
榜单不盲从:用 EvalScope 打造你的专属场景评测
大家一定非常熟悉这个场景:每当一个新的模型发布时,总会有一张张华丽的雷达图或条形图来展示其强大的性能。
这些图表中,我们经常都能看到那些耳熟能详的评测基准名字:
- MMLU:涵盖几十个学科,代表“通识教育”水平;
- AIME25:数学竞赛题,代表“数学推理”能力;
- LiveCodeBench:Python 代码生成,代表“编程能力”。
这些榜单就像是模型的“高考成绩单”,它们当然重要,因为它们确立了模型在不同领域里的基准智力水平(SOTA)。但问题在于,能在不同学科考出高分的模型,是否就能胜任实际的“岗位工作”?在模型使用的过程中,可能很多人都会遇到过类似这样的困惑:
“明明这个模型在 MMLU、C-Eval 上分数很高,为什么一放到我的 RAG 应用里,幻觉满天飞?”
“榜单第一的模型,写代码经常无法运行,反而是那个榜单第五的模型更懂我的项目。”
这是因为公开榜单衡量的,往往是在不同领域中,相对通用的智力水平。而我们在模型实际用的过程中,更关注的是具体场景中的“业务价值”。本文集中介绍和讨论了,如何基于EvalScope的自定义评测指数(Evaluation Index),来构建在不同场景中,能反映和匹配“业务价值”的评测。
为什么需要自定义评测指数?
常见的大模型评测集(Benchmark)往往覆盖的是相对通用的场景。而在具体的垂直领域,往往需要一些定制化的衡量能力。正如 Artificial Analysis Intelligence Index 聚焦于模型通用智力,而 Vals Index 聚焦于模型商业价值一样,你也需要一把属于自己的尺子。
构建一个自定义评测指数(Evaluation Index)的价值在于:
- 业务对齐:将知识水平、长文本、指令遵循等等能力按实际业务占比加权,分数直接反映“业务可用性”。
- 一次跑测:不需要分别跑十几个数据集再手动算分,一次运行即可得到综合得分。
- 统一标准:为团队内部的模型迭代提供一个长期、稳定的“北极星指标”。
EvalScope 的 Collection 模块正是为此设计:它允许你定义一份Schema(能力地图),按权重组合多个数据集,最终生成一个可直接用于评测的混合数据集。
核心思路:从Schema到Index
构建指数的过程非常符合直觉,分为三步走:
- 定义 Schema:配置“我关心哪些数据集”以及“它们各占多少权重”。
- 采样 (Sample):根据权重,从海量数据中抽取出一个具有代表性的“混合测试集 (JSONL)”。
- 评测 (Eval):像评测普通数据集一样,对这个混合集进行打分,获得 Index 总分及分项得分。
下面我们以构建一个 “企业级 RAG 助手指数” 为例,带你从零上手。
在此之前,你需要安装EvalScope库,运行下面的代码:
pip install 'evalscope[app]' -U
实战:构建“企业级RAG助手指数”
假设你的业务是一个企业知识库助手,你最关心的能力维度如下:
- 模型的知识和幻觉水平(核心能力,权重 30%)
- 长文档检索与理解(核心能力,权重 30%)
- 严格遵循格式指令(交互体验,权重 40%)
第一步:定义 Schema
你需要创建一个 CollectionSchema,在其中列出选用的数据集及其权重。
from evalscope.collections import CollectionSchema, DatasetInfo
# 定义 RAG 业务指数的 Schema
rag_schema = CollectionSchema(
name='rag_assist_index', # 指数名称
datasets=[
# 1. 知识问答能力,幻觉 (30%)
DatasetInfo(
name='chinese_simpleqa',
weight=0.3,
task_type='knowledge',
tags=['rag', 'zh']
),
# 2. 长文本检索能力 (30%)
DatasetInfo(
name='aa_lcr',
weight=0.3,
task_type='long_context',
tags=['rag', 'en']
),
# 3. 指令遵循能力 (40%)
# args 均用于传递给底层数据集加载器,如 subset_list 指定子集
DatasetInfo(
name='ifeval',
weight=0.4,
task_type='instruction',
tags=['rag', 'en'],
),
]
)
# 打印查看归一化后的权重分布
print(rag_schema.flatten())💡 提示:weight 可以是任意正数,EvalScope 会自动进行归一化处理。通过 flatten() 方法可以预览最终每个数据集的实际占比。
第二步:采样数据
定义好 Schema 后,我们需要按照策略抽取样本。EvalScope 提供了多种采样器,针对“构建指数”场景,我们推荐使用 加权采样 (WeightedSampler)。
- 加权采样:样本数量与你设置的权重成正比。权重越高的任务,在测试集中出现的题目越多,对总分的影响也越大。这最能体现“业务导向”。
from evalscope.collections import WeightedSampler
from evalscope.utils.io_utils import dump_jsonl_data
# 初始化加权采样器
sampler = WeightedSampler(rag_schema)
# 采样 100 条数据作为最终测试集
# 根据权重,知识问答 30 条,长文本检索 30 条,指令遵循 40 条
# 实际采样数量可根据需要调整
mixed_data = sampler.sample(count=100)
# 将混合好的数据保存为 JSONL 文件,这就是你的“指数评测集”
dump_jsonl_data(mixed_data, 'outputs/rag_index_testset.jsonl')StratifiedSampler(分层采样):保持原数据集的样本规模比例(适合不做人为干预的客观统计)。UniformSampler(均匀采样):所有数据集样本数相同(适合横向对比各能力短板)。
第三步:统一评测
现在,你拥有了一个名为 rag_index_testset.jsonl 的文件。在 EvalScope 看来,它就是一个普通的本地数据集。我们直接调用 run_task 即可。
import os
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='qwen2.5-14b-instruct', # 评测模型
# 使用一个提供 OpenAI 兼容接口的模型进行评测
# 可以是云上的API,也可以是通过vllm等框架部署的本地模型
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=os.getenv('DASHSCOPE_API_KEY'),
eval_type='openai_api',
# 关键配置:指定数据集为 'data_collection' 模式
datasets=['data_collection'],
dataset_args={
'data_collection': {
'local_path': 'outputs/rag_index_testset.jsonl', # 指向刚才生成的文件
'shuffle': True # 打乱顺序
}
},
eval_batch_size=5, # 根据你的 API 并发限额调整
generation_config={
'temperature': 0.0 # 评测通常设为 0 以保证结果可复现
},
# 使用强大的模型作为 judge 进行自动评分 (chinese_simpleqa 需要)
judge_model_args={
'model_id': 'qwen3-max',
'api_url': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'api_key': os.getenv('DASHSCOPE_API_KEY'),
},
judge_worker_num=5, # judge 并发数,根据实际情况调整
)
run_task(task_cfg=task_cfg)看懂评测报告:
评测完成后,你会在日志中看到 category_level Report,其中的 weighted_avg 就是你最关心的Index 总分。
2025-12-23 18:01:45 - evalscope - INFO: task_level Report:
+--------------+------------+------------+---------------+-------+
| task_type | micro_avg. | macro_avg. | weighted_avg. | count |
+--------------+------------+------------+---------------+-------+
| instruction | 0.9231 | 0.9231 | 0.9231 | 39 |
| long_context | 0.1333 | 0.1333 | 0.1333 | 30 |
| knowledge | 0.3793 | 0.3833 | 0.3793 | 29 |
+--------------+------------+------------+---------------+-------+
2025-12-23 18:01:45 - evalscope - INFO: tag_level Report:
+------+------------+------------+---------------+-------+
| tags | micro_avg. | macro_avg. | weighted_avg. | count |
+------+------------+------------+---------------+-------+
| rag | 0.5204 | 0.4114 | 0.5204 | 98 |
| en | 0.5797 | 0.5797 | 0.5797 | 69 |
| zh | 0.3793 | 0.3833 | 0.3793 | 29 |
+------+------------+------------+---------------+-------+
2025-12-23 18:01:45 - evalscope - INFO: category_level Report:
+------------------+------------+------------+---------------+-------+
| category0 | micro_avg. | macro_avg. | weighted_avg. | count |
+------------------+------------+------------+---------------+-------+
| rag_assist_index | 0.5204 | 0.4114 | 0.5204 | 98 |
+------------------+------------+------------+---------------+-------+weighted_avg: 基于你定义的 Schema 权重计算的得分。如果这个分数高,说明模型非常契合我们之前自定义的“业务价值观”。
第四步:Case分析
拿到 Index 总分并不代表工作结束。相反,分析模型为什么取得这个分数通常更有价值:是模型知识储备不足?还是仅仅因为没按格式输出被误判?
EvalScope 内置了可视化分析工具,让你非常方便查看每一个样本的详细情况。无需编写额外代码,只需在终端运行一条命令,即可启动本地服务:
evalscope app打开浏览器访问 http://127.0.0.1:7860即可查看模型得分分布和在每个问题的回复和打分:
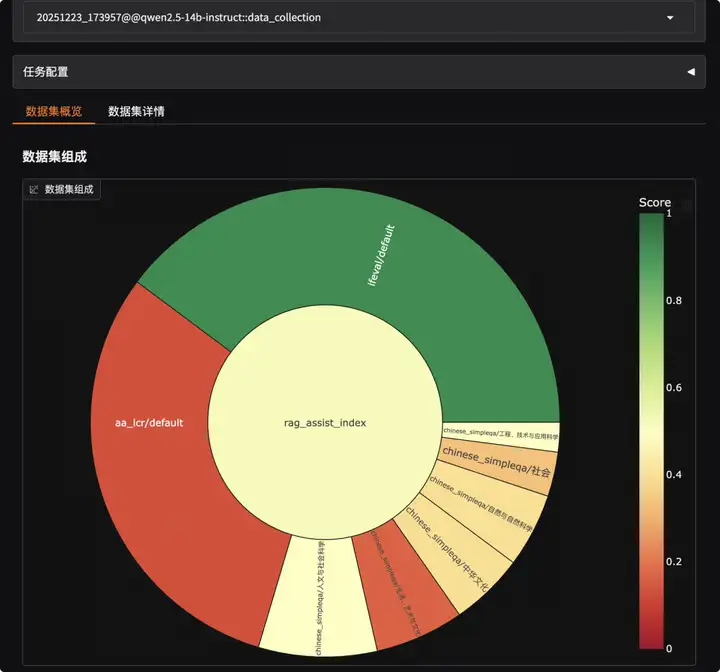
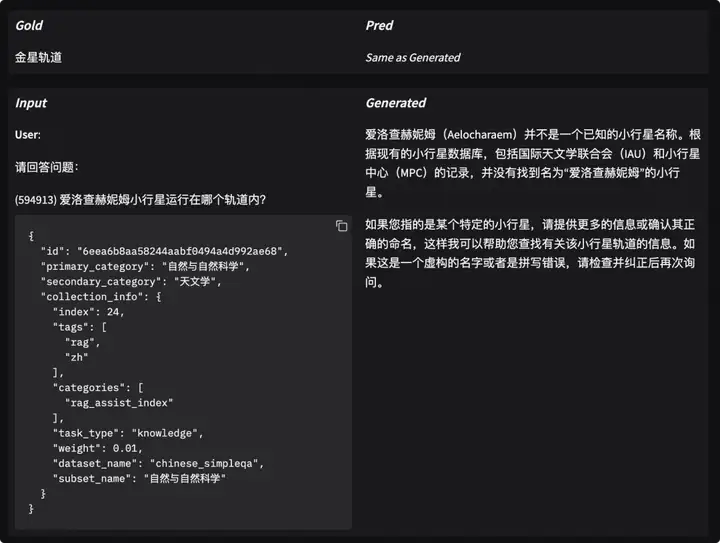
更多场景案例
EvalScope 的 Index 构建能力非常灵活,除了 RAG,你还可以构建各种垂直领域的指数。
案例 A:代码补全与分析指数
关注 Python 代码生成能力以及真实的 Issue 修复能力,且更看重 Python 能力。
schema = CollectionSchema(name='code_index', datasets=[
# 基础 Python 代码生成,给予较高的权重(60%)
DatasetInfo(name='humaneval', weight=0.6, task_type='code', tags=['python']),
# 真实场景代码竞赛题,包含特定时间段的数据,40% 权重
DatasetInfo(
name='live_code_bench',
weight=0.4,
task_type='code',
tags=['complex'],
args={
'subset_list': ['v5'],
'review_timeout': 6,
'extra_params': {'start_date': '2024-08-01', 'end_date': '2025-02-28'}
}
),
])案例 B:模型推理能力指数 (Reasoning Index)
混合多种推理任务,并通过嵌套结构管理中英文数据集。
# 嵌套结构示例:数学组 + 推理组
schema = CollectionSchema(name='reasoning_index', datasets=[
CollectionSchema(name='math', weight=0.5, datasets=[
DatasetInfo(name='gsm8k', weight=0.5, tags=['en']),
DatasetInfo(name='aime25', weight=0.5, tags=['en']),
]),
CollectionSchema(name='logic', weight=0.5, datasets=[
DatasetInfo(name='arc', weight=0.5, tags=['en']),
DatasetInfo(name='ceval', weight=0.5, tags=['zh'], args={'subset_list': ['logic']}),
]),
])
进阶:分享你的Index
我们相信,每一个细分领域,无论是医疗问答、法律文书审核,还是金融研报分析,都需要一把精确的尺子。而最懂这把尺子该怎么刻度的,正是深耕于该领域的你。
当你构建出一个高质量的评测指数时,它不应该只躺在你的硬盘里。我们强烈鼓励你将生成的数据集上传到 ModelScope 社区。这不仅能让更多开发者受益,也能让你的标准成为行业共识。
如何上传到ModelScope仓库?
手动上传数据集到ModelScope的具体方法可参考文档,使用modelscope SDK直接执行如下Python代码:
from modelscope.hub.api import HubApi
# 登陆
YOUR_ACCESS_TOKEN = '请从https://modelscope.cn/my/myaccesstoken 获取SDK令牌'
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)
# 配置数据集并上传
owner_name = 'user'
dataset_name = 'MyEvaulationIndex'
api.upload_file(
path_or_fileobj='/path/to/local/your_index.jsonl',
path_in_repo='your_index.jsonl',
repo_id=f"{owner_name}/{dataset_name}",
repo_type = 'dataset',
commit_message='upload dataset file to repo',
)或者使用modelscope CLI:
# 登陆
modelscope login --token YOUR_ACCESS_TOKEN
# 上传文件
modelscope upload owner_name/dataset_name /path/to/local/your_index.jsonl your_index.jsonl --repo-type dataset如何使用社区共享的 Index?
例如,社区已经贡献了 模型推理能力测试集,其数据集ID为evalscope/R1-Distill-Math-Evaluation-Index。你无需自己在本地采样,直接引用 Dataset Id 即可开始评测:
from evalscope import TaskConfig, run_task
import os
task_cfg = TaskConfig(
model='qwen-plus',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=os.getenv('DASHSCOPE_API_KEY'),
# 直接加载社区上的 Index 数据集
datasets=['data_collection'],
dataset_args={
'data_collection': {
'dataset_id': 'evalscope/R1-Distill-Math-Evaluation-Index', # 社区数据集 ID
}
}
)
run_task(task_cfg=task_cfg)
总结
构建评测指数不再是大厂或学术界的专利。通过 EvalScope 的 Collection 机制:
- 用 Schema 定义了业务的价值观
- 用 Sampler 将价值观具象化为测试数据
- 用 Eval 获得了一个可信的决策依据
- 用 Case 分析定位了模型的弱点
不要再局限于通用榜单的分数,现在就开始构建属于你自己的 Index,选出真正适合你业务的“最佳模型”吧!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献1001条内容
已为社区贡献1001条内容

所有评论(0)