
从成功率到能力画像:上海AI Lab推出具身操作仿真评测基座EBench
对于具身操作模型而言,评测的价值正在从“分数排序”转向“能力测量”。如何更细粒度地理解模型的能力构成,并更可靠地评估其在分布外任务中的真实表现,正在成为 benchmark 设计中的关键问题。
近日,上海 AI Lab 物理智能中心推出 EBench。该 Benchmark 不再将单一排行榜作为主要目标,而是希望围绕“能力解析”与“真实泛化”,建立一套可复现、可拆解、可比较的评测体系。
目前,EBench 共包含 26 种任务,并从场景(Scene)、原子技能(Atomic Skill)、时长(Horizon)、精度(Precision)和操作模式(Operating Mode)五个维度进行任务标注;同时覆盖物体泛化(Object)、背景泛化(Background)、指令泛化(Instruction)和组合扰动(Mixed perturbation)四类泛化维度,共构建 794 条测试任务,用于支撑更细粒度的能力诊断与泛化评估。


相关链接:
- 项目开源地址:https://github.com/InternRobotics/EBench
- 评测集地址:https://modelscope.cn/datasets/InternRobotics/EBench-Dataset
- 在线仿真评测平台:https://internrobotics.shlab.org.cn/eval
问题
具身操作评测,不能只看一个成功率
当前具身操作 benchmark 面临的核心问题,不是缺少任务,而是缺少对模型能力的有效刻画。
真机评测虽然更接近真实应用,但成本高、复现难,难以支撑大规模标准化比较;仿真评测虽然具备可重复性,但很多仍主要输出成功率或任务总分,只能回答“任务是否完成”,却难以解释“模型为什么成功”或“为什么失败”。
这会带来一个典型问题:当模型分数提升时,研究者往往难以判断,这种提升究竟来自长程任务能力增强、场景迁移能力改善、操作精度提高,还是仅仅来自对高频任务配置的适配。
进一步地,当验证与测试边界不够清晰时,benchmark还可能逐渐退化为调参目标。模型通过反复刷榜和针对性优化获得更高分数,但这种提升并不一定等同于真实泛化能力的提升。
EBench 希望解决的,正是这一问题。
它的目标不是再做一个新的分数榜,而是建立一套能够支撑能力分析的评测框架,使 benchmark 从“结果展示工具”转向“模型诊断工具”。它关注的不只是“谁的分更高”,而是模型的得分来自哪类能力,这些能力是否稳定,以及它们能否迁移到分布外任务中。
任务方法
不止于“抓与放”的多样化具身操作任务集
要让评测真正反映模型能力,首先需要让任务本身足够接近真实操作场景。真实环境中的机器人操作,很少只是单一桌面上的“抓取—放置”,而往往同时涉及空间理解、精细控制、长程规划,以及机械臂、双手和移动底盘之间的协同。
因此,EBench 在任务设计上突破了传统“抓取—放置”循环,覆盖单步抓放、精细装配、移动操作和长程协同等多种任务形态。
在空间上,任务从二维桌面扩展到具有高度、纵深和层级关系的三维环境;在精度上,从“能放下”进一步走向“能对齐、能调准”;在时序上,从单步动作扩展到多步骤规划与中途纠错;在执行主体上,也从单机械臂延伸到双手协同与移动底盘协同。
这些任务将抓取(Grasp)、放置(Place)、插装(Insert)、倒入(Pour)、翻面(Flip)、推扫(Sweep)、递交(Handover)等动作原语融入真实操作语义中,并为每个任务标注场景、原子技能、任务时长、操作精度和操作模式五个维度,使 EBench 不只记录“做没做成”,也能进一步分析模型到底强在哪、弱在哪。
配合验证集与测试集隔离,以及物体、背景、指令、组合四类泛化测试,EBench 关注的不是固定任务上的记忆表现,而是模型在分布变化下仍能稳定完成操作的真实能力。

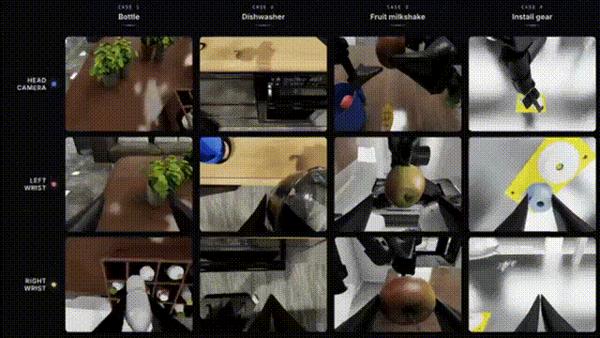
方法
用五维标签拆解能力,用训测隔离检验泛化
有了覆盖多样操作形态的任务集之后,下一步是让每条任务都能被结构化分析。
要理解一个具身模型为什么成功,首先需要知道任务本身由哪些能力要素构成。
为此,EBench 为每条任务建立五维标签体系,将任务结果重新映射到能力因子上,而不再停留在单一成功率层面。
其中,场景维度用于分析模型在不同视觉环境中的适应能力;原子技能维度用于拆解模型在不同基础操作技能上的表现;任务时长维度用于刻画任务长度,帮助区分短程任务与长程任务中的能力差异;操作精度维度用于分析模型在不同精度要求下的表现,判断其是否具备更精细的控制能力;操作模式维度则用于区分灵巧操作与移动操作,观察模型在不同操作形态下的表现差异。
但仅仅拆开能力维度还不够。Benchmark 还必须尽可能保证测到的是模型的泛化能力,而不是对固定测试配置的持续适配。
因此,EBench 采用验证集—测试集分离机制。验证集用于日常调参与快速迭代;小规模隔离测试集(Test)则用于在分布外任务中考察模型面对新物体、新背景、新指令和组合变化时的真实适应能力。
在此基础上,EBench 进一步设计了物体泛化、背景泛化、指令泛化和组合扰动四类泛化测试。通过相对受控的变量设置,评测结果可以更具体地反映模型在哪类泛化因素上出现波动,而不是停留在“换了测试集以后分数下降”的模糊结论。
考虑到当前模型能力范围并不完全一致,EBench还提供 Specialist 与 Generalist 双轨评测入口。前者支持灵巧操作(Dexterous)或移动操作(Mobile Manip)方向的专项评测,后者则面向同时具备两类能力的模型进行统一测试,以兼顾专项能力分析与通用能力比较。
方法
让评测进入模型研发的日常流程
对于具身操作模型而言,评测本身也是高成本环节:链路长、资源重、反馈慢。如果评测效率过低,再精细的标签体系也难以真正进入研发流程。
因此,EBench 在评测基础设施上也进行了专门设计。
一方面,Benchmark 开源了分布式评测工具,支持本地高吞吐验证。在 8 卡 4090 配置下,约 30 分钟即可完成验证集评测,便于快速回归测试与日常迭代。
另一方面,平台还提供 7×24 小时在线评测服务。用户无需自行搭建完整环境,即可在统一协议下发起标准化测试。
这种“本地验证 + 在线评测”的组合,一方面缩短了实验反馈周期,使benchmark 能够更好地服务模型开发;另一方面也通过统一协议与远程执行环境,提高了评测的公平性与可复现性。
换句话说,评测在这里不再只是阶段性的结果展示工具,而是能够进入训练、调参与回归测试过程中的日常反馈系统。
结果
总分相近,不代表能力结构相同
目前,EBench 已在 π0、π0.5、XVLA、InternVLA-A1 等代表性模型上完成首轮验证。
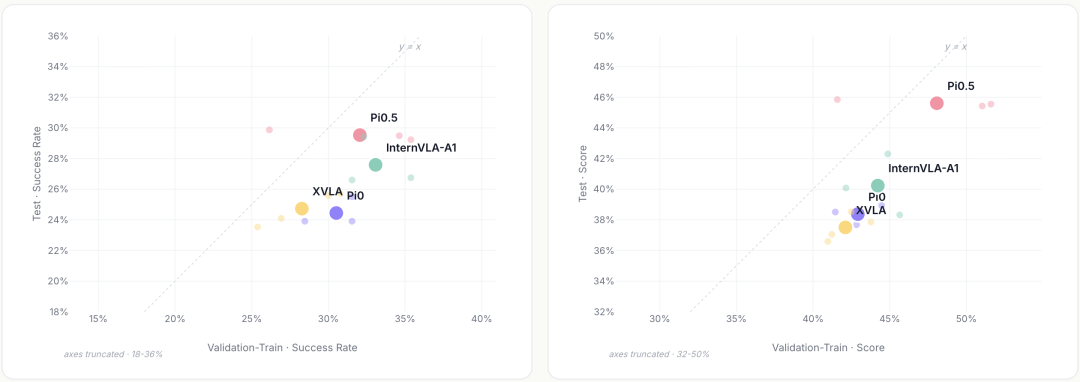
代表性模型在 Validation-Train 与 Test 上的表现对比,左图为 Success Rate,右图为 Score
从隔离测试集(Test)的结果来看,模型在操作模式、操作精度、任务时长等维度上呈现出不同分布。InternVLA-A1 在移动操作上表现领先,但在灵巧操作上下降明显;π0 则相对更加均衡。操作精度维度也呈现出类似分化:在低精度任务中,不同模型差距不大,但进入高精度操作后,π0 仍能保持相对领先,而 XVLA 与 π0.5 的表现下降明显。
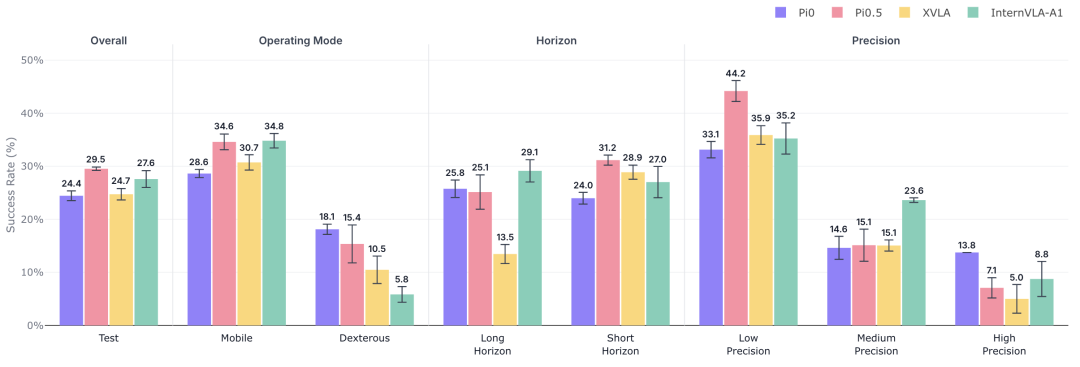
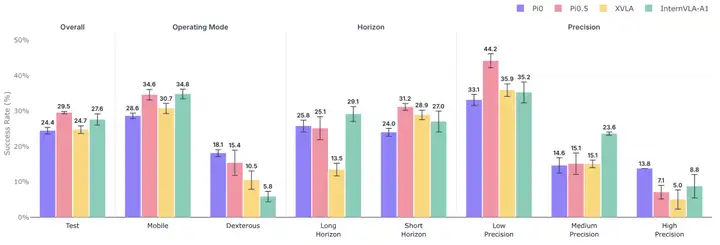
不同模型在整体表现及细分维度上的结果对比
原子技能结果进一步说明,不同模型之间存在一定互补性。π0 在拉(Pull)这一技能上优势明显;XVLA 则在推(Push)的任务中表现较好,但在交接 / 递送(Handover)任务上相对较弱。
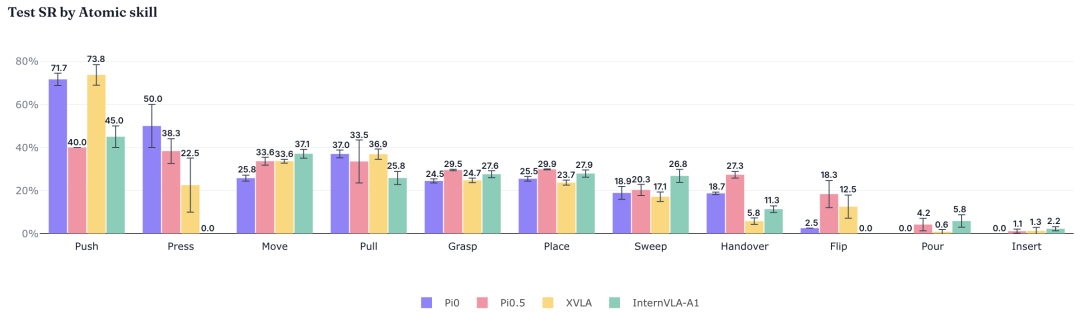
不同模型在原子技能维度上的成功率对比
泛化测试显示,背景变化和指令变化相对容易适应;一旦引入新物体,成功率便会明显下滑;当多个泛化因素同时变化,也就是进入组合扰动(Mixed perturbation)场景时,模型表现会进一步下降。整体来看,物体泛化(Object)和组合扰动(Mixed perturbation)是当前模型更容易失守的两个环节。
在背景、物体、组合3个泛化维度上,π0.5均优于其他模型,其中背景和前景物体泛化维度的优势最为明显。这也在一定程度上解释了社区普遍对于π0.5预训练“好用”的体验——模型经过后训练微调仍具有较好的泛化性。
此外这也说明了,对于具身操作模型而言,单一总分并不足以支撑全面判断。相比简单回答“谁更高分”,EBench 更希望回答的是:模型的分数来自哪类能力,这种能力是否稳定,以及它能否迁移到分布外任务中。
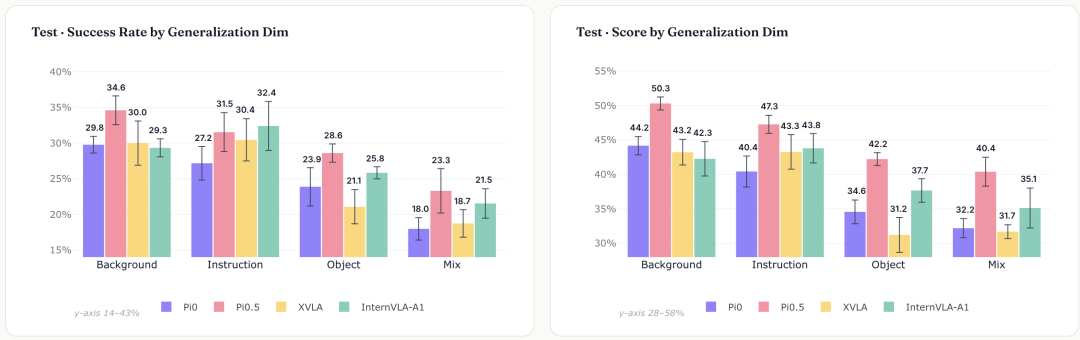
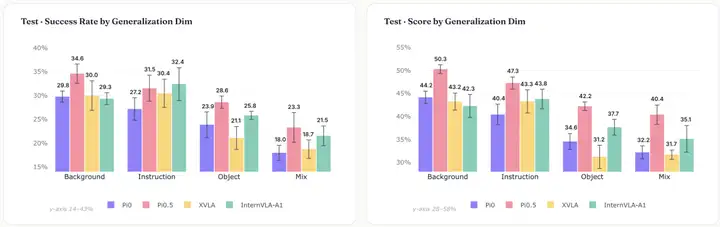
不同模型在四类泛化维度上的表现对比。左图为Success Rate,右图为 Score

(欢迎扫码加入用户交流群)
欢迎访问在线仿真评测平台
具身智能评测平台:https://internrobotics.shlab.org.cn/eval
直达评测集详情https://modelscope.cn/datasets/InternRobotics/EBench-Dataset

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献959条内容
已为社区贡献959条内容

所有评论(0)