
Qwen3-VL-Embedding & Qwen3-VL-Reranker:统一多模态表征与排序
2025年6月,通义千问Qwen团队开源了面向文本的Qwen3-Embedding和Qwen3-ReRanker 模型系列,在多语言文本检索、聚类和分类等多项下游任务中取得了业界领先的性能,被社区开发者广泛使用。 1月8日,Qwen团队再推出家族最新成员:Qwen3-VL-Embedding 和 Qwen3-VL-Reranker模型系列。基于其最近开源的Qwen3-VL模型构建,专为多模态信息检索和跨模态理解场景设计。
核心特性
- 多模态通用性 两个模型系列均可在统一框架内处理包含文本、图像、截图和视频的输入。它们在图文检索、视频文本匹配、视觉问答(VQA)以及多模态内容聚类等多样化任务中达到了业界领先水平。
- 统一表示学习(Embedding) 通过充分利用Qwen3-VL基础模型的优势,Qwen3-VL-Embedding模型能够生成语义丰富的向量表示,在共享空间中同时捕获视觉和文本信息,从而实现高效的跨模态相似度计算和检索。
- 高精度重排序(Reranker) 我们同步提供Qwen3-VL-Reranker系列作为 Embedding模型的补充。Qwen3-VL-Reranker接收输入对(Query, Document), 其中查询和文档均可包含任意单一或混合模态——并输出精确的相关性分数。在实际检索场景中,Embedding和Reranker模型通常协同工作:Embedding模型负责初始召回阶段,Reranker模型负责重排序阶段,这种两阶段流程显著提升了最终检索精度。
- 卓越的实用性继承Qwen3-VL的多语言能力,该系列支持超过30种语言,适合全球化应用。模型提供灵活的向量维度选择、可定制的任务指令,以及向量量化后的强劲性能。这些特性使开发者能够轻松将两个模型集成到现有流程中,用于需要强大跨语言和跨模态理解能力的应用场景。
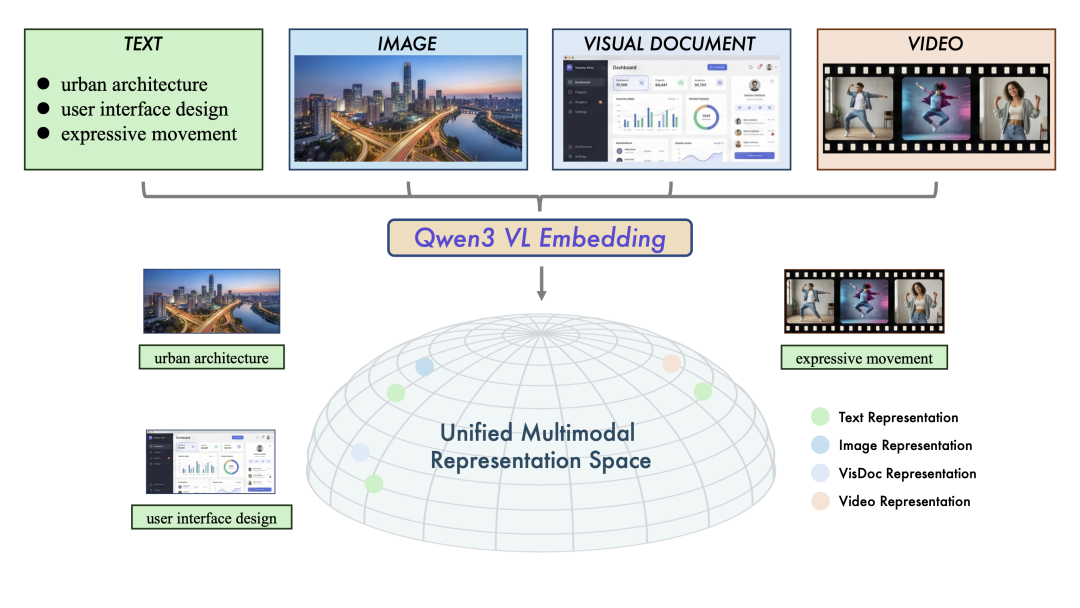
图1:统一多模态表示空间示意图。</strong>Qwen3-VL-Embedding模型系列将多源数据(文本、图像、视觉文档和视频)映射到共同的高维语义空间。
模型概览
下表展示了Qwen3-VL-Embedding和Qwen3-VL-Reranker的详细规格参数:
| 模型 | 参数量 | 模型层数 | 序列长度 | 嵌入维度 | 量化支持 | MRL 支持 | 指令感知 |
| Qwen3-VL-Embedding-2B | 2B | 28 | 32K | 2048 | ✓ | ✓ | ✓ |
| Qwen3-VL-Embedding-8B | 8B | 36 | 32K | 4096 | ✓ | ✓ | ✓ |
| Qwen3-VL-Reranker-2B | 2B | 28 | 32K | · | · | · | ✓ |
| Qwen3-VL-Reranker-8B | 8B | 36 | 32K | · | · | · | ✓ |
注:「量化支持表示Embedding支持的量化后处理;「MRL 支持」表示 Embedding 模型是否允许用户指定嵌入维度;「指令感知」表示模型是否支持针对特定任务自定义输入指令。
模型架构
与文本Qwen3-Embedding和Qwen3-ReRanker模型系列类似,Qwen3-VL-Embedding 采用双塔架构,Qwen3-VL-Reranker采用单塔架构。研究团队设计了一套多阶段训练范式,充分发挥Qwen3-VL底座模型的通用多模态语义理解能力,为复杂、大规模的多模态检索任务提供高质量的语义表示和精确的重排序机制。
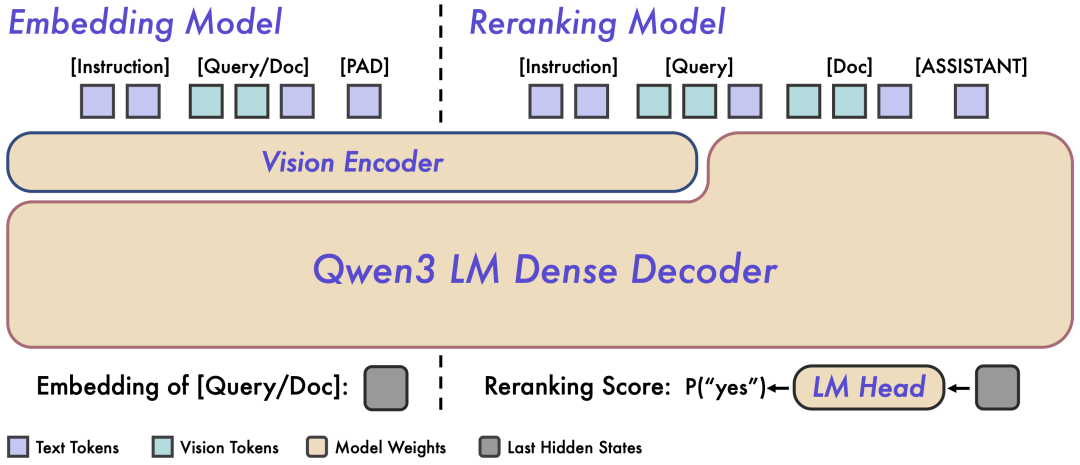
图 2:Qwen3-VL-Embedding和Qwen3-VL-Reranker 架构概览。左侧为Embedding模型的双塔独立编码架构,右侧为Reranker 模型的单塔交叉注意力架构。
Embedding模型接收单模态或混合模态输入,并将其映射为高维语义向量。具体而言,研究团队提取基座模型最后一层中对应 [EOS] token 的隐藏状态向量,作为输入的最终语义表示。这种方法确保了大规模检索所需的高效独立编码能力。
Reranking模型接收输入对 (Query, Document) 并进行联合编码。它利用基座模型内的交叉注意力(Cross-Attention)机制,实现 Query 和 Document 之间更深层、更细粒度的跨模态交互和信息融合。模型最终通过预测两个特殊 token(yes 和 no)的生成概率来表达输入对的相关性分数。
功能特性对比
| 对比维度 | Qwen3-VL-Embedding | Qwen3-VL-Reranker |
| 核心功能 | 语义表示、嵌入生成 | 相关性评分、重排序 |
| 输入格式 | 单模态或混合模态(文本、图像、视频、截图) | (Query, Document) 对,Query 和 Document 均可为单模态或混合模态输入 |
| 工作机制 | 独立编码,高效检索(双塔架构) | 深度跨模态交互 |
| 输出目标 | 向量空间中的语义聚类 | 输出相关性分数 |
评测结果
Qwen3-VL-Embedding
研究团队主要在MMEB-v2和MMTEB基准测试上评估了Qwen3-VL-Embedding 模型的性能。
Qwen3-VL-Embedding-8B模型在MMEB-V2上取得了业界领先的结果,超越了所有先前的开源模型和闭源商业服务。
在纯文本多语言MMTEB基准测试上,Qwen3-VL-Embedding模型与同等规模的纯文本 Qwen3-Embedding模型相比有少许的性能差距。与评测排行榜上其他同等规模的模型相比,它仍然展现出极具竞争力的性能表现。
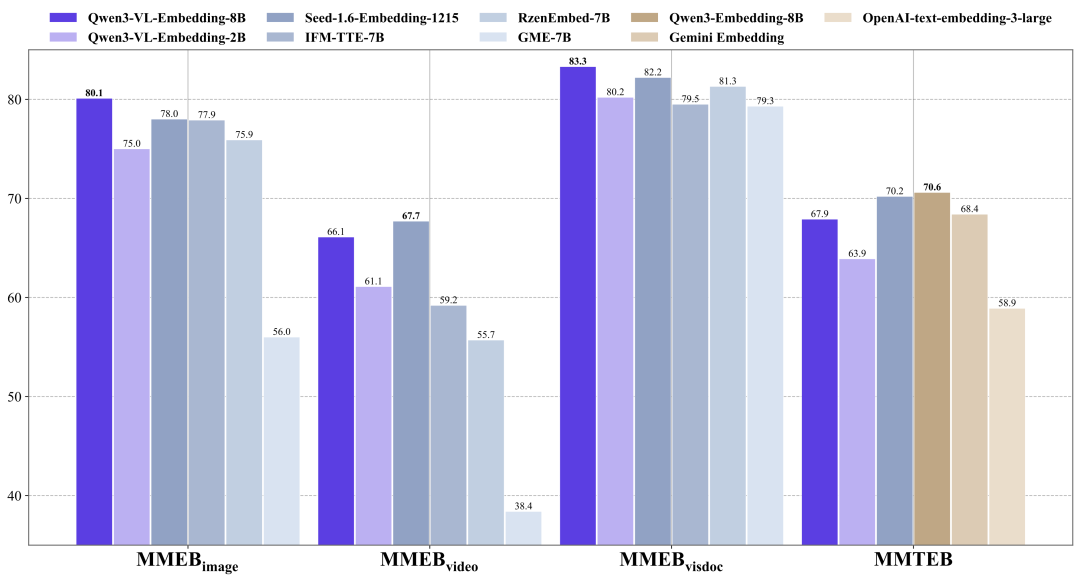
图 3:Qwen3-VL-Embedding在MMEB-v2和MMTEB评测集上的性能对比。
Qwen3-VL-Reranker
研究团队使用了MMEB-v2和MMTEB检索基准中各子任务的检索数据集进行评测。对于视觉文档检索,采用了JinaVDR和ViDoRe v3数据集。
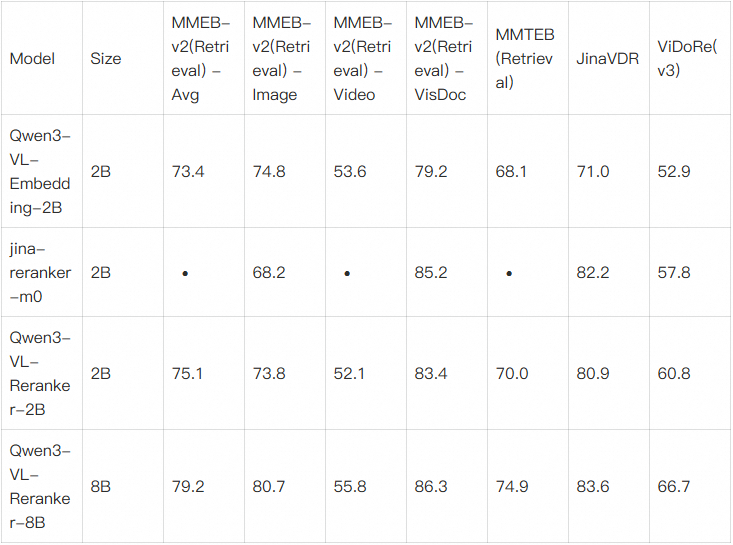
评测结果表明,所有Qwen3-VL-Reranker模型的性能均持续优于基础 Embedding模型和基线Reranker模型,其中8B 版本在大多数任务中达到了最佳性能。
表2:Qwen3-VL-Reranker 评测结果对比
使用指南
Embedding 和 Reranking 模型通常在检索系统中协同使用,形成高效的两阶段检索流程: 1). 召回阶段:Embedding 模型执行初始召回,从海量数据中快速检索出大量候选结果。 2). 重排序阶段:Reranking 模型对候选结果进行精细化排序,基于重新计算的相关性分数为用户查询呈现最精确的结果。
Embedding模型使用示例
from scripts.qwen3_vl_embedding import Qwen3VLEmbedder
import numpy as np
import torch
# Define a list of query texts
queries = [
{"text": "A woman playing with her dog on a beach at sunset."},
{"text": "Pet owner training dog outdoors near water."},
{"text": "Woman surfing on waves during a sunny day."},
{"text": "City skyline view from a high-rise building at night."}
]
# Define a list of document texts and images
documents = [
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust."},
{"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"},
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust.", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}
]
# Specify the model path
model_name_or_path = "Qwen/Qwen3-VL-Embedding-2B"
# Initialize the Qwen3VLEmbedder model
model = Qwen3VLEmbedder(model_name_or_path=model_name_or_path)
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# model = Qwen3VLEmbedder(model_name_or_path=model_name_or_path, dtype=torch.float16, attn_implementation="flash_attention_2")
# Combine queries and documents into a single input list
inputs = queries + documents
embeddings = model.process(inputs)
# Compute similarity scores between query embeddings and document embeddings
similarity_scores = (embeddings[:4] @ embeddings[4:].T)
# Print out the similarity scores in a list format
print(similarity_scores.tolist())
# [[0.83203125, 0.74609375, 0.73046875], [0.5390625, 0.373046875, 0.48046875], [0.404296875, 0.326171875, 0.357421875], [0.1298828125, 0.06884765625, 0.10595703125]]Reranking模型使用示例
from scripts.qwen3_vl_reranker import Qwen3VLReranker
import numpy as np
import torch
# Specify the model path
model_name_or_path = "Qwen/Qwen3-VL-Reranker-2B"
# Initialize the Qwen3VLEmbedder model
model = Qwen3VLReranker(model_name_or_path=model_name_or_path)
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# model = Qwen3VLReranker(model_name_or_path=model_name_or_path, dtype=torch.float16, attn_implementation="flash_attention_2")
# Combine queries and documents into a single input list
inputs = {
"instruction": "Retrieval relevant image or text with user's query",
"query": {"text": "A woman playing with her dog on a beach at sunset."},
"documents": [
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust."},
{"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"},
{"text": "A woman shares a joyful moment with her golden retriever on a sun-drenched beach at sunset, as the dog offers its paw in a heartwarming display of companionship and trust.", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}
],
"fps": 1.0
}
scores = model.process(inputs)
print(scores)
# [0.8408790826797485, 0.6197134852409363, 0.7778129577636719]Embedding模型训练示例
ms-swift 支持了对Qwen3-VL-Embedding/Qwen3-VL-Reranker的微调。ms-swift开源地址:https://github.com/modelscope/ms-swift
环境准备:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .训练脚本如下:
# 2 * 30GiB
CUDA_VISIBLE_DEVICES=0,1 \
INFONCE_TEMPERATURE=0.1 \
NPROC_PER_NODE=2 \
swift sft \
--model Qwen/Qwen3-VL-Embedding-8B \
--task_type embedding \
--train_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--learning_rate 5e-6 \
--target_modules all-linear \
--dataset swift/TextCaps:emb \
--attn_impl flash_attn \
--padding_free true \
--torch_dtype bfloat16 \
--load_from_cache_file true \
--split_dataset_ratio 0.02 \
--eval_strategy steps \
--output_dir output \
--save_steps 50 \
--eval_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--num_train_epochs 1 \
--max_length 8192 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--gradient_accumulation_steps 1 \
--dataloader_num_workers 4 \
--dataset_num_proc 4 \
--warmup_ratio 0.05 \
--loss_type infonce \
--dataloader_drop_last true \
--deepspeed zero2推理脚本参考:
https://github.com/modelscope/ms-swift/blob/main/examples/train/embedding/qwen3
自定义数据集格式如下,修改 --dataset <dataset-path>即可,具体参考文档:https://swift.readthedocs.io/zh-cn/latest/BestPractices/Embedding.html
{"messages": [{"role": "user", "content": "<image>"}], "images": ["/some/images.jpg"], "positive_messages": [[{"role": "user", "content": "sentence"}]]}
{"messages": [{"role": "user", "content": "<image>sentence1"}], "images": ["/some/images.jpg"], "positive_messages": [[{"role": "user", "content": "<image>sentence2"}]], "positive_images": [["/some/positive_images.jpg"]], "negative_messages": [[{"role": "user", "content": "<image><image>sentence3"}], [{"role": "user", "content": "<image>sentence4"}]], "negative_images": [["/some/negative_images1.jpg", "/some/negative_images2.jpg"], ["/some/negative_images3.jpg"]]}Reranker模型训练示例
训练脚本如下:
# 2 * 70GiB
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=2 \
swift sft \
--model Qwen/Qwen3-VL-Reranker-8B \
--task_type generative_reranker \
--loss_type generative_reranker \
--train_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--learning_rate 5e-6 \
--target_modules all-linear \
--dataset swift/TextCaps:rerank \
--attn_impl flash_attn \
--padding_free true \
--torch_dtype bfloat16 \
--load_from_cache_file true \
--split_dataset_ratio 0.02 \
--eval_strategy steps \
--output_dir output \
--save_steps 50 \
--eval_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--num_train_epochs 1 \
--max_length 4096 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--dataloader_num_workers 4 \
--dataset_num_proc 4 \
--warmup_ratio 0.05 \
--dataloader_drop_last true \
--deepspeed zero2
推理脚本参考:
https://github.com/modelscope/ms-swift/blob/main/examples/train/reranker/qwen3
自定义数据集格式如下,具体参考文档:https://swift.readthedocs.io/zh-cn/latest/BestPractices/Reranker.html
{"messages": [{"role": "user", "content": "query"}], "positive_messages": [[{"role": "assistant", "content": "relevant_doc1"}],[{"role": "assistant", "content": "relevant_doc2"}]], "negative_messages": [[{"role": "assistant", "content": "irrelevant_doc1"}],[{"role": "assistant", "content": "irrelevant_doc2"}], ...]}更多使用示例,请访问 GitHub 仓库。
未来展望
Qwen3-VL-Embedding和Qwen3-VL-Reranker模型系列是研究团队在统一多模态表示和检索领域的初步探索。 相比纯文本的Embedding和Reranking模型,多模态学习,尤其是统一多模态表征和重排序在模型成熟度提升,易用性优化,应用场景扩展等方面仍有巨大的探索空间。 Qwen3-VL-Embedding和Qwen3-VL-Reranker的开源是一个新的起点,期待与社区携手合作,共同探索和构建更加通用的统一多模态检索能力,推动多模态AI技术的发展与落地应用。
点击即可跳转模型合集
https://modelscope.cn/collections/Qwen/Qwen3-VL-Embedding-and-Rerank

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献962条内容
已为社区贡献962条内容

所有评论(0)