
从 Image-to-LoRA 到 In-Context Edit
前段时间,我们发布了 Qwen-Image 的 Image-to-LoRA 模型(https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L),它可以直接将图片数据转化为 LoRA 模型,从而生成相似的图像。
在发布这个模型之后,我们一直在思考能否将这样的能力赋予图像编辑模型。很遗憾,我们没能训练出图像编辑模型的 Image-to-LoRA 模型,但我们用上下文内编辑(In-Context Edit)技术路线实现了类似的功能,并发布了新的模型(https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-Edit-2511-ICEdit-LoRA)。本文将介绍我们我们如何为新发布的 Qwen-Image-Edit-2511 实现这样的功能。
图像编辑的 LoRA 模型能做什么?
从图像生成到图像编辑,LoRA 模型的作用发生了变化。在图像生成中,我们可以用 LoRA 控制生成图像的风格等,而在图像编辑中,LoRA 则通常被用于特定的“图到图转换”。
例如模型 dx8152/Qwen-Edit-2509-Light-Migration(https://modelscope.cn/models/dx8152/Qwen-Edit-2509-Light-Migration)可以为图像重新打光。

通常,这些 LoRA 实现的编辑能力是文本很难精确描述的,例如在上述例子中,光线从什么方向射入,光线的色调如何,光线有多明亮等,自然语言难以事无巨细地描述清楚图像编辑的每一个细节。但当我们给出“编辑前后的图像对”作为样例时,图像编辑的过程就变得一目了然。图像编辑的 LoRA 模型正是通过“编辑前后的图像对”训练出的,模型通过这样的训练数据理解图像编辑需求,并把这种“图到图转换”应用到新的图像上。
为什么无法实现图像编辑的 Image-to-LoRA 模型?
准确地说,图像编辑的 Image-to-LoRA 模型实际上是 Image-Pair-to-LoRA。例如在下面修改人物表情的例子中,我们的 Image-Pair-to-LoRA 模型需要输入第一行的两张图片,理解这一转换是“让人物开怀大笑”并输出一个 LoRA 模型。然后,我们将这一 LoRA 模型用于新的图像编辑,输入第三张图,让图中的老人也开怀大笑,输出第四张图。
编辑前

编辑后

编辑前

编辑后

如果我们用“编辑前后的图像对”来训练 Image-Pair-to-LoRA 模型,则会导致模型倾向于生成编辑后的图像,而不是关注两张图的变化。所以我们必须使用四张图的训练数据来训练模型,严苛的数据格式导致我们很难大规模地构造训练数据集,我们东拼西凑了一个包含 3 万个样本的数据集。这样匮乏的数据量让 Image-Pair-to-LoRA 模型变得不可能。
如何激活模型的上下文内编辑(In-Context Edit)?
既然 Image-Pair-to-LoRA 模型无法实现,我们考虑使用其他技术路线的研究成果实现类似的功能。注意到整个过程实际可以认为是一个多图输入的编辑过程,即输入给模型图1、图2、图3,模型把图1到图2的变化应用到图3,生成图4。而最近发布的 Qwen-Image-Edit-2511 模型恰好是一个多图编辑模型,我们可以直接利用模型的多图编辑能力实现这样的上下文内编辑(In-Context Edit)。上下文内编辑是我们一直在探索的另一项技术,此时与 Image-to-LoRA 的能力发生了交汇。

我们训练并开源了这样一个模型(https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-Edit-2511-ICEdit-LoRA),模型结构是普通的 LoRA,它可以激活 Qwen-Image-Edit-2511 的上下文内编辑能力。只需要给出图像编辑的样例,模型就可以自行理解并编辑新的图像。最重要的是,这样的模型结构由于继承了编辑模型自身的多图编辑能力,以较少的数据(3 万个样本)就可以训练完成。我们用另一种方式实现了与 Image-Pair-to-LoRA 模型类似的功能。
上下文内编辑能力有什么潜力?
2023年开始,以 GPT 为代表的一批大语言模型出现,大语言模型技术的飞速发展为“文本到文本”类任务带来了红利,彻底改变了自然语言理解领域的研究。如今,Qwen-Image-Edit 等模型已经在“图像到图像”类任务上取得了突破,这些图像编辑模型有望在计算机视觉的诸多任务中应用。
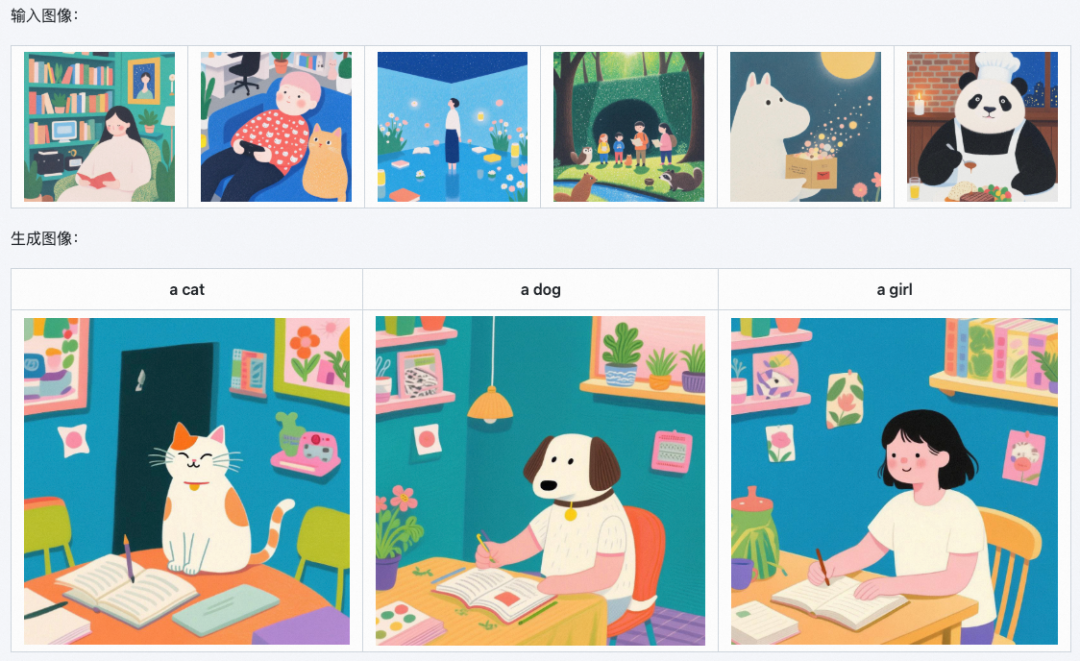
例如,我们的 In-Context Edit 模型可以用于图像分割。

这意味着图像编辑大模型真的可以直接用于计算机视觉的诸多任务,这是未来值得研究的问题。
下一步我们要做什么?
- 这个模型的效果仍然有较大提升空间,我们在改进模型结构,未来将会发布改进后的模型,进一步发挥模型的上下文内编辑能力。
- 模型的能力是一系列原子能力的组合,我们在继续构建更大的数据集,这一数据集将会在未来开源。
- 这一模型能够让图像编辑模型用于诸多计算机视觉的任务,我们将在某些任务中验证其效果,未来会发布详细技术报告。
点击即可跳转模型链接:
https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-Edit-2511-ICEdit-LoRA

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献948条内容
已为社区贡献948条内容

所有评论(0)