
阶跃星辰发布首个开源 LLM 级音频编辑大模型 Step-Audio-EditX
近期,阶跃星辰发布了全球首个开源 LLM 级音频编辑大模型 —— Step-Audio-EditX。
该模型能够通过语言指令或迭代方式,精准控制音频的情感、说话风格和副语言特征,并实现 零样本文本转语音(Zero-Shot TTS)。
不同于以往依赖多模块拼接的方案,Step-Audio-EditX 采用统一的 LLM 框架,让“文字驱动音频创作”真正变为现实。
开源信息
- 开源协议:Apache 2.0
- Github:https://github.com/stepfun-ai/Step-Audio-EditX
- Model:https://www.modelscope.cn/models/stepfun-ai/Step-Audio-EditX
- Technical Report:https://www.modelscope.cn/papers/2511.03601
- 使用提示:
模型与部分训练数据可自由研究与非商用使用,商用需遵守对应授权条款。
01项目概览
- 项目名称:Step-Audio-EditX
- 开发团队:StepFun(阶跃星辰)
- 项目类型:开源 LLM 级音频编辑与合成模型
- 主要功能:• 零样本文本转语音(Zero-Shot TTS)• 音频情感与风格编辑• 副语言特征控制(呼吸、笑声、叹息、语气等)• 多语言与方言支持(中文、英文、四川话、粤语等)
- 在线体验:http://stepaudiollm.github.io/step-audio-editx
02技术架构
Step-Audio-EditX 的核心设计可概括为三部分:
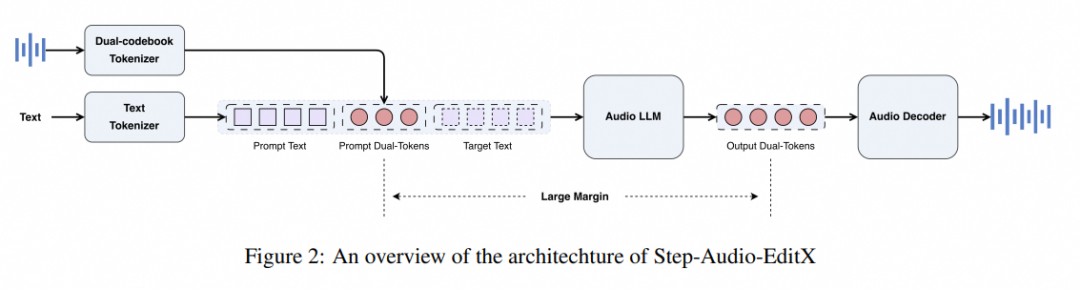
音频分词器(Tokenizer)
使用“双码本”结构,将音频分解为离散 token:
- • 语言码本:1024 项,16.7 Hz 采样频率;
- • 语义码本:4096 项,25 Hz 采样频率。
这种双路径分词方式让模型能同时捕捉语言内容与声学细节。
音频大语言模型(Audio LLM)
在音频 token 与文本 token 的联合输入下生成目标音频 token,参数约 3 B。
它的输入格式类似聊天框:“文本 + 音频”,输出即为新音频的 token 序列。
解码器(Decoder)
通过 Flow Matching 模块生成 Mel 谱图,并由 BigVGAN v2 声码器合成音频。
这一流程让音频生成质量与真实录音相近,且可控性极强。
03核心亮点
多维度情感与风格控制
Step-Audio-EditX 可以通过简单的指令控制音频的:
- • 情感:愤怒、喜悦、悲伤、恐惧、惊讶、厌恶等
- • 说话风格:夸张、认真、孩童、低语、年长、俏皮等
- • 副语言元素:呼吸声、笑声、叹息、语气词(嗯、唉、哎呀等)
更重要的是,它支持 迭代式编辑——可在原音基础上多轮微调,实现自然、可累积的情感强化。
零样本 TTS(Zero-Shot TTS)
无需录音样本,仅凭参考音频或风格描述,即可生成新语音。
例如:
“将这段话改为粤语,带一点俏皮语气。”
即可立刻输出对应版本的音频。
模型支持中英双语及多方言,让 TTS 真正实现“所写即所听”。
大规模合成数据训练
与传统模型依赖复杂的音频先验模块不同,Step-Audio-EditX 使用 大边距合成数据(Large-Margin Synthetic Data) 训练,直接通过属性差异拉大(如“同文本、异情感”样本)实现情感与风格的解耦学习。
这一策略让模型具备天然的“可控”特性,能够理解并执行复杂的语音编辑指令。
04训练与部署
- 模型规模:约 3 B 参数
- 推荐硬件:单卡 32 GB GPU 即可运行(提供 Int8 量化版)
- 采样率:41.6 kHz
- 部署方式:
- • 支持 Docker 镜像部署
- • 支持本地命令行推理
- • 提供 Gradio 网页 Demo
示例命令
零样本语音生成:
python3 tts_infer.py \
--model-path ./models \
--prompt-text "今天的天气真不错!" \
--prompt-audio ./ref.wav \
--generated-text "我们一起去公园吧。" \
--edit-type "clone"情感编辑:
python3 tts_infer.py \
--model-path ./models \
--prompt-audio ./voice.wav \
--edit-type "emotion" \
--edit-info "sad" \
--n-edit-iter 2
05性能表现
官方报告显示,Step-Audio-EditX 在以下方面表现突出:
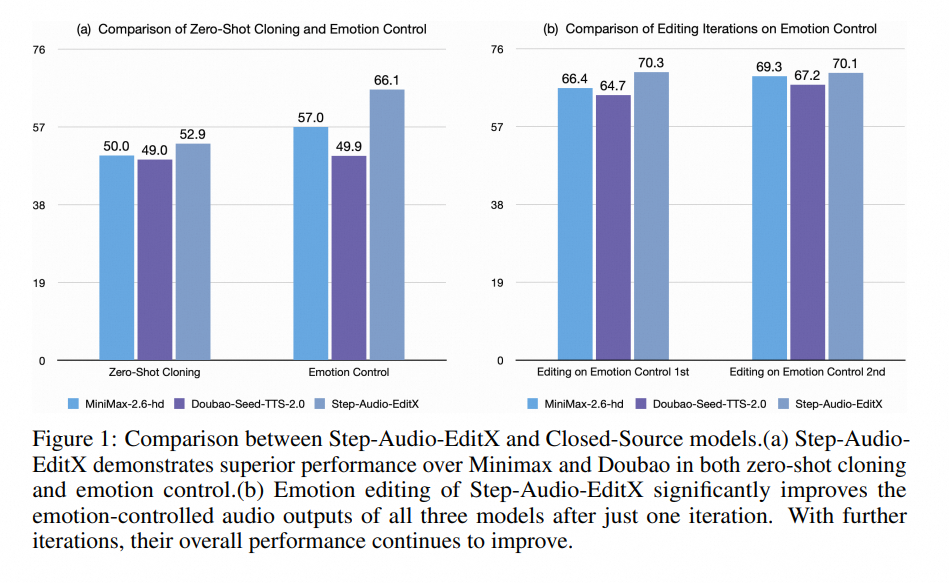
• 情感与风格控制的准确率优于闭源模型(如 MiniMax-2.6-hd、Doubao-Seed-TTS 2.0);
• 多轮迭代能显著提升输出音频的自然度与表达力;
• 对外部音频的副语言插入任务泛化良好,可编辑闭源语音素材。
模型链接:https://www.modelscope.cn/models/stepfun-ai/Step-Audio-EditX

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐

 0
0 0
0- 0



 已为社区贡献993条内容
已为社区贡献993条内容

所有评论(0)