
MiniMax M3 开源:前沿 Coding & Agentic 能力 · 百万上下文 · 原生多模态
00 引 言
MiniMax 刚刚开源了 MiniMax M3,国内首个同时具备原生多模态、超长上下文、Agent 操作 三大能力的模型。
M3 采用全新稀疏注意力架构 MSA(MiniMax Sparse Attention),最高支持 1M 上下文——在 100 万上下文下每 token 计算量仅为上代的 1/20,prefilling 加速超 9 倍、decoding 加速超 15 倍。
在 Coding 能力方面,M3 相比 M2 显著增强,在 bugfix、前后端、性能优化等方面均接近海外闭源模型。
在 Agentic 能力方面,M3 在办公常用的搜索、Office 能力上表现突出,并在金融领域变得初步可用。
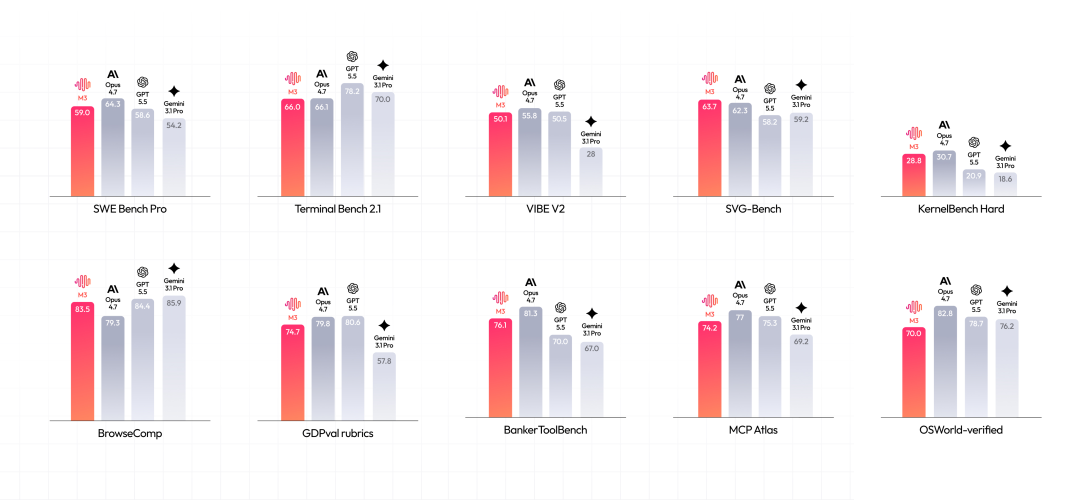
本次同步开源原始权重的 MiniMax-M3 与 MXFP8 量化版 MiniMax-M3-MXFP8,后者面向更低显存占用与更高效的部署场景。
开源地址:
- MiniMax-M3:
https://www.modelscope.cn/models/MiniMax/MiniMax-M3
- MiniMax-M3-MXFP8:
https://www.modelscope.cn/models/MiniMax/MiniMax-M3-MXFP8
- 官方博客:
https://www.minimaxi.com/blog/minimax-m3
01 实测案例
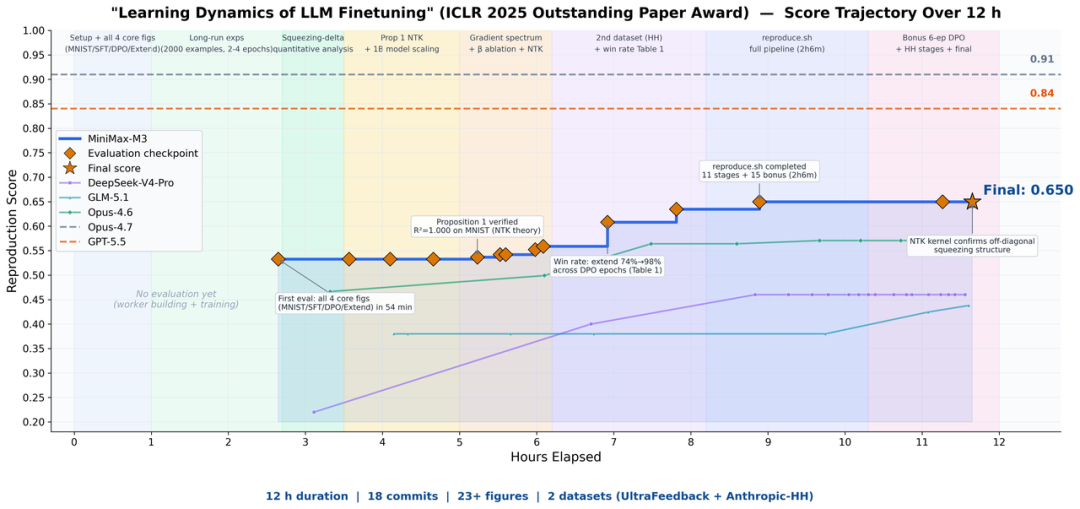
论文复现:12 小时自主完成 ICLR 杰出论文
丢给 M3 一篇 ICLR 2025 杰出论文 — Learning Dynamics of LLM Finetuning,让它独立复现。M3 连续运行近 12 小时,全程自主产出 18 次 commit 与 23 张实验图表,成功跑通核心实验。多模态看懂论文里的图表公式,长上下文保证论文 + 代码 + 实验日志一次性进窗口,编程 + Agent 能力驱动长线程执行。
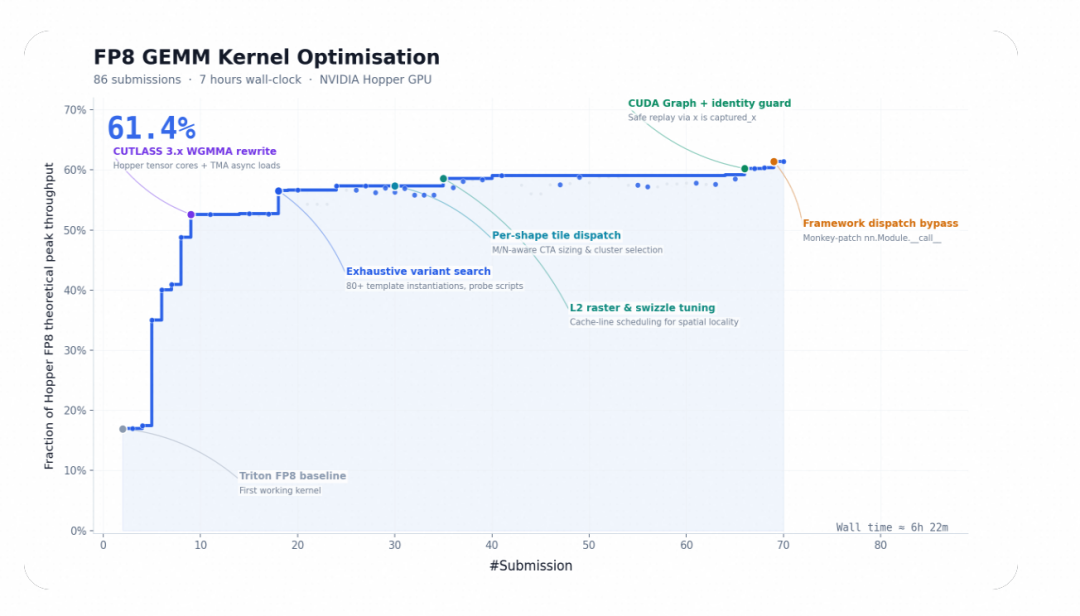
CUDA 算子优化:147 次迭代,9.4× 加速
FP8 矩阵乘是大模型推理计算量最集中的环节之一。让 M3 在 NVIDIA Hopper 架构上优化该 kernel,起点仅有任务描述和一个无法运行的 Triton 骨架。M3 在约 24 小时内完成 147 次 benchmark 提交、1959 次工具调用,将硬件峰值利用率从 7.6% 推进至 71.3%,实现 9.4× 加速——全程零人工介入。
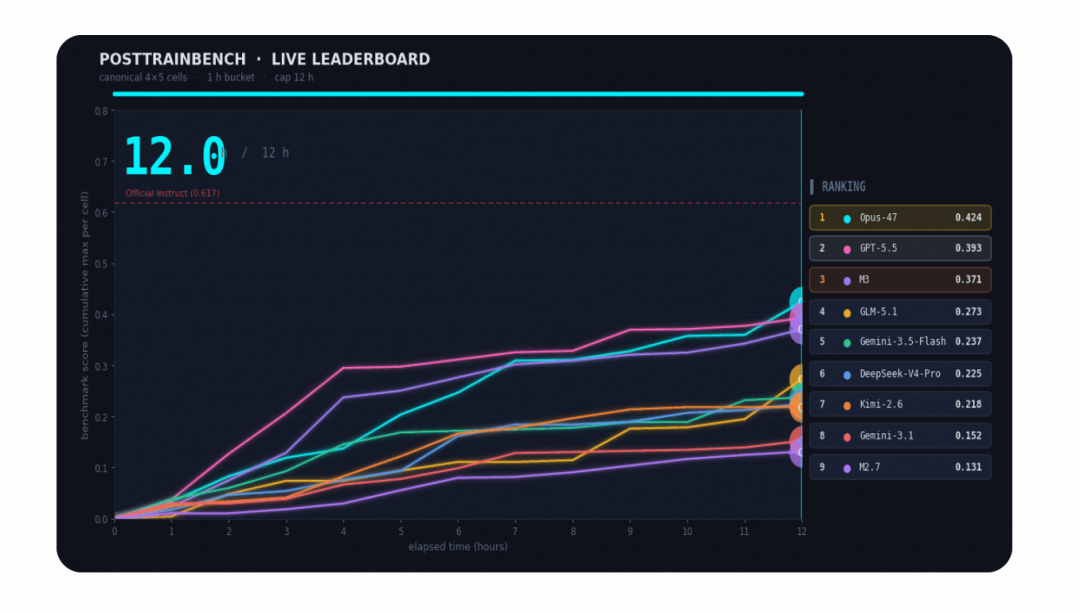
PostTrainBench:让 M3 自己「训」模型
给 M3 四个只完成预训练的 Base 模型,要求在 12 小时内自主完成数据合成、训练、评测、迭代全流程,让它们在数学推理、代码生成、知识问答等任务上具备能力。整个流程全程无人干预,M3 最终得分 37.1,位列第三,仅次于 Opus 4.7(42.4)和 GPT-5.5(39.3),明显领先其余模型。
02 模型结构
在设计 MiniMax M3 模型时,解决更复杂的 Agent 任务是它最重要的目标之一,而其中最大挑战就包括 context scaling。要实现真正的改变,必须从最底层的注意力机制入手,避开全注意力机制计算复杂度平方级增长的“先天缺陷”。
MSA 是一个简洁且易于扩展的全新稀疏注意力架构,它给 M3 带来了 1M 的上下文窗口,并让 context 真正成为又一个可被 scale 的维度。
稀疏注意力机制普遍通过增加一个初筛阶段来避免复杂度爆炸问题。与 DSA 和 MoBA 等方案相比,MSA 可以更精确为 KV 分块,实现更高的有效上下文覆盖。
同时,研究团队还在算子层直接优化,采用以 KV 块为外层来聚合命中 query 的 KV outer gather Q。每块只读一次、访存连续,在 M3 的 head 配比下计算访存比显著优于通行方法,比开源的 Flash-Sparse-Attention、flash-moba 快 4 倍以上。
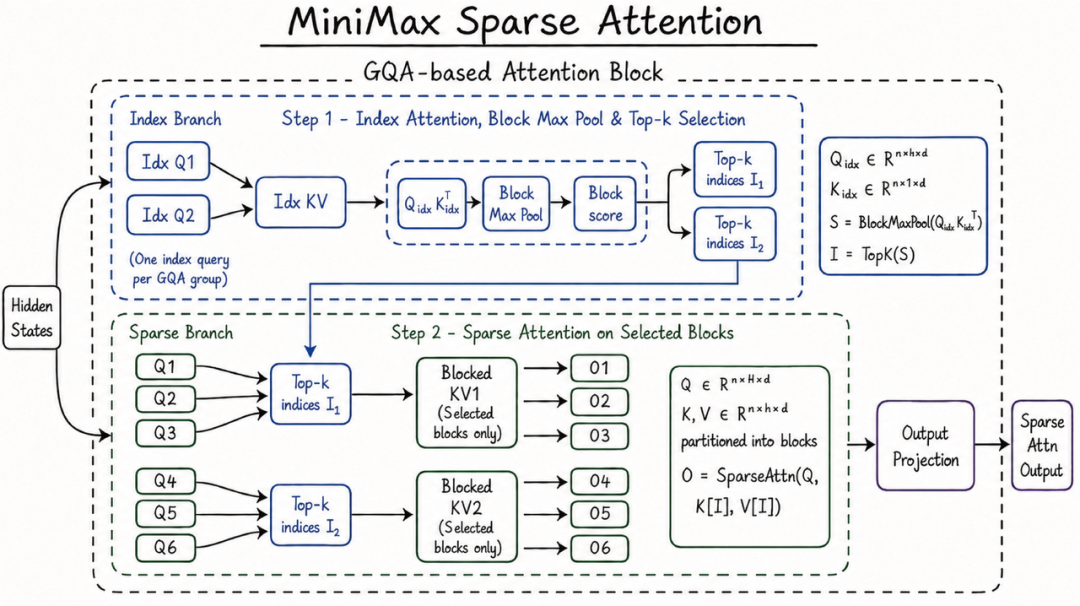
简洁可扩展、易于实现且硬件友好的特点,使它的理论收益能真正落地:在 100 万上下文下,M3 每 token 计算量仅为上代模型的 1/20。在 prefilling 阶段,我们实现了超过 9 倍的加速倍率,在 decoding 阶段有超过 15 倍的加速优势。而且在多个对照实验中,MSA 的绝大部分能力与全注意力打平。
03 模型体验
通过魔搭API-Inference免费体验
魔搭社区有限量额度的免费API,入口在魔搭模型页右侧,欢迎大家体验。

通过 MiniMax Code 接入
MiniMax Code 是官方 Agent 应用 ,可直接使用 Token Plan开箱即用。支持桌面端和网页版。网页版界面如下:
本地部署
模型下载:
modelscope download --model MiniMax/MiniMax-M3-MXFP8 --local_dir MiniMax/MiniMax-M3-MXFP8
SGLang推理
环境安装
pip install -U uv
uv venv --python 3.12 && source .venv/bin/activate
# MiniMax-M3 ships in SGLang PR
#27944
, not yet in a tagged release — install from
# the PR head. The serving runtime is in the base dependencies, so no extra is needed:
git clone https://github.com/sgl-project/sglang.git
cd sglang
git fetch origin pull/27944/head && git checkout FETCH_HEAD
uv pip install -e python
4-GPU部署命令
sglang serve \
--trust-remote-code \
--model-path MiniMaxAI/MiniMax-M3-MXFP8 \
--reasoning-parser auto \
--tool-call-parser auto \
--tp 4 \
--attention-backend fa4 \
--page-size 128 \
--moe-runner-backend deep_gemm \
--chunked-prefill-size 8192 \
--mem-fraction-static 0.75 \
--host 0.0.0.0 \
--port 30000
vLLM推理
环境安装
docker pull vllm/vllm-openai:minimax-m3
4-GPU推理命令
docker run --gpus all \
--privileged --ipc=host -p 8000:8000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
vllm/vllm-openai:minimax-m3 MiniMaxAI/MiniMax-M3-MXFP8 \
--block-size 128 \
--tensor-parallel-size 8 \
--tool-call-parser minimax_m3 \
--enable-auto-tool-choice \
--reasoning-parser minimax_m3
vLLM推理指南:
https://recipes.vllm.ai/MiniMaxAI/MiniMax-M3?variant=mxfp8
Transformers推理
环境安装:
pip install transformers
推理脚本
import torch
from transformers import AutoModelForImageTextToText, AutoProcessor
from transformers.image_utils import load_image
model = AutoModelForImageTextToText.from_pretrained(
"MiniMaxAI/MiniMax-M3-preview", dtype=torch.bfloat16, device_map="auto",
)
processor = AutoProcessor.from_pretrained("MiniMaxAI/MiniMax-M3")
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Describe this image briefly."},
],
}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
inputs = processor(images=[image], text=text, return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=32, do_sample=False)
print(processor.batch_decode(generated_ids, skip_special_tokens=True)[0])
Transformers推理指南:
https://huggingface.co/docs/transformers/main/en/model/_doc/minimax/_m3/_vl#overview

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献990条内容
已为社区贡献990条内容

所有评论(0)