
蚂蚁百灵双响开源:万亿旗舰 Ling-2.6-1T 与 高效 Agent 主力 Ling-2.6-flash
随着大模型从"单轮问答"走向真实业务系统,行业的关注点正在发生变化。过去模型竞争更多围绕参数规模和榜单分数展开;但在真实生产环境中,开发者和企业真正关心的是:
- 能否在复杂上下文中稳定理解任务?
- 能否精准遵循指令、可靠调用工具?
- 能否在多步骤工作流中持续执行?
- 能否在成本、延迟、Token 消耗可控的前提下交付可用结果?
围绕这一趋势,蚂蚁百灵团队本次同步开源两款模型:
Ling-2.6-1T:万亿级综合旗舰,面向复杂任务,强调多步执行稳定性与高智效比
- 模型地址:
https://www.modelscope.cn/models/inclusionAI/Ling-2.6-1T - OpenRouter 体验:https://openrouter.ai/inclusionai/ling-2.6-1t:free
Ling-2.6-flash:总参 104B、激活 7.4B 的 Instruct 模型,主打极致推理效率与 Agent 场景表现。
- 模型地址:https://www.modelscope.cn/models/inclusionAI/Ling-2.6-flash
- OpenRouter 体验地址为:https://openrouter.ai/inclusionai/ling-2.6-flash:free
Ling-2.6-1T:面向复杂任务的万亿旗舰模型
Ling-2.6-1T 不是为了单纯追求更长的思考链,或制造更强的"参数规模体感",而是面向真实复杂任务,系统性优化模型的智效比、指令执行、工具适配、长上下文承接、工程任务处理等核心能力。
它要解决三个问题:
- 更低 Token 开销下保持强综合智能:依托 MLA 与 Linear Attention 的 Hybrid 架构创新,结合抑制"过程冗余"的强化奖励策略,在保持 1T 参数能力上限的同时,减少对冗长思考链的依赖,以更高效的"快思考"机制直达结果。
- 复杂任务中实现更可靠的多步执行:强化对指令、工具、上下文与中间状态的持续把控,提升噪声环境下的推理与精准作答能力。
- 让万亿模型真正进入开发者和企业的生产工作流:具备从代码生成到缺陷修复的完整工程落地能力,并与主流 Agent 框架高度兼容。
换言之,Ling-2.6-1T 追求的不只是"更强",而是在真实使用中做到更高效、更落地、更智能。
模型表现
高智效比,进入第一梯队
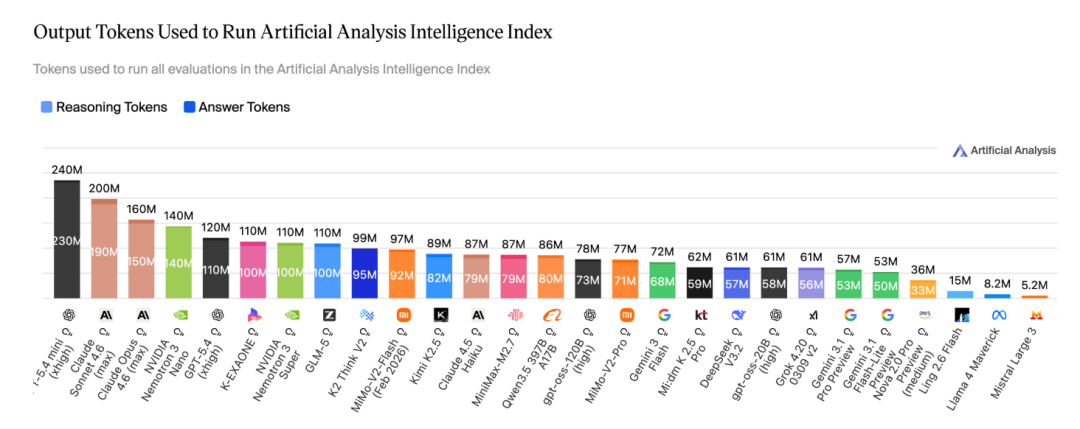
在 Artificial Analysis 评测中,Ling-2.6-1T 以约 16M output tokens 达到约 34 分 Intelligence Index,进入图中的高吸引力区间。
- 相比 Ling 系列早期旗舰 Ling-1T,能力实现明显跃迁;
- 已展现出与 GPT-5.4(Non-Reasoning)同档的综合智能表现;
- 相较部分依赖更高 token 消耗换取更高分数的模型,Ling-2.6-1T 在效率与能力之间更均衡。
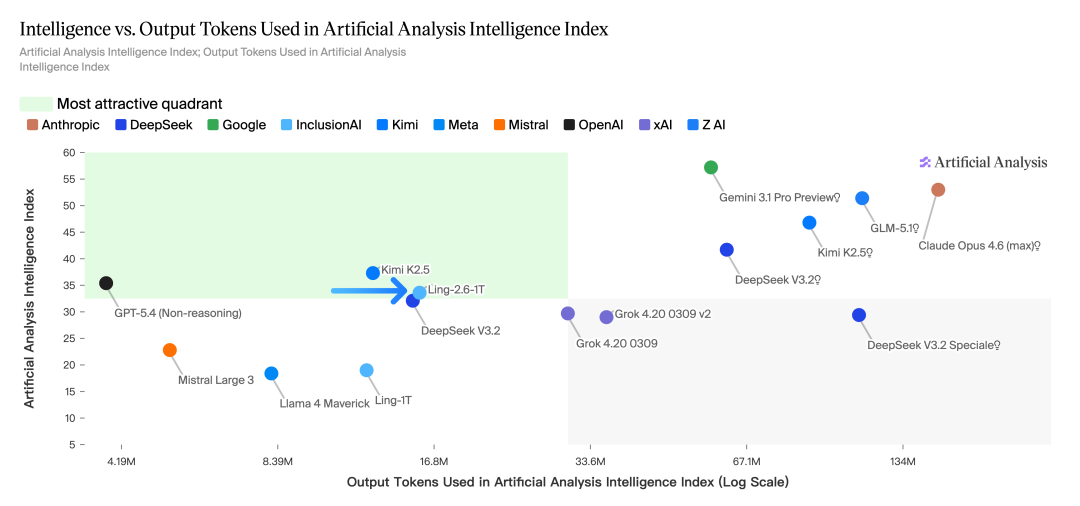
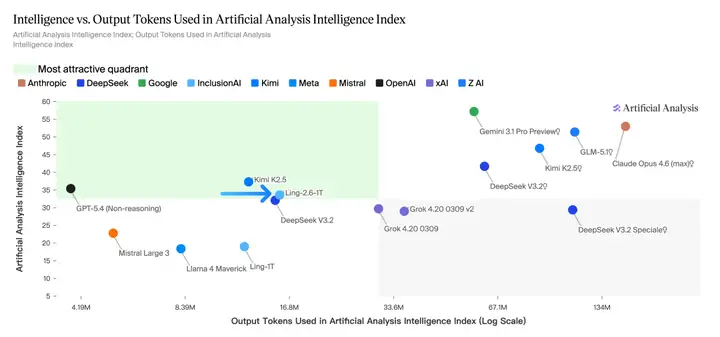
更关键的是,Ling-2.6-1T 仅用 16M tokens 跑完完整评测,在同类模型中展现出极突出的 Token Efficiency,体现出更低成本、更高吞吐、更强落地性的综合优势。
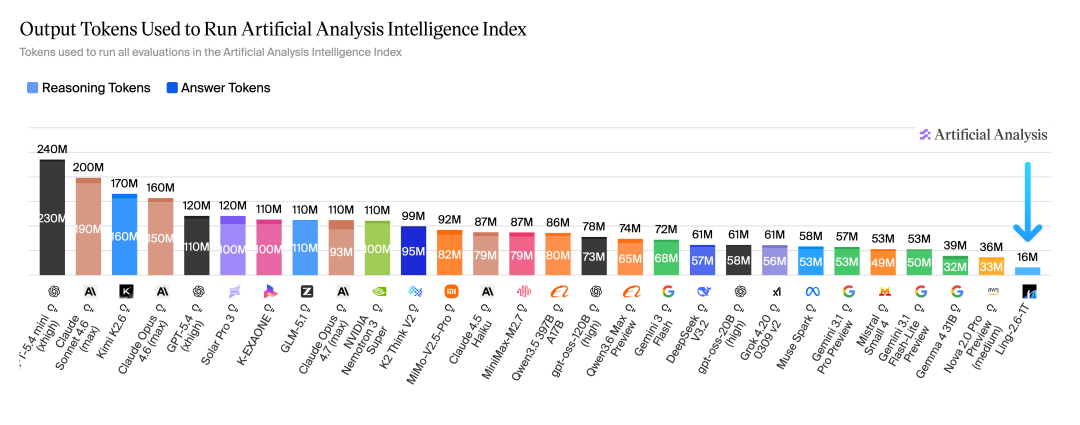
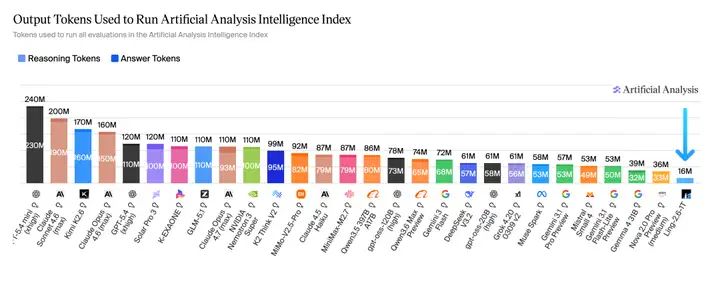
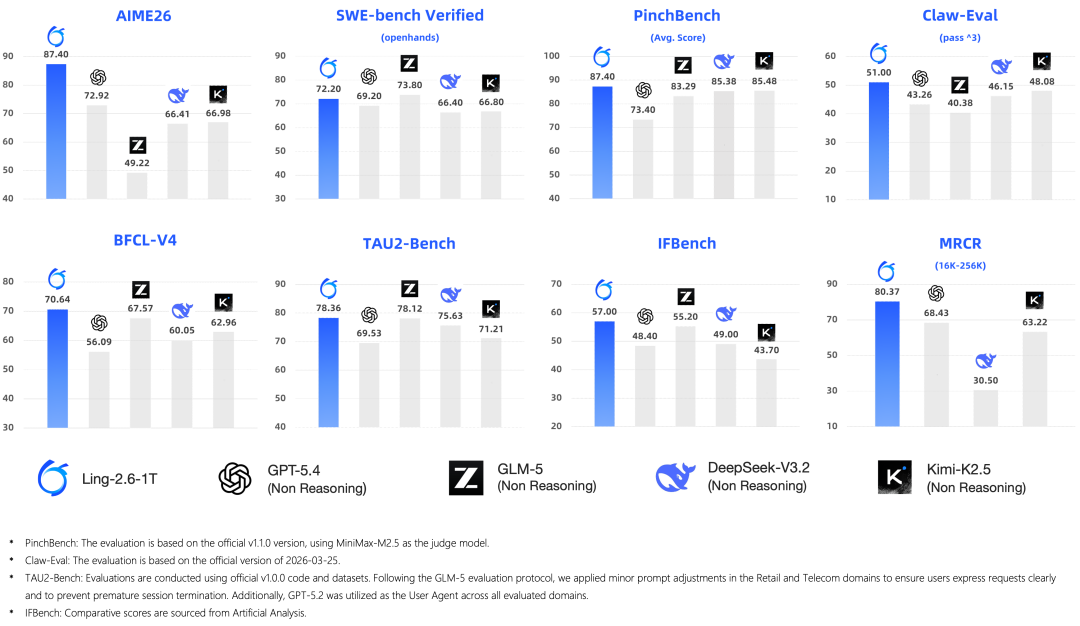
复杂任务执行能力:多个执行类基准开源 SOTA
在推理、代码、工具调用、多步任务执行等维度,Ling-2.6-1T 展现出均衡的综合能力:
- 高难推理:AIME26 取得 87.40,显著领先 GPT-5.4、GLM-5、DeepSeek-V3.2、Kimi-K2.5 等非思考模型;
- Agent 执行:SWE-bench Verified 72.20、TAU2-Bench 78.36、Claw-Eval 51.00、BFCL-V4 70.64、PinchBench 87.40,均位列第一梯队;
- 长上下文与指令遵循:MRCR (16K-256K) 80.37、IFBench 57.00,在多重约束下的执行准确率与逻辑一致性表现稳定。
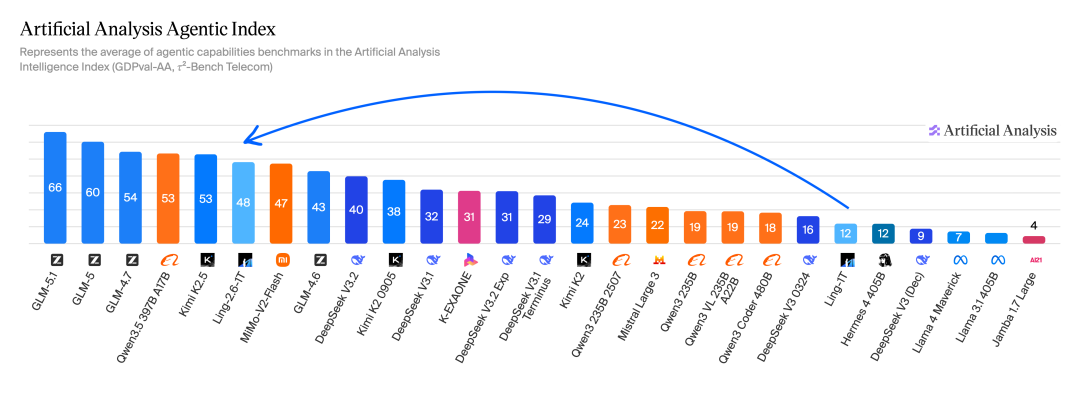
在 Artificial Analysis Agentic Index 与 Coding Index 上,Ling-2.6-1T 也已进入头部模型梯队。
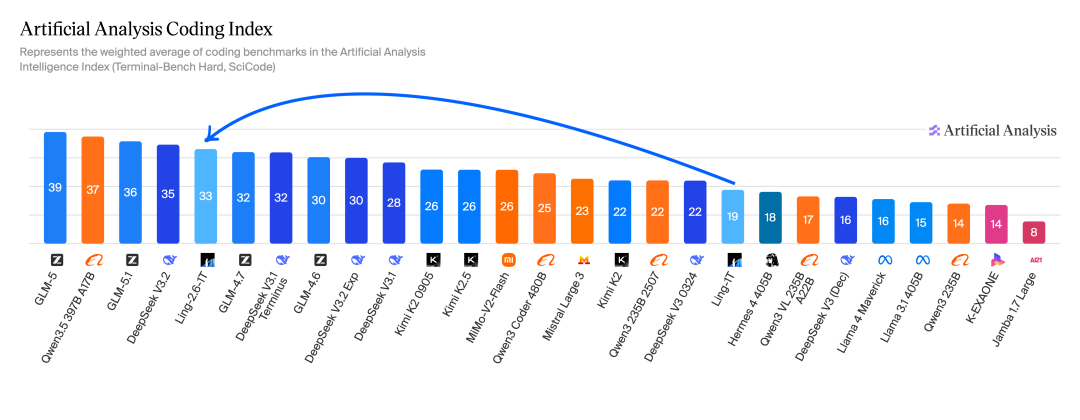
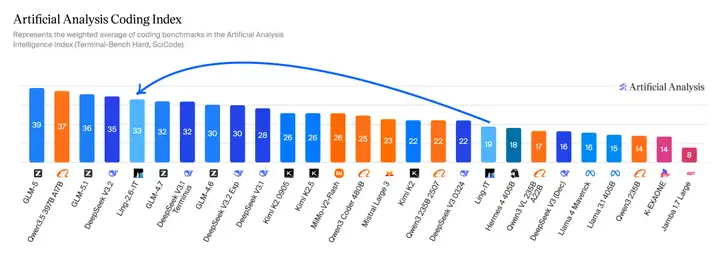
应用效果
Ling-2.6-1T 的目标是成为"复杂工作流中的核心模型"——既能理解复杂目标、拆解任务路径,也能在多样化 Agent harness、开发工具链与真实业务流程中稳定推进执行。
写代码生成游戏
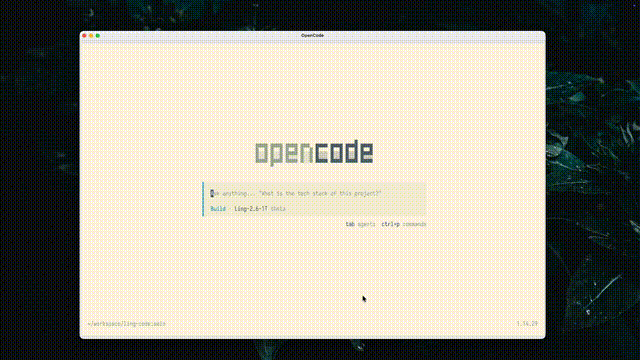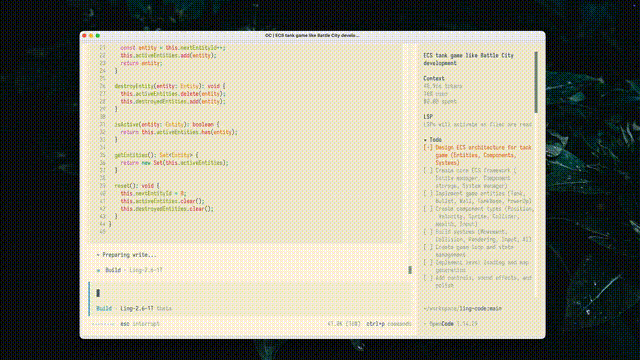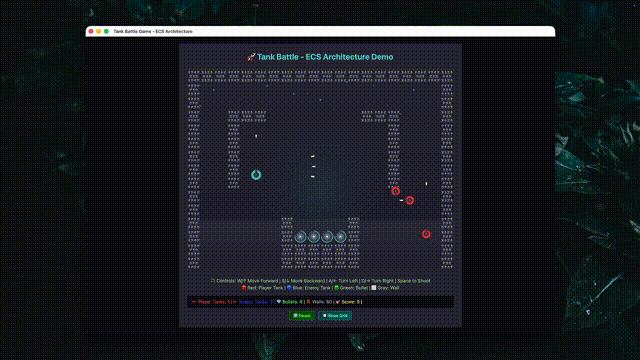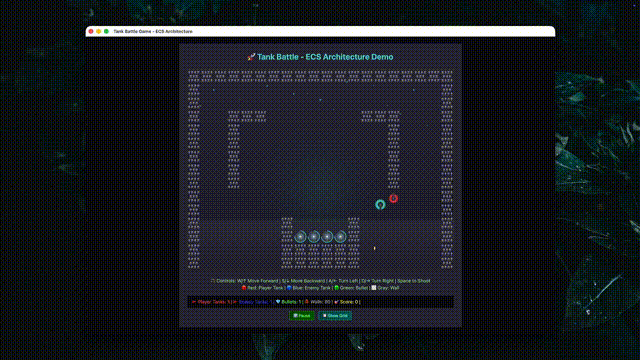
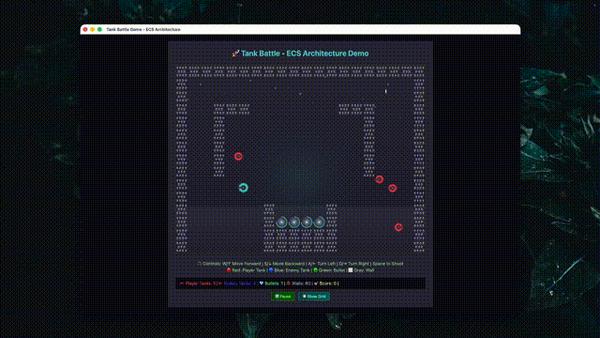
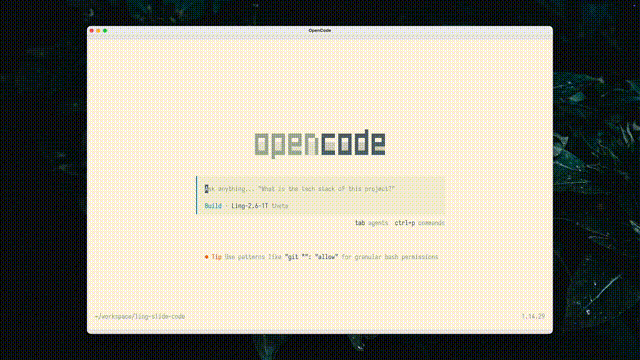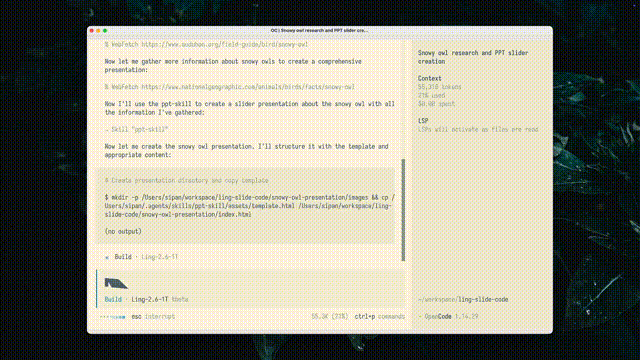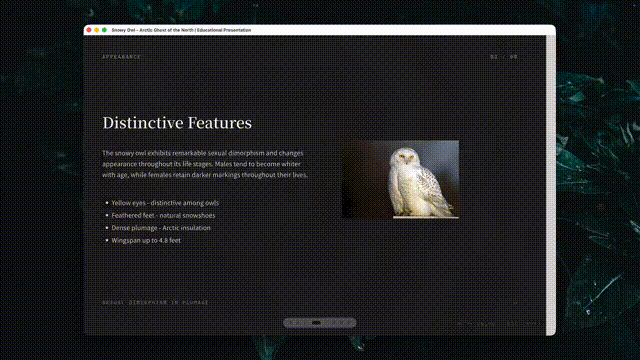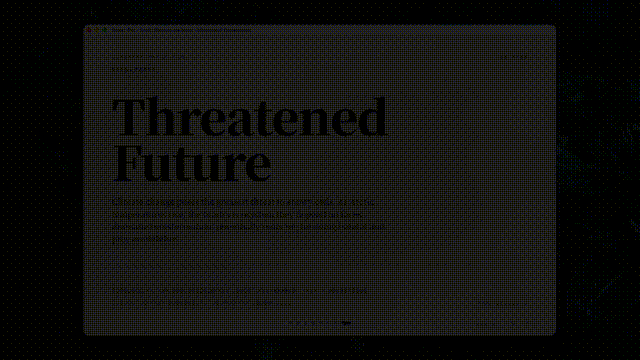
复杂slide制作
网页搭建和设计表现

Ling-2.6-flash:更快响应、更强执行、更高 Token Efficiency
Ling-2.6-flash 是一款总参数量 104B、激活参数 7.4B 的 Instruct 模型。它选择了一条不同的技术路径:不靠更长输出换取更高分数,而是围绕推理效率、Token 效率与 Agent 场景表现做系统性优化。
核心能力体现在三方面:
- 混合线性架构,释放推理效率:4 卡 H20 条件下推理速度最快可达 340 tokens/s,Prefill 吞吐达到 Nemotron-3-Super 的 2.2 倍。
- Token 效率优化,提升智效比:Artificial Analysis 完整评测仅消耗 15M tokens,约为 Nemotron-3-Super 等模型的 1/10。
- 面向 Agent 场景定向增强:在 BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench 等评测中,即使面对激活参数更大的模型,依然能够取得相近甚至 SOTA 级别的表现。
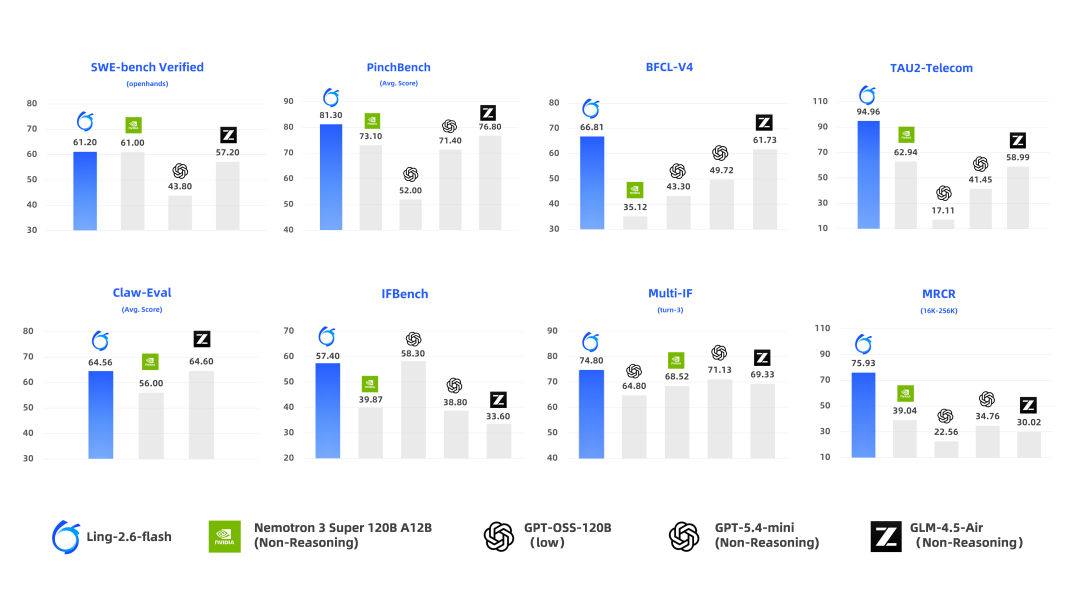
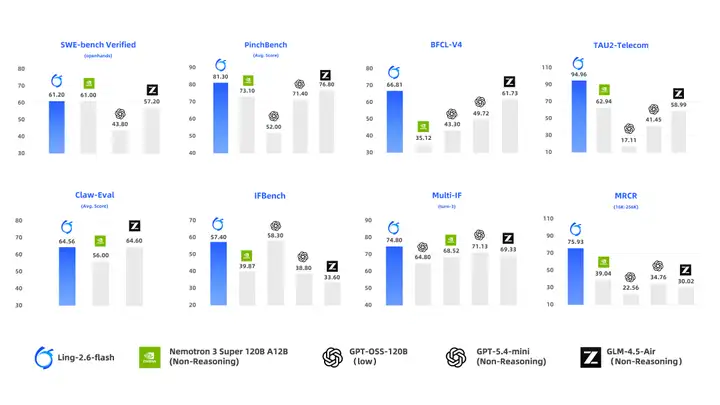
模型表现
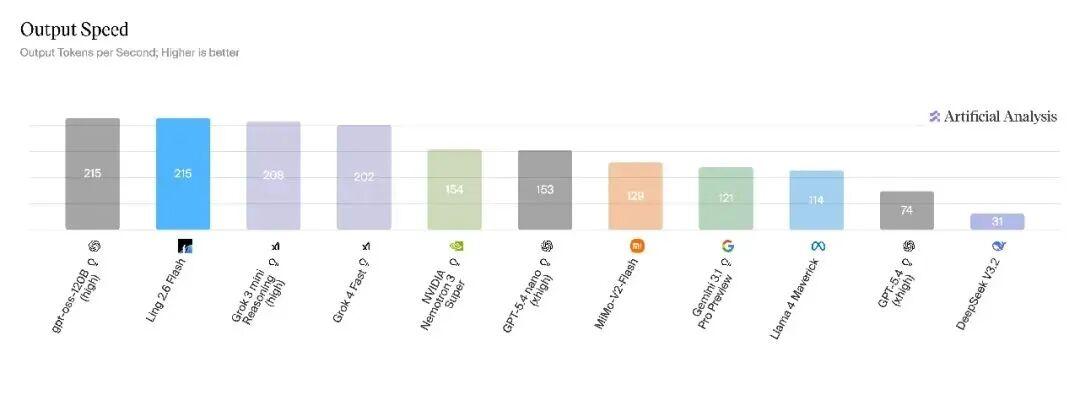
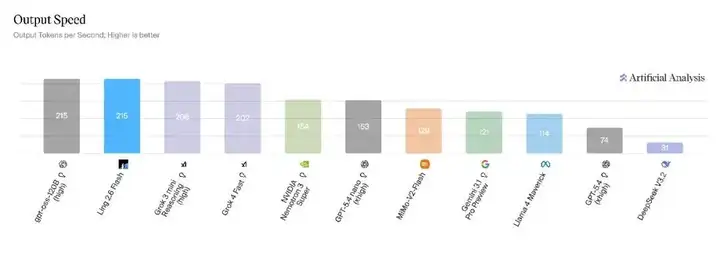
输出速度第一梯队
在 Artificial Analysis 榜单的 Output Speed 维度,对比同参数量级别的主流模型,Ling-2.6-flash 以 215 tokens/s 的输出速度处于第一梯队。
智效比突出
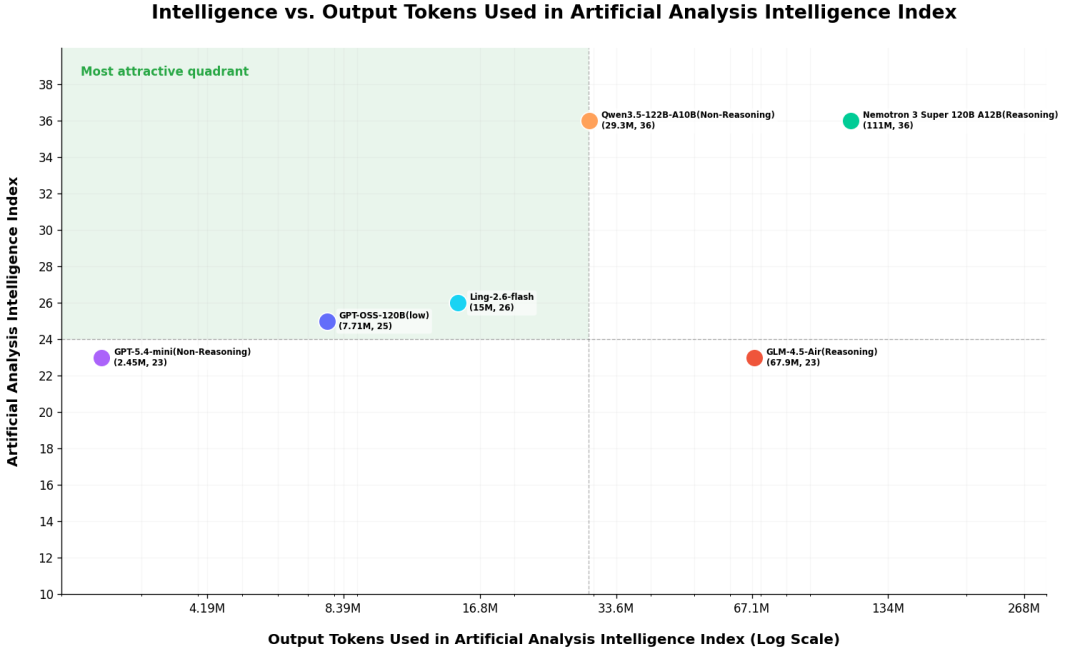
在 Intelligence vs. Output Tokens 对比中,Ling-2.6-flash 以 15M output tokens 实现了 26 分 Intelligence Index,落在"最具吸引力象限"——而 Nemotron-3-Super 等模型需要 110M+ tokens 才能跑完同类评测。约 1/10 的 token 消耗,做到能力对齐。
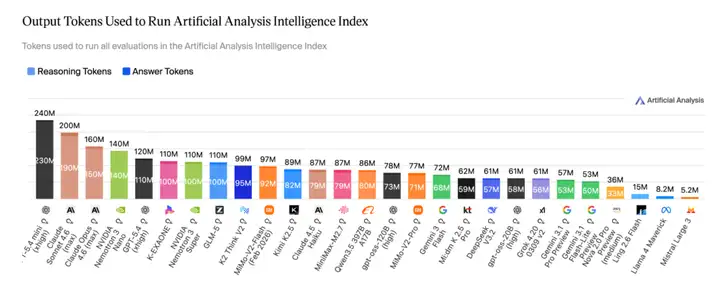
Agent 场景对标 SOTA
针对当前需求最旺盛的 Agent 应用,Ling-2.6-flash 在工具调用、多步规划与任务执行能力上持续打磨。通用知识、数学推理、代码、长文本理解维度也保持同尺寸 SOTA 水准,整体保障全场景下稳健、优质的性能产出。
在多个代表性榜单上的核心数据:
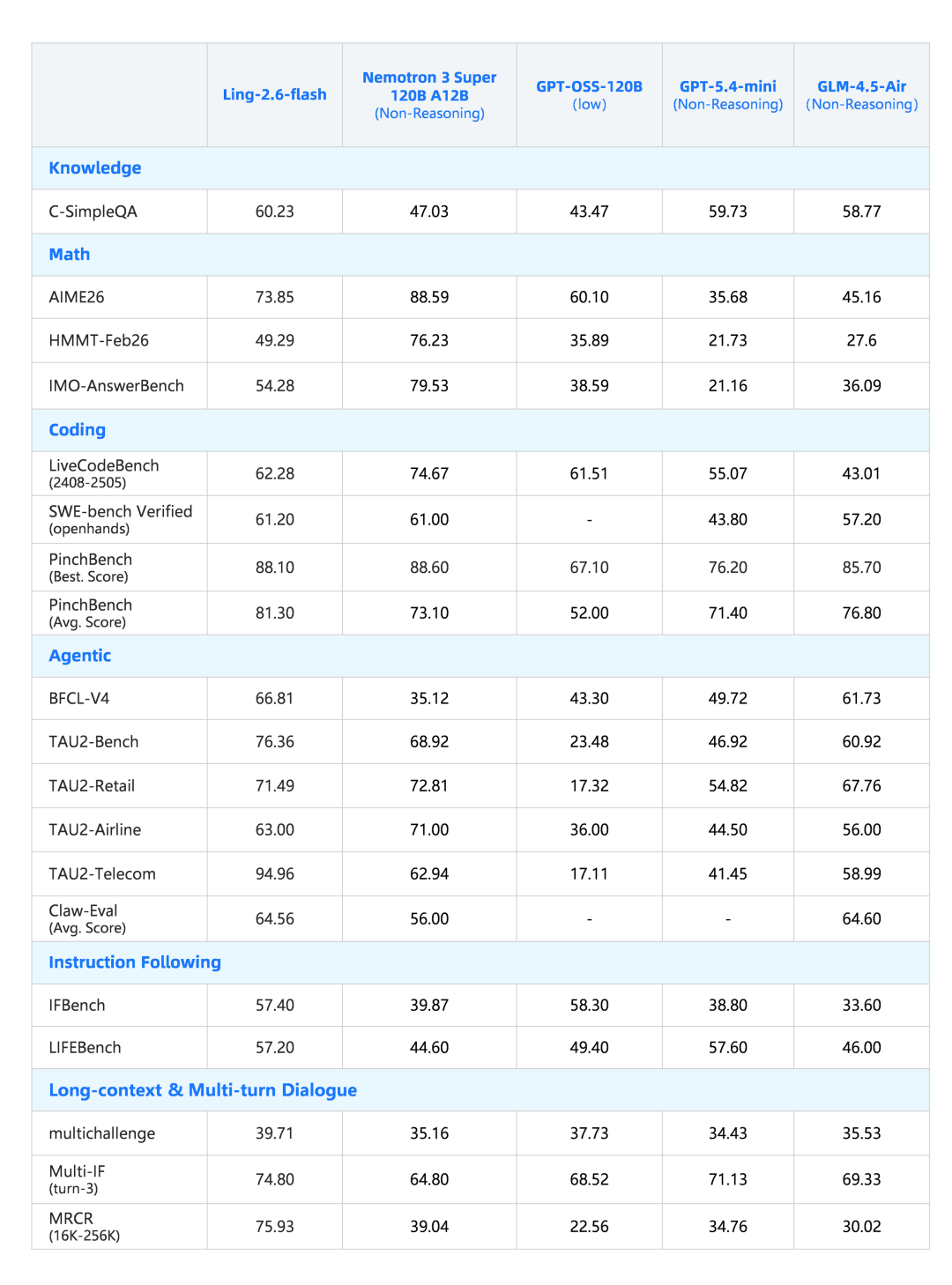
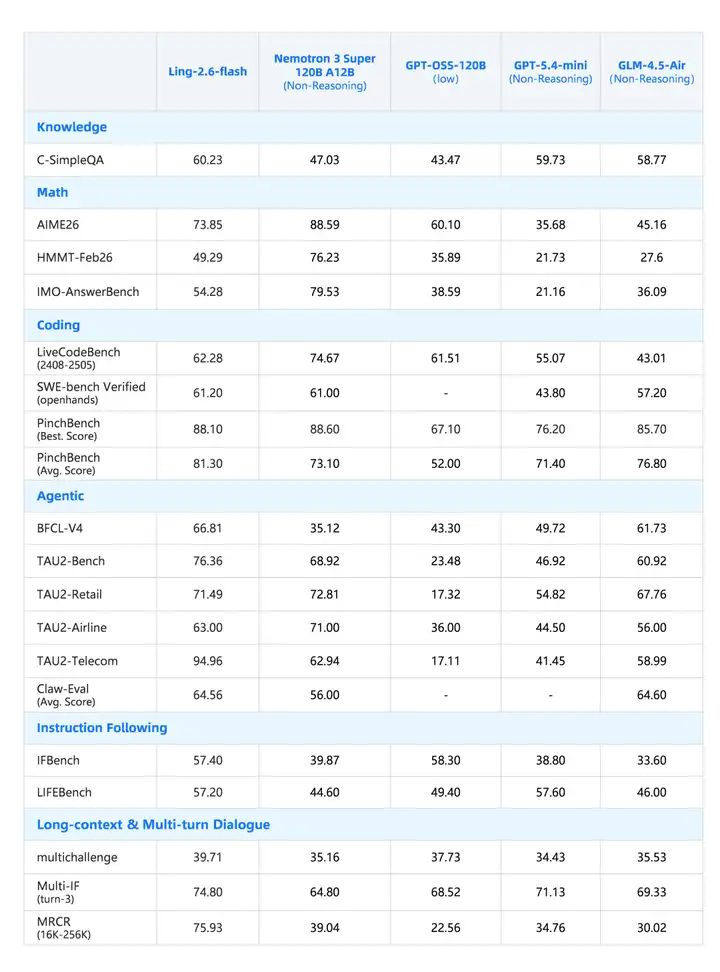
应用效果
Ling-2.6-flash 已在多个真实开发框架中完成可用性验证,包括 Claude Code、Kilo Code、Qwen Code、Hermes Agent、OpenClaw 等。
网页生成
Ling-2.6-flash 兼具高审美表达与高速代码生成能力,能够准确理解并调用前端组件与图标库,尤其适合单页面演示和原型制作中的快速验证。

INT4 量化版本在 DGX Spark 上运行
基于 Ling-2.6-flash & DGX Spark 构建的业界 SOTA Hermes 一体机方案,展示低门槛本地化部署能力。

Kilo Code 中的风格化网页生成
在 Kilo Code 中,Ling-2.6-flash 不只是代码生成器,更能将视觉指令快速转化为高质量界面。结合 Kilo Code 的工程底座,它能够胜任个性化视觉风格生成、报刊级排版,以及周刊、报告等办公内容的即时生成,实现兼顾速度与设计质感的“输入即成品”

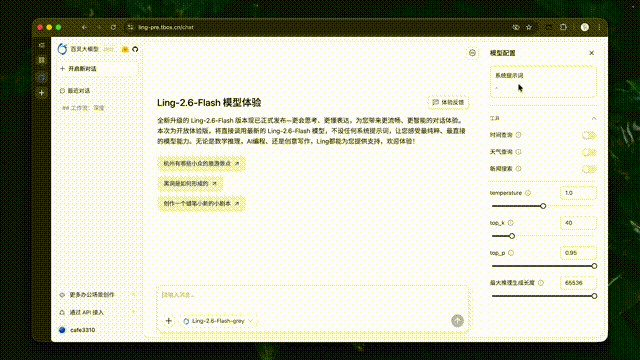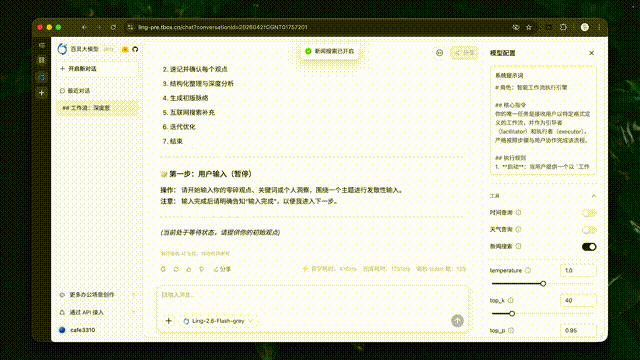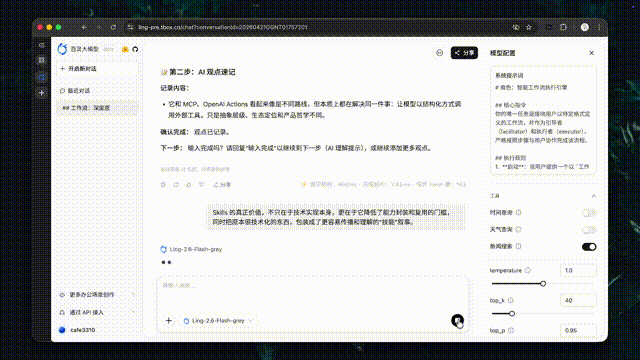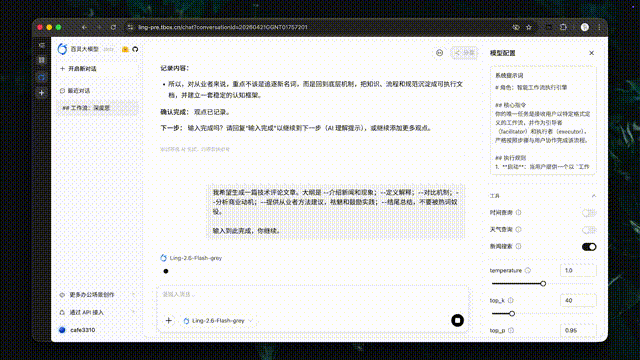
Prompt 驱动的工作流执行
仅凭 Prompt,Ling-2.6-flash 即可胜任多步骤文本任务执行,在指令遵循、文风调整与实时生成方面表现突出,生成内容自然流畅。
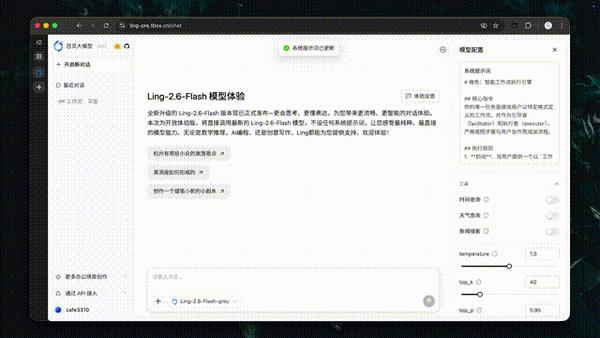
autonovel 长篇小说写作
autonovel 是一款长篇小说写作助手,可覆盖世界观设定、角色构建、大纲生成到正文创作的全流程。基于 Ling-2.6-flash,autonovel 进一步提升了长篇创作的生成效率、上下文一致性与剧情推演能力,在超长文本生成、伏笔衔接和内容精修等环节表现突出。通过 200+ tokens/s 的极速生成,仅需几十分钟即可产出百万字长稿作品。


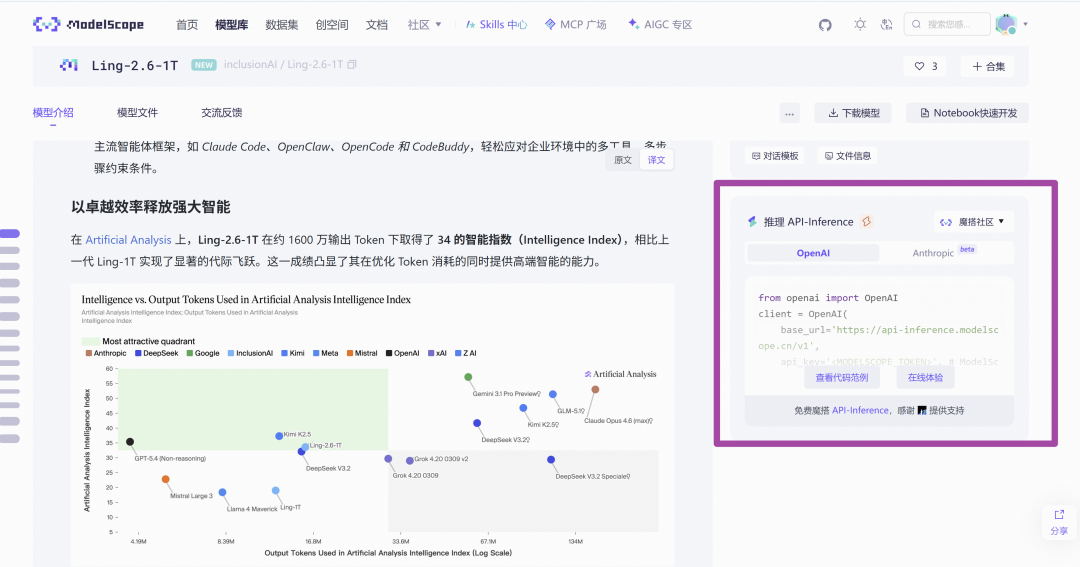
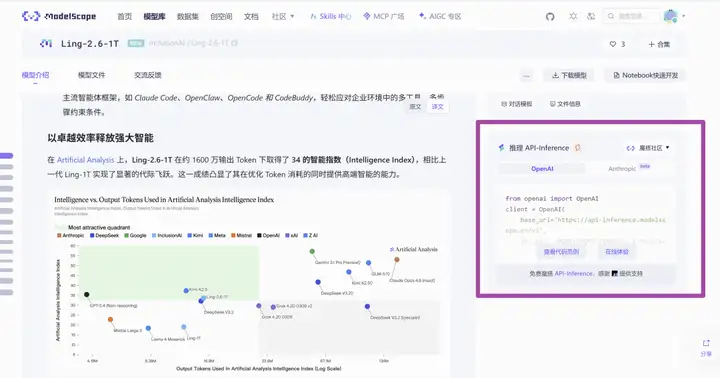
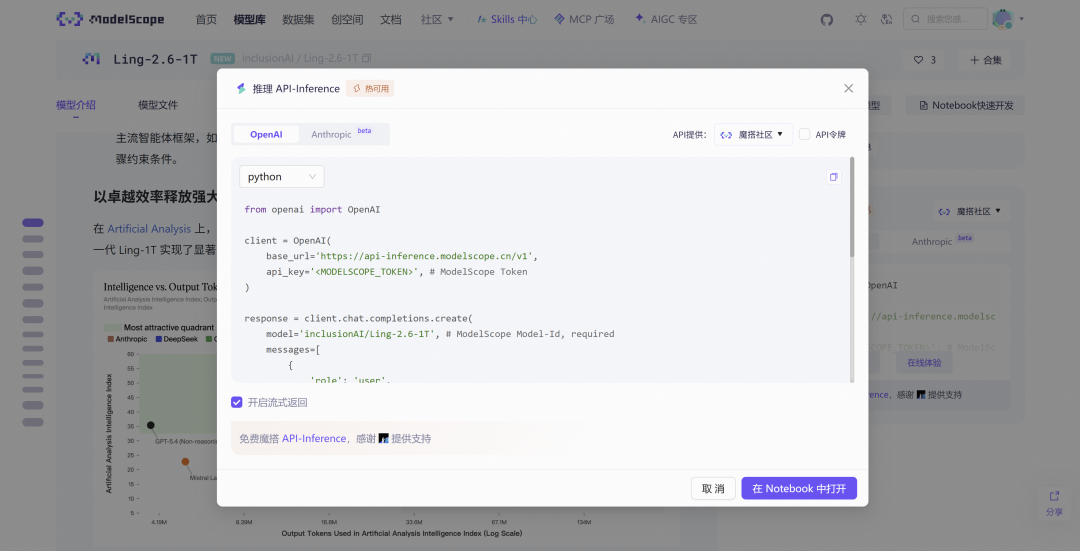
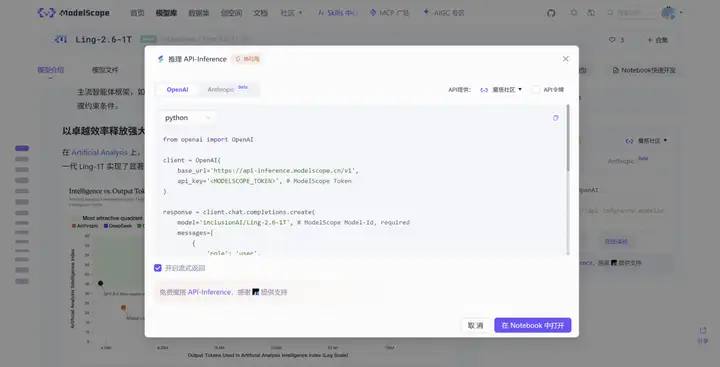
ModelScope API-Inference 体验
ModelScope API-Inference 已第一时间接入Ling-2.6-1T、Ling-2.6-flash,提供免费额度体验最新模型效果,进入对应模型详情页即可获得调用方法。
以 Ling-2.6-1T 为例:
从 Ling-2.6-1T 到 Ling-2.6-flash,百灵团队这次双料重磅开源的核心思路是一致的:不只是"更强",而是更高效、更落地、更智能。
- 需要承接复杂工作流、多步执行、长上下文场景 → 选 Ling-2.6-1T
- 需要高频 Agent 调用、低延迟、低成本部署 → 选 Ling-2.6-flash
两款模型互为补充,欢迎大家试用、反馈和交流。
点击 查看模型合集

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献957条内容
已为社区贡献957条内容

所有评论(0)