
Mistral Medium 3.5开源:一套权重搞定编码、推理和指令遵循,4块GPU即可部署
Mistral AI发布了Mistral Medium 3.5,首次将指令遵循(Medium 3.1)、推理(Magistral)和编码(Devstral 2)三条模型线统一为单一128B稠密模型,256K上下文窗口。SWE-Bench Verified 77.6%,超越Devstral 2和Qwen3.5 397B。开源权重支持商业使用,最少4块GPU(80GB+显存)即可自部署。
开源地址:
- ModelScope:https://modelscope.cn/models/mistralai/Mistral-Medium-3.5-128B
- 技术博客:https://mistral.ai/news/vibe-remote-agents-mistral-medium-3-5
核心特性
三模型合一 将指令遵循、推理和编码能力统一到单一128B稠密权重中,替代此前三个独立模型。无需根据任务类型在不同模型间路由,通过reasoning_effort参数按请求调整推理强度即可。
编码能力开源领先 SWE-Bench Verified 77.6%,超越Devstral 2(72.2%)和Qwen3.5 397B。已替代Devstral 2成为Vibe CLI默认模型。
多模态输入 从零训练视觉编码器,原生支持可变图像尺寸和宽高比,适用于文档分析、图表理解和UI截图解读。
256K上下文窗口 可处理约20万字上下文,支持跨完整代码库推理和长时Agent任务。
多语言支持 支持英语、法语、西班牙语、德语、中文、日语、韩语、阿拉伯语等数十种语言。
低成本部署 稠密架构最少4块GPU(80GB+显存)即可运行。采用修改版MIT许可证,支持商业使用。
性能表现
Agent基准
| 基准 | Mistral Medium 3.5 | 备注 |
| SWE-Bench Verified | 77.6% | 超越Devstral 2(72.2%)和Qwen3.5 397B |
| τ³-Telecom | 91.4% | 领域Agent基准,测试工具选择和多步执行 |
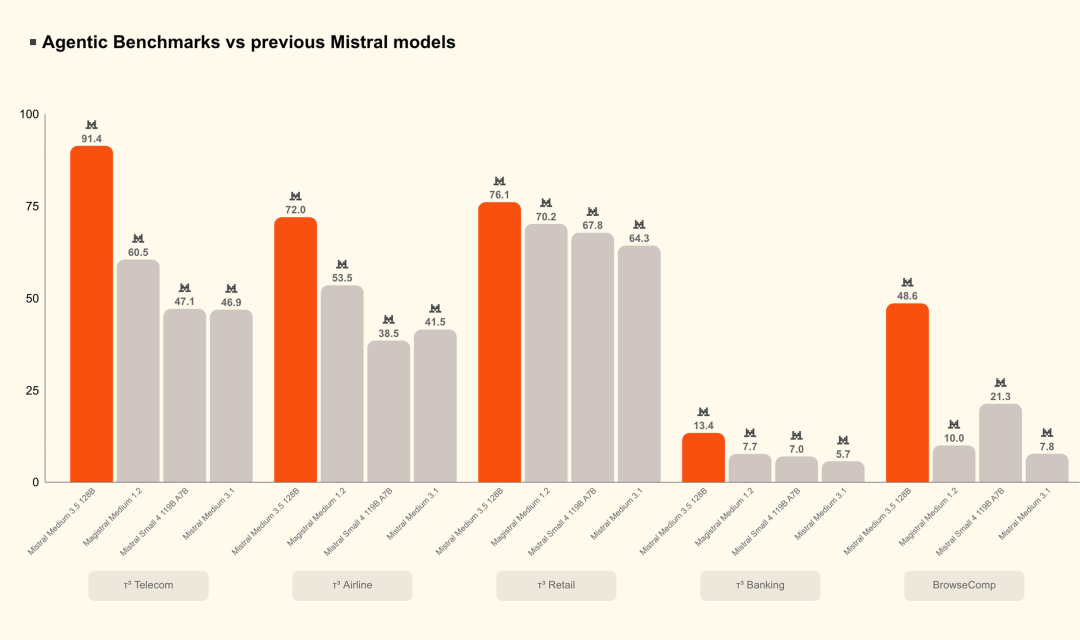
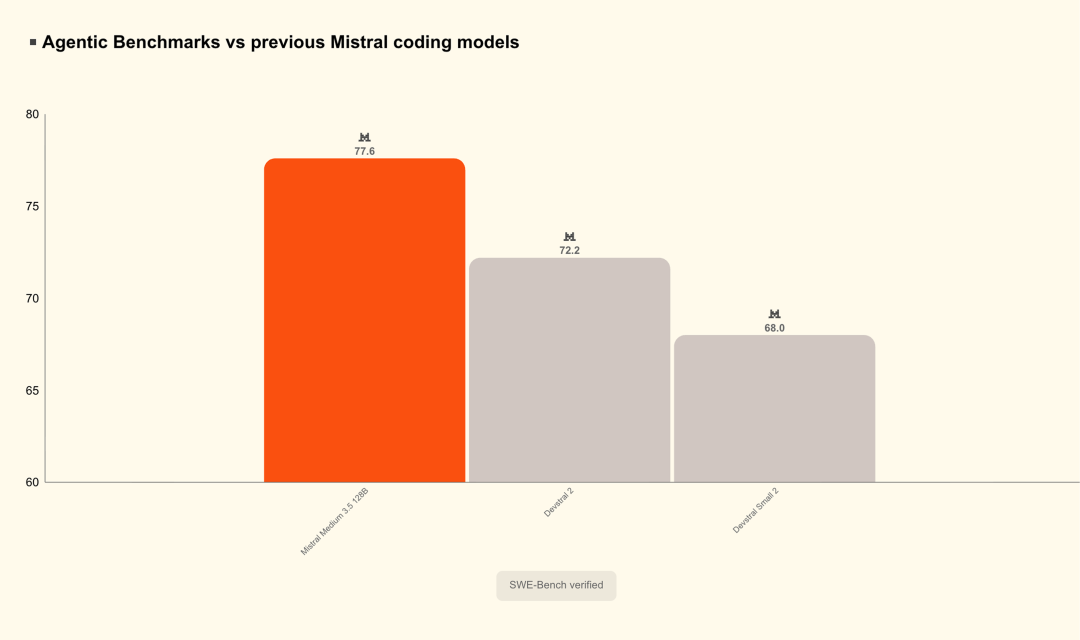
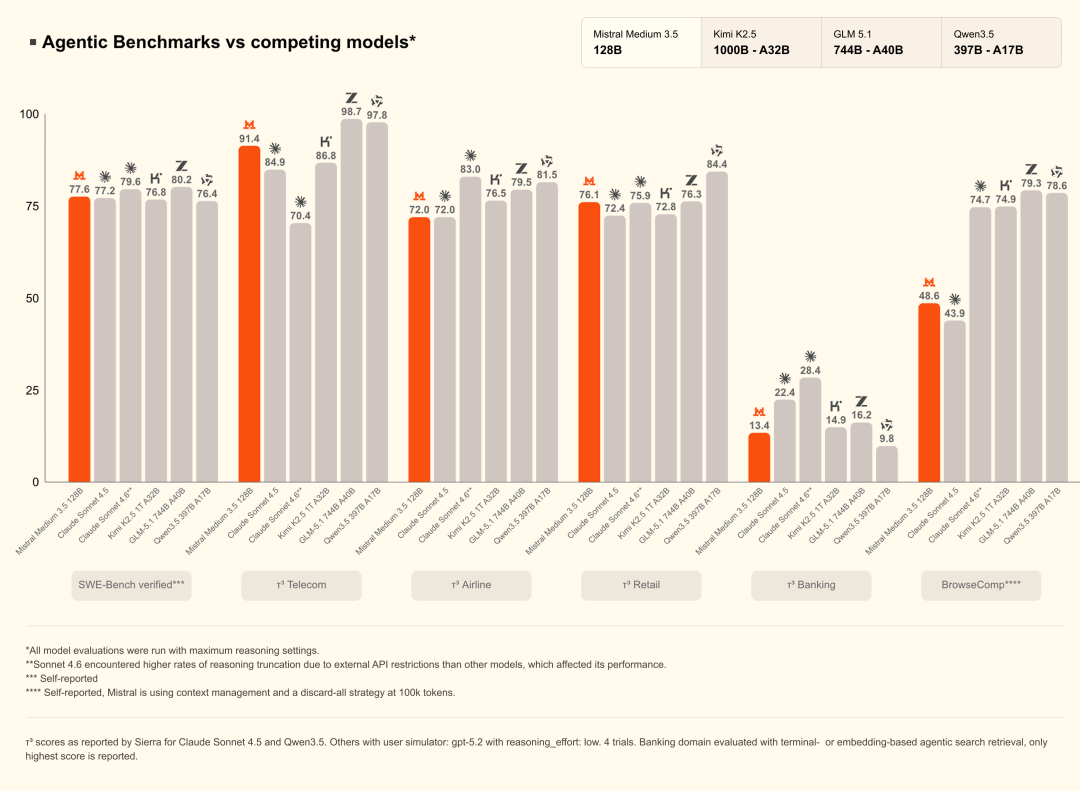
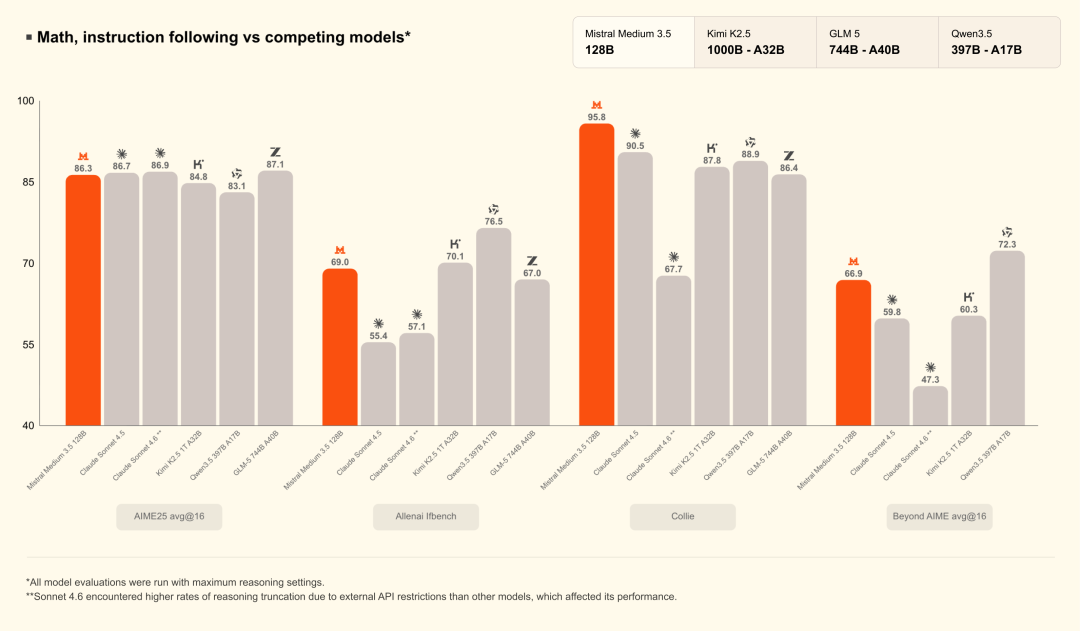
指令遵循、推理与编码
得益于统一能力,Mistral Medium 3.5在指令遵循、数学推理和编码基准上均取得强劲表现,全面超越此前的Medium 3.1、Magistral和Devstral 2。
模型部署与推理
vLLM部署(推荐)
安装vLLM nightly版本(需mistral_common >= 1.11.1和transformers >= 5.4.0):
uv pip install -U vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly启动服务:
vllm serve mistralai/Mistral-Medium-3.5-128B --tensor-parallel-size 8 \
--tool-call-parser mistral --enable-auto-tool-choice \
--reasoning-parser mistral --max_num_batched_tokens 16384 \
--max_num_seqs 128 --gpu_memory_utilization 0.8可搭配EAGLE模型加速推理。
SGLang部署
提供专用Docker镜像,支持Hopper和Blackwell GPU:
vllm serve mistralai/Mistral-Medium-3.5-128B --tensor-parallel-size 8 \
--tool-call-parser mistral --enable-auto-tool-choice \
--reasoning-parser mistral --max_num_batched_tokens 16384 \
--max_num_seqs 128 --gpu_memory_utilization 0.8
启动服务:
python -m sglang.launch_server --model-path mistralai/Mistral-Medium-3.5-128B \
--tp 8 --tool-call-parser mistral --reasoning-parser mistral
API调用示例
部署后通过兼容OpenAI的接口调用:
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
response = client.chat.completions.create(
model="mistralai/Mistral-Medium-3.5-128B",
messages=[
{"role": "user", "content": "Write me a sentence where every word starts with the next letter in the alphabet."}
],
reasoning_effort="high",
temperature=0.7,
top_p=0.95,
)
print(response.choices[0].message.content)支持指令遵循、工具调用和视觉推理等多种使用方式。
其他部署方式
- Ollama:
ollama run mistral-medium-3.5 - llama.cpp:使用Unsloth提供的GGUF量化版本
- Transformers:
pip install transformers后直接加载
推荐参数
复杂任务和Agent编码场景建议使用reasoning_effort="high"。temperature越低回答越精准,越高越有创造性,建议根据具体任务尝试不同值。
| 模式 | reasoning_effort | temperature | top_p |
| 快速响应 | "none" | 0.0 - 0.7 | 1.0 |
| 推理模式 | "high" | 0.7 | 0.95 |
微调
支持通过Axolotl和Unsloth进行微调,详见模型卡片。
模型卡片:https://modelscope.cn/models/mistralai/Mistral-Medium-3.5-128B/summary
总结
Mistral Medium 3.5将指令遵循、推理和编码三条独立模型线统一到128B稠密架构中,一个模型覆盖此前三个模型的全部能力。SWE-Bench Verified 77.6%达到开源编码最强水平。稠密架构简化部署和调优,4块GPU即可运行,配合EAGLE模型可进一步加速,为开发者提供了高性价比的全能基座选择。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献958条内容
已为社区贡献958条内容

所有评论(0)