
Qwen3.5 中等规模模型系列正式开源:更强智能,更低算力
更好的架构、更高质量的数据、更大规模的强化学习,才是推动智能进步的真正引擎。
🚀 一句话读懂 Qwen3.5
今天,Qwen团队正式发布 Qwen3.5 中等规模模型系列,包含四款各有侧重的模型:
| 模型 | 定位 |
| Qwen3.5-Flash | 生产级托管版,对应 35B-A3B,默认 100 万上下文 |
| Qwen3.5-35B-A3B | 小体积,超强能力,已超越 Qwen3-235B-A22B |
| Qwen3.5-122B-A10B | 旗舰开源版,对标前沿模型 |
| Qwen3.5-27B | 均衡型,在复杂 Agent 场景表现出色 |
所有模型均支持视觉-语言多模态输入,原生上下文长度 256K tokens,最高可扩展至 1M tokens
模型链接:https://modelscope.cn/collections/Qwen/Qwen35
✨ 四大技术亮点
1. 统一视觉语言基础(Unified Vision-Language Foundation)
Qwen3.5 采用早期融合训练(Early Fusion),将视觉 token 和文本 token 统一训练,不再是"文字模型 + 外挂视觉模块"的拼接方案。在推理、编程、Agent 任务和视觉理解等基准测试上,整体性能对齐甚至超越上一代专门的视觉模型 Qwen3-VL。
2. 高效混合架构(Gated Delta Network + MoE)
Qwen3.5 引入 Gated Delta Networks 与稀疏 Mixture-of-Experts(MoE) 的组合架构。以 35B-A3B 为例,总参数量 350 亿,每次推理仅激活约 30 亿参数,实现了高吞吐、低延迟、低成本的三重平衡——这正是"用中等规模做出旗舰效果"的核心秘密。
3. 百万 Agent 规模的强化学习
训练过程中,RL 框架在数百万个 Agent 环境中并行运行,通过递进式任务分布持续提升模型的真实世界泛化能力,使模型在复杂多步 Agent 任务中的鲁棒性大幅提升。
4. 201 种语言覆盖
Qwen3.5 将多语言支持扩展至 201 种语言与方言,包含对中文、粤语等多种方言的细粒度理解能力。
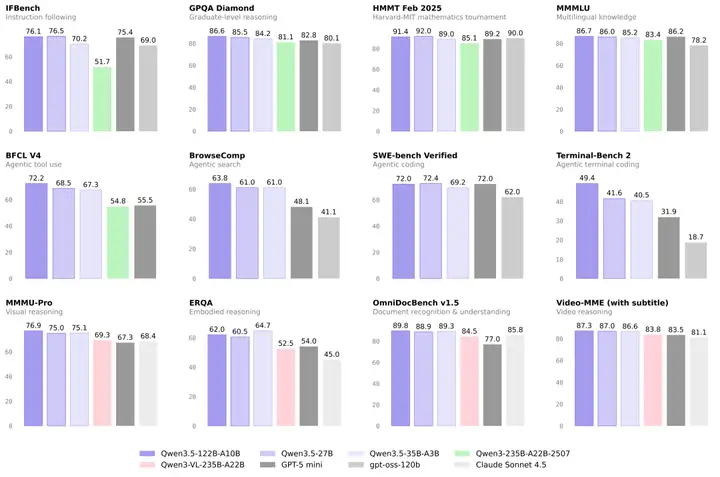
📊 基准测试:小模型,大成绩
Qwen3.5-35B-A3B 在知识(MMLU-Pro: 85.3)、指令跟随(IFEval: 91.9)、数学推理(MATH-500: 97.6)等核心榜单上,已全面超越参数量是其 6 倍以上的旧版旗舰模型 Qwen3-235B-A22B,印证了"更少激活参数 + 更好架构 + 更充分训练 > 单纯堆参数"的技术路线。
Qwen3.5-122B-A10B 在 MMLU-Pro(86.7)、C-Eval(91.9)等知识类任务上进一步刷新记录,在复杂 Agent 场景中与顶级前沿模型的差距持续缩小。
🛠️ 最佳实践
一、选择合适的推理模式
Qwen3.5 支持两种模式:思考模式(Thinking Mode) 适用于需要深度推理的任务;指令模式(Instruct Mode) 适用于直接对话和快速响应。
推荐采样参数配置:
- 思考模式(通用任务):
temperature=1.0, top_p=0.95, top_k=20, presence_penalty=1.5 - 思考模式(精确编码任务,如 Web 开发):
temperature=0.6, top_p=0.95, top_k=20 - 指令模式(通用任务):
temperature=0.7, top_p=0.8, top_k=20, presence_penalty=1.5 - 指令模式(推理任务):
temperature=1.0, top_p=1.0, top_k=40, presence_penalty=2.0
💡 presence_penalty 在 0~2 之间调整可有效减少重复输出,但过高时可能引发语言混淆,请按需调节。
二、合理设置输出长度
- 常规任务:建议
max_tokens=32768 - 数学竞赛、复杂编程题等高难度任务:建议设置为
81920,给模型留出充分的推理空间
三、标准化输出格式
在 Prompt 中明确要求格式,可显著提升输出质量:
- 数学题:在 Prompt 末尾加入
"请逐步推理,并将最终答案写在 \boxed{} 内。" - 选择题:要求模型用 JSON 格式仅输出选项字母,例如
{"answer": "C"}
四、多轮对话的历史管理
在多轮对话中,历史消息只保留最终输出,不需要包含思考过程(thinking content)。这一点在直接使用 Jinja2 模板时已自动处理,使用第三方框架时需开发者手动确认是否正确过滤。
五、本地部署:SGLang / vLLM 推理服务
Qwen3.5 兼容 SGLang、vLLM、KTransformers、Hugging Face Transformers 等主流推理框架。生产环境或高并发场景强烈推荐 SGLang 或 vLLM。
⚠️ 注意:模型默认上下文长度 262,144 tokens,若遇到 OOM,可适当降低;但建议保持至少 128K 以确保思考能力完整。
SGLang(推荐)
先安装最新版 SGLang:
uv pip install 'git+https://github.com/sgl-project/sglang.git#subdirectory=python&egg=sglang[all]'
标准启动(8 卡 TP 并行):
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-122B-A10B \
--port 8000 --tp-size 8 \
--mem-fraction-static 0.8 \
--context-length 262144 \
--reasoning-parser qwen3
开启工具调用(Tool Use):
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-122B-A10B \
--port 8000 --tp-size 8 \
--mem-fraction-static 0.8 \
--context-length 262144 \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder
开启多 Token 预测(MTP 加速推理):
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-122B-A10B \
--port 8000 --tp-size 8 \
--mem-fraction-static 0.8 \
--context-length 262144 \
--reasoning-parser qwen3 \
--speculative-algo NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4vLLM
先安装最新版 vLLM:
uv pip install vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
标准启动(8 卡 TP 并行):
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-122B-A10B \
--port 8000 --tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3
开启工具调用:
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-122B-A10B \
--port 8000 --tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
仅文本模式(节省显存给 KV Cache):
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-122B-A10B \
--port 8000 --tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only服务启动后,两者均在 http://localhost:8000/v1 提供 OpenAI 兼容 API,可直接接入任何支持 OpenAI 格式的客户端。
六、调用 API:OpenAI SDK 示例
配置环境变量后,即可用标准 OpenAI Python SDK 调用:
pip install -U openai
export OPENAI_BASE_URL="http://localhost:8000/v1"
export OPENAI_API_KEY="EMPTY"
文本对话(思考模式):
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="Qwen/Qwen3.5-122B-A10B",
messages=[{"role": "user", "content": "用一句话解释相对论"}],
max_tokens=81920,
temperature=1.0,
top_p=0.95,
presence_penalty=1.5,
extra_body={"top_k": 20},
)
print(response.choices[0].message.content)
关闭思考模式(直接回答):
response = client.chat.completions.create(
model="Qwen/Qwen3.5-122B-A10B",
messages=[{"role": "user", "content": "今天天气怎么样?"}],
max_tokens=32768,
temperature=0.7,
top_p=0.8,
presence_penalty=1.5,
extra_body={
"top_k": 20,
"chat_template_kwargs": {"enable_thinking": False},
},
)💡 注意:Qwen3.5 不支持 Qwen3 的软切换指令(/think 和 /nothink),需通过 API 参数显式控制。
图片输入:
response = client.chat.completions.create(
model="Qwen/Qwen3.5-122B-A10B",
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "https://your-image-url.jpg"}},
{"type": "text", "text": "请描述这张图片"},
]
}],
max_tokens=81920,
temperature=1.0,
top_p=0.95,
presence_penalty=1.5,
extra_body={"top_k": 20},
)七、超长文本处理(百万 Token)
原生支持 262,144 tokens。如需处理更长内容(如长视频、超长文档),可通过 YaRN 扩展至约 100 万 tokens。
SGLang 超长上下文启动:
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-122B-A10B \
--json-model-override-args '{"text_config": {"rope_parameters": {"rope_type": "yarn", "factor": 4.0, "original_max_position_embeddings": 262144}}}' \
--context-length 1010000
vLLM 超长上下文启动:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3.5-122B-A10B \
--hf-overrides '{"text_config": {"rope_parameters": {"rope_type": "yarn", "factor": 4.0, "original_max_position_embeddings": 262144}}}' \
--max-model-len 1010000⚠️ factor 参数建议按实际场景调整:若常用长度约为 52 万 tokens,将 factor 设为 2.0 比 4.0 效果更佳。
八、长视频理解
为获得更高帧率采样和更优的小时级视频理解效果,建议在 video_preprocessor_config.json 中将 longest_edge 设置为 469762048(对应约 22.4 万视频 tokens)。
🔗 API Inference 快速体验
魔搭社区的API Inference已经支持Qwen3.5最新的模型的推理API接口,示例代码如下:
from openai import OpenAI
client = OpenAI(
base_url='https://api-inference.modelscope.cn/v1',
api_key='<MODELSCOPE_TOKEN>', # ModelScope Token
)
response = client.chat.completions.create(
model='Qwen/Qwen3.5-35B-A3B', # ModelScope Model-Id, required
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': '描述这幅图',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/audrey_hepburn.jpg',
},
}],
}],
stream=True
)
for chunk in response:
if chunk.choices:
print(chunk.choices[0].delta.content, end='', flush=True)
🔗 MS-Swift微调
ms-swift已支持Qwen3.5系列模型的训练。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:https://github.com/modelscope/ms-swift
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
pip install "transformers>=5.2.0"
下面展示可运行的微调demo,并给出自定义数据集的格式。(训练时指定--dataset xxx.jsonl即可)
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "/xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<image>图片中是什么,<video>视频中是什么"}, {"role": "assistant", "content": "图片中是一个大象,视频中是一只小狗在草地上奔跑"}], "images": ["/xxx/x.jpg"], "videos": ["/xxx/x.mp4"]}
使用transformers训练:
# 4 * 30GiB
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=4 \
MAX_PIXELS=1003520 \
VIDEO_MAX_PIXELS=50176 \
FPS_MAX_FRAMES=12 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model Qwen/Qwen3.5-35B-A3B \
--tuner_type lora \
--dataset 'AI-ModelScope/LaTeX_OCR:human_handwrite#2000' \
--load_from_cache_file true \
--add_non_thinking_prefix true \
--split_dataset_ratio 0.01 \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--experts_impl grouped_mm \
--router_aux_loss_coef 1e-3 \
--gradient_accumulation_steps 1 \
--group_by_length true \
--output_dir output/Qwen3.5-35B-A3B \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero3
# 训练后对验证集推理
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
MAX_PIXELS=1003520 \
VIDEO_MAX_PIXELS=50176 \
FPS_MAX_FRAMES=12 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--experts_impl grouped_mm \
--enable_thinking false \
--load_data_args true
使用megatron训练:
# 4 * 40GiB
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
MAX_PIXELS=1003520 \
VIDEO_MAX_PIXELS=50176 \
FPS_MAX_FRAMES=12 \
megatron sft \
--model Qwen/Qwen3.5-35B-A3B \
--save_safetensors true \
--merge_lora true \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
'AI-ModelScope/LaTeX_OCR:human_handwrite#2000' \
--load_from_cache_file true \
--add_non_thinking_prefix true \
--split_dataset_ratio 0.01 \
--tuner_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--expert_model_parallel_size 4 \
--moe_permute_fusion true \
--moe_grouped_gemm true \
--moe_shared_expert_overlap true \
--moe_aux_loss_coeff 1e-6 \
--micro_batch_size 4 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 1 \
--num_train_epochs 1 \
--group_by_length true \
--finetune true \
--freeze_llm false \
--freeze_vit true \
--freeze_aligner true \
--cross_entropy_loss_fusion true \
--lr 1e-4 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-5 \
--output_dir megatron_output/Qwen3.5-35B-A3B \
--eval_steps 200 \
--save_steps 200 \
--max_length 2048 \
--dataloader_num_workers 8 \
--dataset_num_proc 8 \
--no_save_optim true \
--no_save_rng true \
--sequence_parallel true \
--attention_backend unfused \
--padding_free false \
--model_author swift \
--model_name swift-robot
# 训练后对验证集推理
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
MAX_PIXELS=1003520 \
VIDEO_MAX_PIXELS=50176 \
FPS_MAX_FRAMES=12 \
swift infer \
--model megatron_output/vx-xxx/checkpoint-xxx-merged \
--stream true \
--experts_impl grouped_mm \
--enable_thinking false \
--load_data_args true
Qwen3.5 系列给行业传递了一个清晰的信号:在架构创新、数据质量和强化学习规模上下功夫,效果可以超越单纯增大参数规模的旧范式。对于资源有限的团队和开发者来说,35B-A3B(仅激活 3B 参数)以极低的推理成本达到旗舰级性能,是当前部署性价比最高的选择之一。
点击即可跳转模型链接
https://modelscope.cn/collections/Qwen/Qwen35
 魔搭社区176 搭子 · 113 讨论 圈子
魔搭社区176 搭子 · 113 讨论 圈子

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 1
1- 0



 已为社区贡献959条内容
已为社区贡献959条内容

所有评论(0)