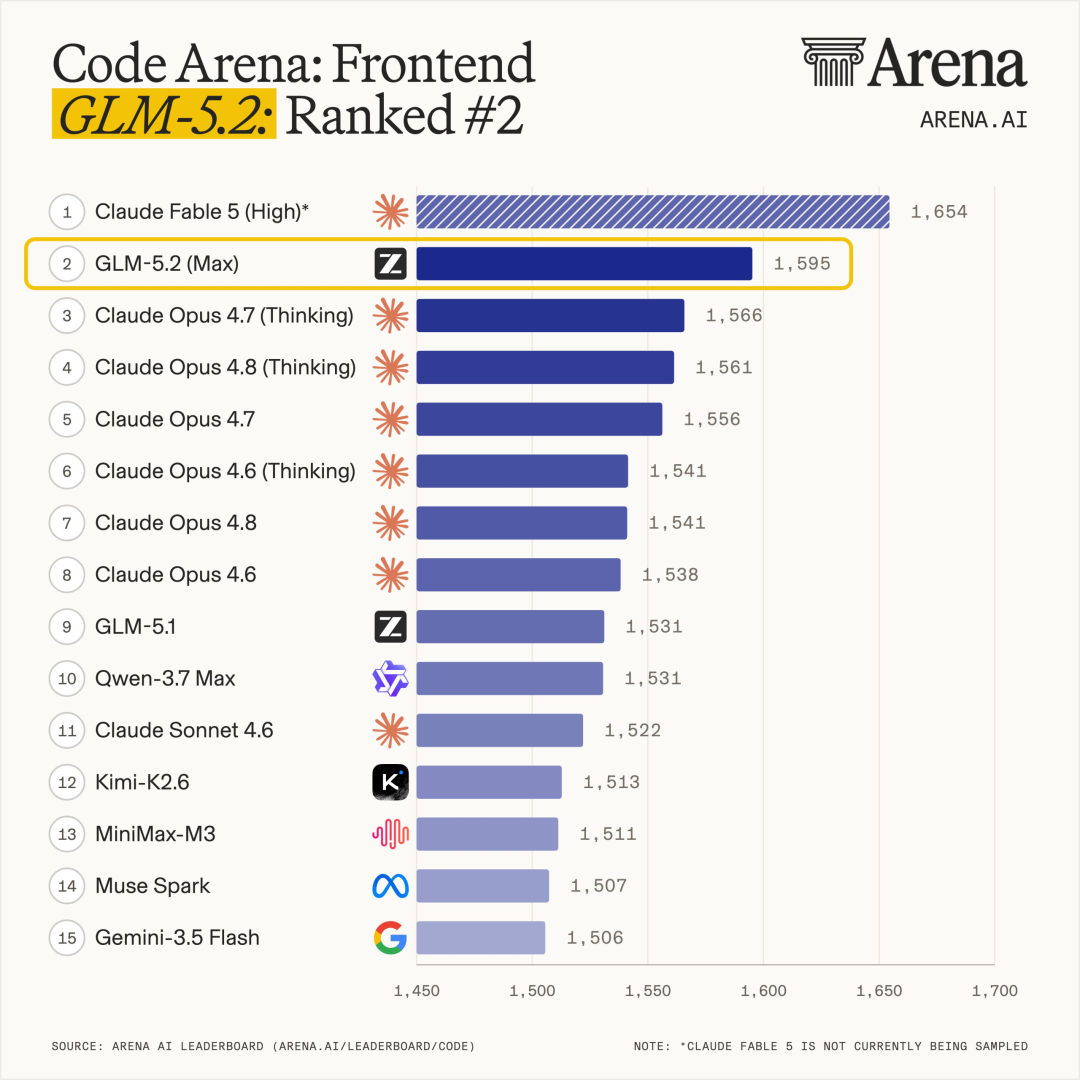
从2025初开始,智谱几乎投入全部力量攻关Coding,历时大半年,细扣每一个代码环境的优化,终于迎来代码基座GLM-4.5,年底的GLM-4.7已经成为效果最好的国产Coding模型。
但代码还不是AGI,在通往AGI的路上,还有更多的高山需要翻越,迎面而来的就是长程任务。当下最需要模型突破的是完成一个极长的,跨越数天、数周乃至数月的任务执行。当一个模型不知疲倦地在写软件工程代码,本质上是在学习一名顶级软件工程师的思维方式,然后以机器的耐力将其放大。这是对一个又一个职业的重新定义。
GLM-5.2正是为长程任务能力而生,全新特色包括:
- Solid 1M上下文,稳定支撑长程任务
- 更强体感,更实用的Coding能力
- 极致Infra优化,Day 0运行在国产算力平台
- MIT开源协议,无地域限制,技术平权无国界
开源地址:
- GLM 5.2:
https://modelscope.cn/models/ZhipuAI/GLM-5.2
- GLM 5.2 FP8:
https://modelscope.cn/models/ZhipuAI/GLM-5.2-FP8
- Blog:
- GitHub:
https://github.com/zai-org/GLM-5
01 1M上下文与长程任务
支撑长程任务的第一步是GLM-5.2必须实现1M无损上下文。此前1M上下文大多数在超过数百K过后就开始劣化,主要问题在于不同时增强Coding Agent环境及数据的情况下单纯扩展到1M帮助有限。为此,智谱花了几个月时间扩展1M Coding Agent的训练环境,覆盖自动化研究、性能优化等多个领域,使得GLM-5.2在1M上下文的solid表现有时甚至超过Opus(详见https://z.ai/blog/glm-5.2%EF%BC%89%E3%80%82
1M上下文构成GLM-5.2的长程交付能力,多个长程任务基准表明GLM-5.2的表现介于Claude Opus 4.7与4.8之间,是排名最高的开源模型。在FrontierSWE(测试AI是否能够像软件工程师在数小时尺度上完成复杂技术项目的测试集)上仅比Opus 4.8低1%,超过GPT-5.5(1%)和Opus 4.7(11%);不过在SWE-Marathon(考察Agent自主完成超长软件工程的测试集)上确实还需要进一步提高,低于Opus 4.8不少(13%)。
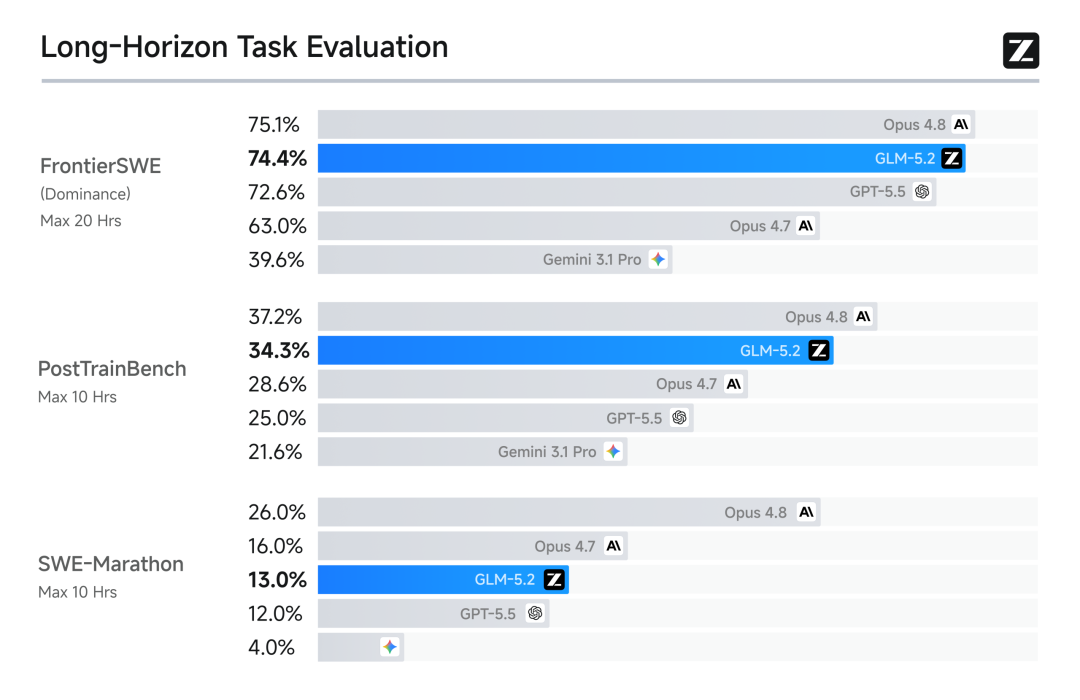
在实际体验中,GLM-5.2完成开发、联调、测试到打包上线,完整交付一个覆盖Web、移动端与小程序的多端应用,累计处理88万tokens,几乎用满1M上下文窗口。过去,这样的大型工程需要一支团队协作数周,现在GLM-5.2能在一次长程任务中跑完。

00:44
02 Coding 体感
GLM-5.2在前端、后端、长程任务上的成功率相比前一代GLM-5.1都有提升,复杂系统工程与深度调试更稳。在主流编程基准上,GLM-5.2保持开源SOTA,与Claude Opus 4.8处于可比区间。例如在Terminal-Bench 2.1(评测AI Agent完成不同类型的计算机终端任务),GLM-5.2比Opus 4.8低4%,相比GLM-5.1提升了17.5%;在MCP-Atlas(大规模工具调研评测的数据集),GLM-5.2比Opus 4.8低0.8%。
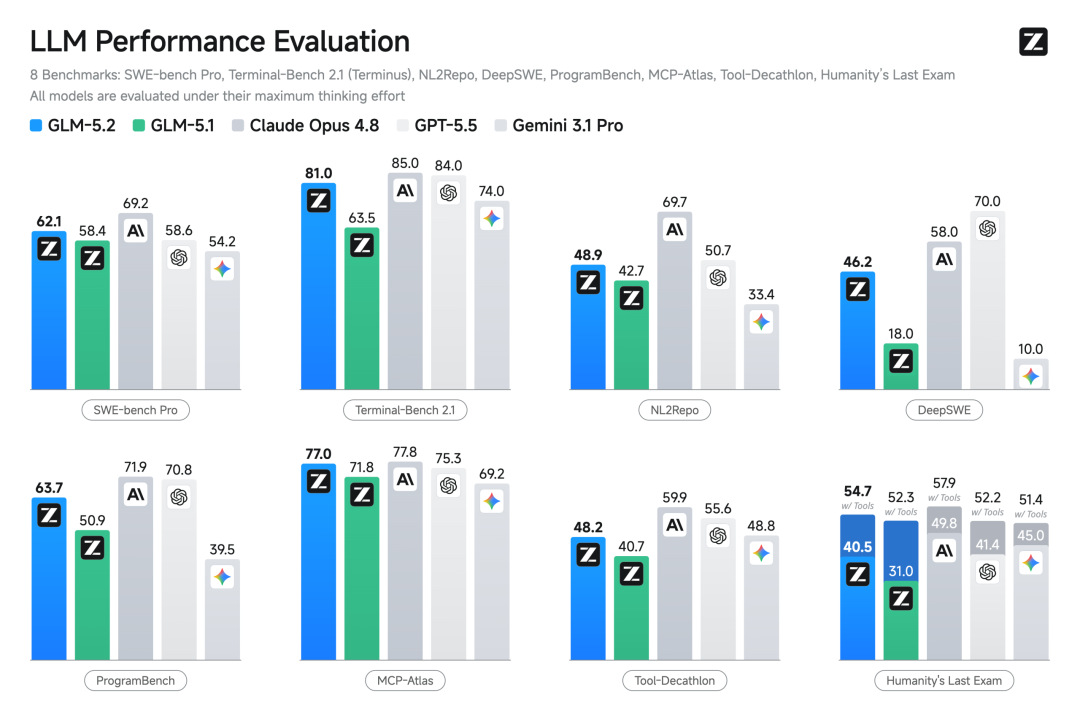
在模型发布前夕,智谱已提前向GLM Coding Plan用户全员开放,在数十万开发者的编程任务中,开发者反馈GLM-5.2的最大提升集中在:
- 项目级上下文承载更强,能把完整工程放进同一条推理链路里;
- 长程任务执行更稳定,复杂任务能持续推进,不容易中途跑偏;
- 生产级工程规范遵循更可靠,能守住团队研发流程里的硬约束;
- 客户端与移动端工程能力更扎实,不止写App,还能完成真机调试闭环。
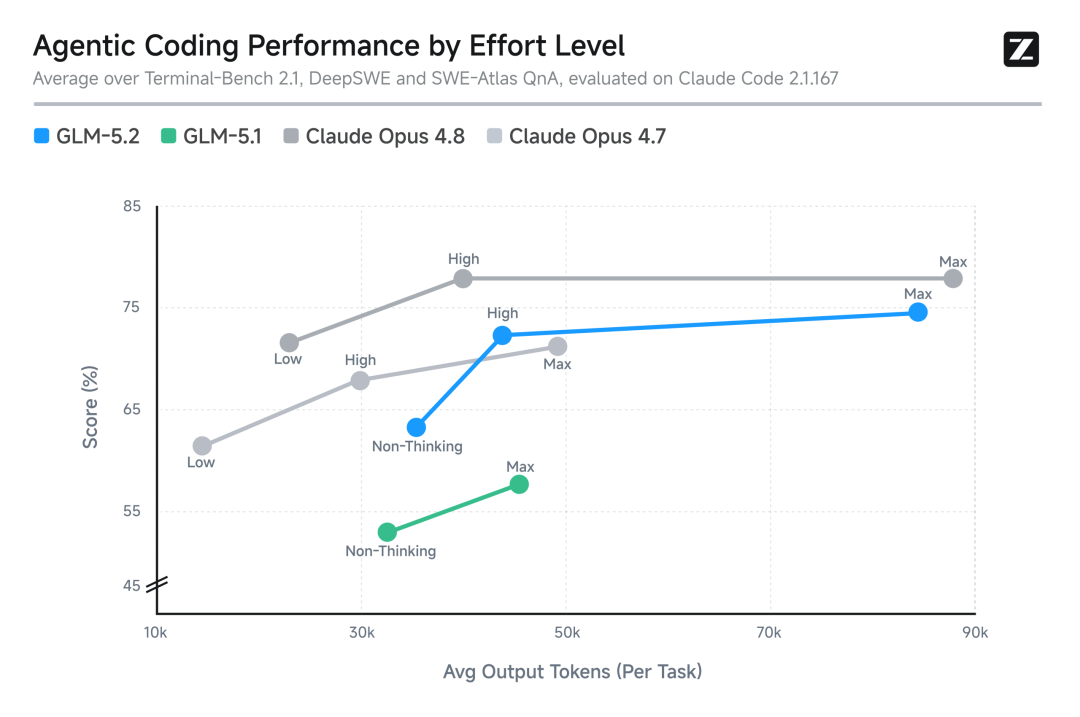
GLM-5.2还引入了effort level(思考档位)控制,可以在能力、速度、成本之间做出平衡。在相近的token预算下,GLM-5.2的Coding能力大致位于Claude Opus 4.7与Claude Opus 4.8之间。
03 极致Infra优化
GLM-5.2的进步来自模型架构、推理系统和训练基础设施的协同设计。智谱提出IndexShare,在每四层稀疏注意力层之间复用同一个索引器(indexer),在1M上下文长度下,将单位token的FLOPs降低至2.9倍。此外,智谱改进了用于投机解码(speculative decoding)的MTP层,将接受长度(acceptance length)最多提升20%。训练侧则依赖自研Slime框架支撑大规模Agentic RL和OPD训练。
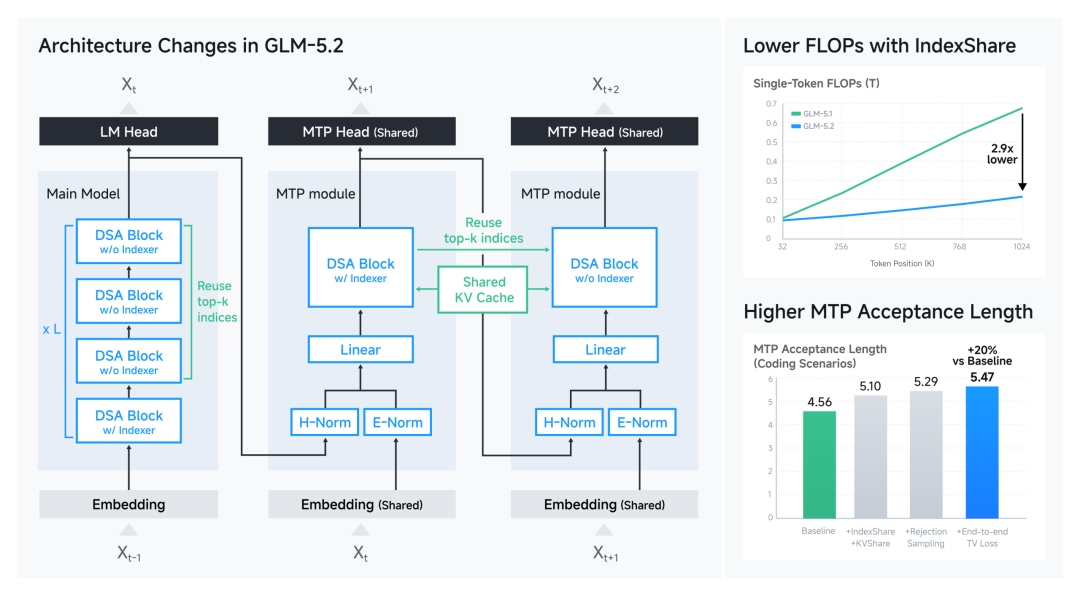
随着GLM系列的持续迭代与调用量的快速增长,线上服务的稳定性与效率愈发关键。GLM-5.2的线上推理依托多个国产算力平台,已在Day 0完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等国产算力平台的推理适配,在国产芯片集群上实现高吞吐、低延迟、大并发的稳定运行。预计下半年昇腾 950 超节点上市后,也将成为GLM-5.2强劲的算力底座。
04 面向开发者与知识工作者
GLM-5.2能长时间自主推进更复杂、更长链路的任务,锁定高价值场景,这将改变开发者与知识工作者的工作方式。
GLM-5.2在大型重构工程上表现出色。有开发者用Rust从零再造了送人类登月的计算机,将当年65000行、一字未改的登月飞控程序移植为Rust,整个过程由Agent全自主走完。
00:47
通过智谱的Agent产品AutoClaw,GLM-5.2的1M上下文与长程任务能力服务于设计、法务等白领场景,例如一次性写出数十个原型页面,自主迭代和微调,在设计中保持品牌规范与一致性。
00:16
05 开源与使用方式
GLM-5.2在Hugging Face与ModelScope开源,模型权重遵循最高权限MIT License,可自由下载、部署与商用。
本地部署
vLLM、SGLang、transformers等主流推理框架已经支持。
模型下载:
modelscope download --model ZhipuAI/GLM-5.2-FP8 --local_dir ZhipuAI/GLM-5.2-FP8
SGLang推理
环境安装
pip install --upgrade pip
pip install uv
uv pip install sglang
8-GPU部署命令(8*H200 or H20)
sglang serve \
--model-path ZhipuAI/GLM-5.2-FP8 \
--tp 8 \
--speculative-algorithm EAGLE \
--speculative-num-steps 5 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 6 \
--mem-fraction-static 0.8 \
--cuda-graph-max-bs 32 \
--host 0.0.0.0 \
--port 30000
vLLM推理
环境安装
docker run --gpus all \
-p 8000:8000 \
--ipc=host \
-v ~/.cache/huggingface:/root/.cache/huggingface \
vllm/vllm-openai:glm51 ZhipuAI/GLM-5.2-FP8 \
--tensor-parallel-size 8 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--chat-template-content-format=string \
--served-model-name glm-5.2-fp8
8-GPU部署命令(8*H200 or H20)
vllm serve ZhipuAI/GLM-5.2-FP8 \
--tensor-parallel-size 8 \
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 3 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--chat-template-content-format=string \
--served-model-name glm-5.2-fp8
vLLM推理指南:https://github.com/vllm-project/recipes/blob/main/GLM/GLM5.md
Transformers推理
环境安装:
pip install transformers
推理脚本:
from transformers import pipeline
pipe = pipeline(
task="text-generation",
model="ZhipuAI/GLM-5.2-FP8",
)
pipe("The theory of relativity states that")
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("ZhipuAI/GLM-5.2-FP8")
model = AutoModelForCausalLM.from_pretrained(
"ZhipuAI/GLM-5.2-FP8",
device_map="auto",
)
input_ids = tokenizer("The theory of relativity states that", return_tensors="pt").to(model.device)
output = model.generate(**input_ids, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Transformers推理指南:https://github.com/huggingface/transformers/blob/main/docs/source/en/model/_doc/glm/_moe/_dsa.md
其他使用方式
GLM-5.2 官方API已上线,并已纳入GLM Coding Plan,长上下文与长程任务同步升级,全量用户可使用。
1.官方 API 接入
- BigModel开放平台:https://docs.bigmodel.cn/cn/guide/models/text/glm-5.2
- Z.ai:https://docs.z.ai/guides/llm/glm-5.2
2.在线体验
- Z.ai:https://chat.z.ai/
- 智谱清言App/网页版:https://chatglm.cn/
3.Agent
- AgentAutoClaw(办公场景):https://autoglm.zhipuai.cnzcode/
- (代码工具):https://zcode.z.ai/cn
06 尾声
AGI路上还有更多的高山要翻越,智谱将下一座目标瞄向完全自治的智能体系统(Autonomous Agent System)。基于长程任务之上,让AI能够自主驱动、协同作业、7×24小时运转的智能体群体将成为新的生产力形态。从“智能助手”走向“数字员工”,构建包含成千上万个不同专业“性格”与“技能”的智能体社会,让它们自主辩论、协作、审查代码、调度资源,实现“自动驾驶”级别的数字生产力。很多核心技术还需要攻关:Memory、持续学习(Continual Learning)、自我评判(Self-Judge)。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐

 0
0 0
0- 0



 已为社区贡献993条内容
已为社区贡献993条内容

所有评论(0)