
一张图能装下“千言万语”?DeepSeek-OCR 用视觉压缩长文本,效率提升10倍!
当前的大语言模型(LLM)在处理超长文本时,面临着一个“甜蜜的烦恼”:计算开销随序列长度呈平方级增长。一篇万字论文、一本电子书、甚至一份会议纪要,都可能让模型“喘不过气”。
有没有一种方式,用更少的 token 表达更多信息?DeepSeek 团队给出了一个极具想象力的答案:把文字“画”成图,用视觉做压缩!
他们最新发布的 DeepSeek-OCR 模型,不仅在 OCR(光学字符识别)任务上达到 SOTA,更提出了一种全新的范式:“上下文光学压缩”(Contexts Optical Compression)。
- GitHub 开源:https://github.com/deepseek-ai/DeepSeek-OCR
- 模型开源:DeepSeek-OCR
什么是“上下文光学压缩”?
简单来说,就是:
将一段长文本渲染成一张图像,再用视觉编码器将其压缩为极少量的“视觉 token”,最后由语言模型“解压”还原为原始文本。
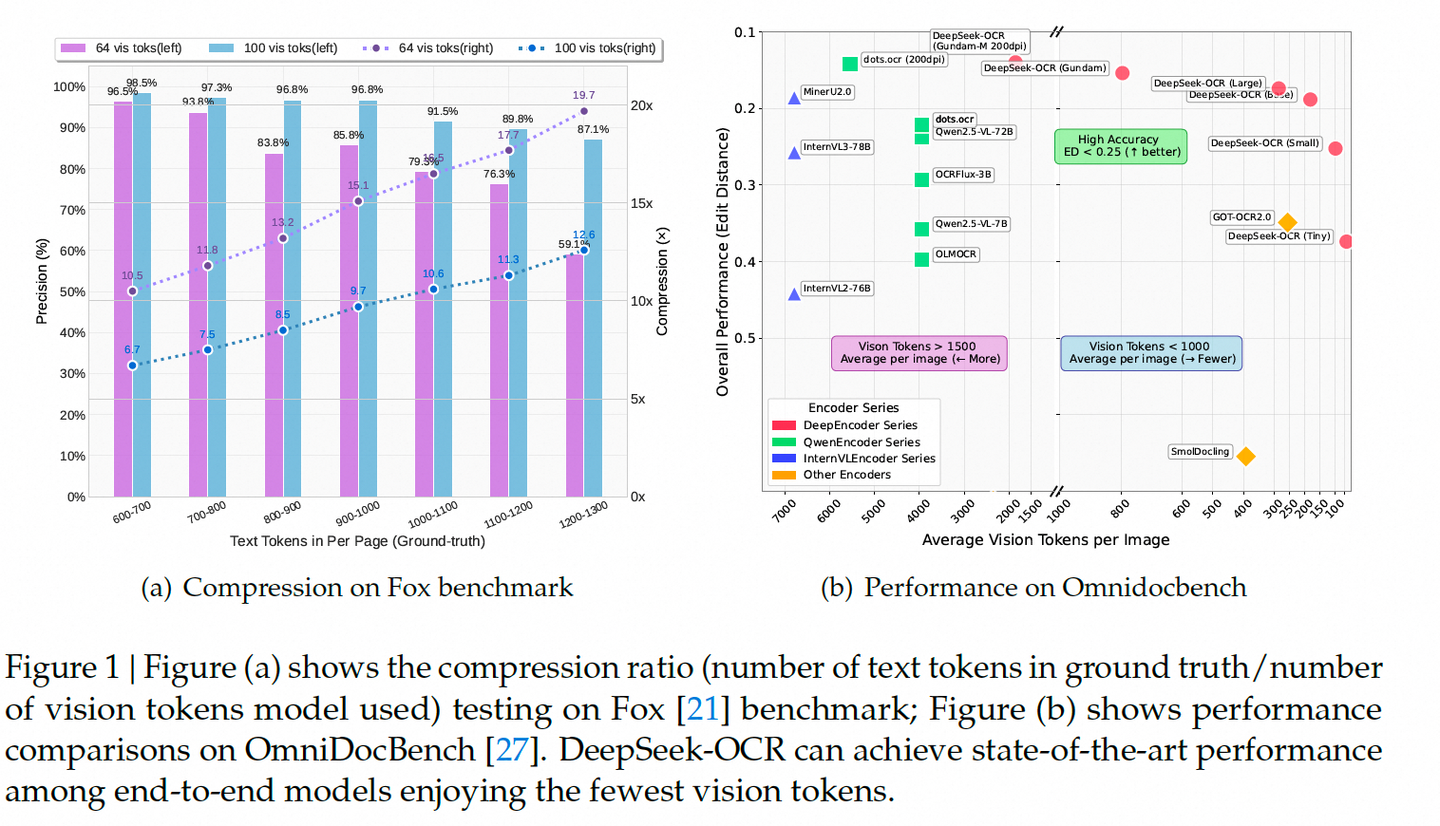
听起来像科幻?但实验结果令人震惊:
- 压缩比 ≤10×(即 1000 个文字 token → 100 个视觉 token)时,OCR 精度高达 97%;
- 即使压缩到 20×,精度仍能保持在 60% 左右;
- 在 OmniDocBench 基准上,仅用 100 个视觉 token 就超越了 GOT-OCR2.0(256 tokens);
- 用不到 800 个 token,就干翻了需要 7000+ tokens 的 MinerU2.0!
这意味着:一张图,真的能装下“千言万语”。
技术核心:DeepEncoder + MoE 解码器
DeepSeek-OCR 由两部分组成:
1. DeepEncoder:专为高压缩设计的视觉编码器
- 结合 SAM(局部感知) + CLIP(全局知识);
- 中间加入 16× 卷积压缩模块,将 4096 个 patch token 压到 256 个;
- 支持 多分辨率输入(从 512×512 到动态拼接的“高达模式”Gundam);
- 激活内存低、token 数少、适合高分辨率文档。
💡 设计哲学:先用窗口注意力处理细节,再用全局注意力提炼语义,中间“瘦身”降本增效。
2. DeepSeek-3B-MoE 解码器
- 采用 Mixture-of-Experts 架构,激活参数仅 570M;
- 能高效从压缩后的视觉 token 中“重建”原始文本;
- 保留强大语言能力,同时控制推理成本。
实测表现:不只是实验室玩具
DeepSeek-OCR 不仅理论漂亮,更是工业级利器:
- 每天可处理 20 万+ 页文档(单台 A100-40G);
- 支持 近 100 种语言(中、英、阿拉伯、僧伽罗等);
- 不仅能 OCR,还能 深度解析图表、化学式、几何图形(称为 “OCR 2.0”);
- 甚至具备 通用视觉理解能力:图像描述、目标检测、指代定位等。
✅ 一句话总结:它既是 OCR 工具,也是多模态数据工厂。
DeepSeek-OCR更深层意义:为 LLM 的“记忆机制”提供新思路
论文大胆提出:这种光学压缩,可以模拟人类的“遗忘机制”。
- 最近的对话 → 高分辨率图像 → 高保真记忆;
- 久远的历史 → 逐步缩小图像 → token 减少、文本模糊 → 自然“遗忘”。
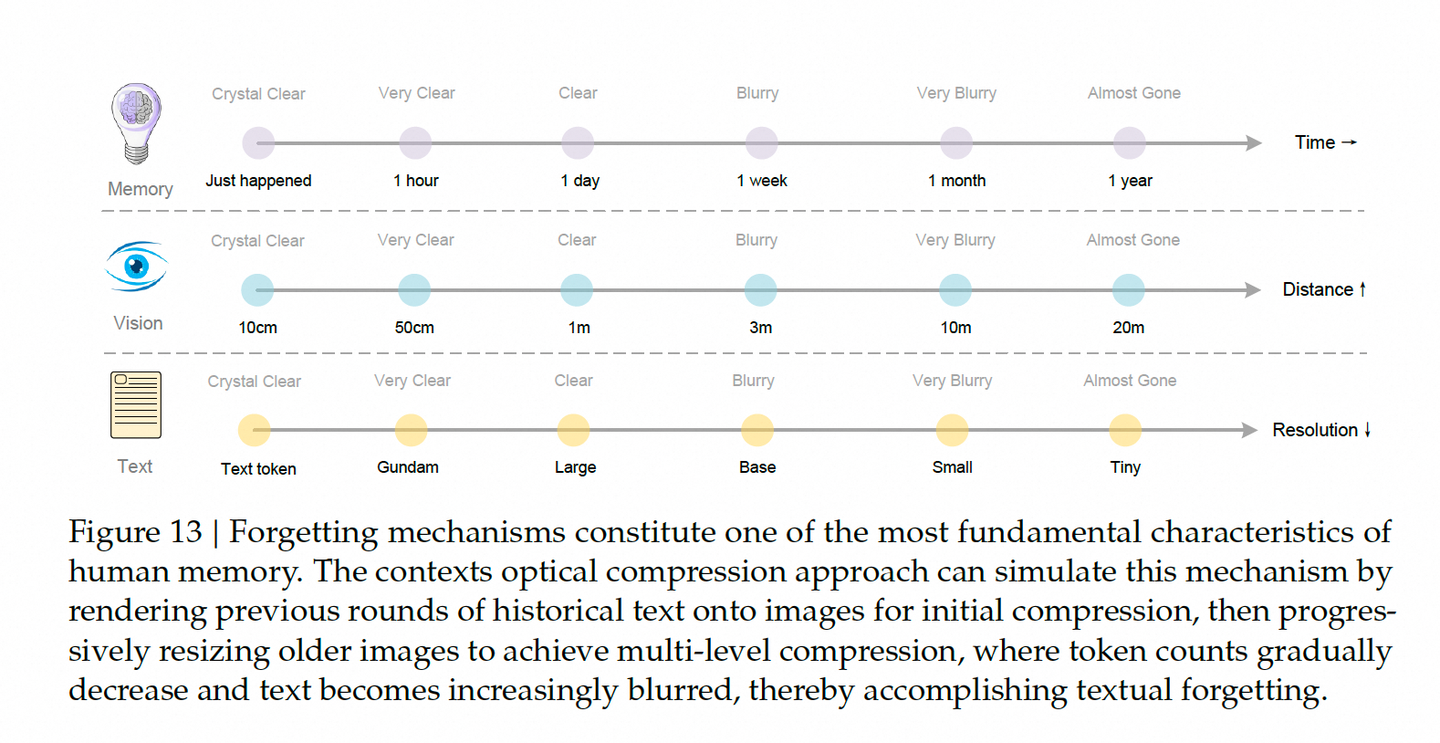
如图所示,时间越久,图像越小,信息越模糊——这不正是人脑的记忆曲线吗?
这为未来构建 “无限上下文” LLM 提供了新路径:用视觉做记忆分层,平衡信息保留与计算成本。
模型推理
在NVIDIA GPU上使用Huggingface transformers进行推理。测试环境为python 3.12.9 + CUDA11.8:
torch==2.6.0
transformers==4.46.3
tokenizers==0.20.3
einops
addict
easydict
pip install flash-attn==2.7.3 --no-build-isolation
from modelscope import AutoModel, AutoTokenizer
import torch
import os
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
# infer(self, tokenizer, prompt='', image_file='', output_path = ' ', base_size = 1024, image_size = 640, crop_mode = True, test_compress = False, save_results = False):
# Tiny: base_size = 512, image_size = 512, crop_mode = False
# Small: base_size = 640, image_size = 640, crop_mode = False
# Base: base_size = 1024, image_size = 1024, crop_mode = False
# Large: base_size = 1280, image_size = 1280, crop_mode = False
# Gundam: base_size = 1024, image_size = 640, crop_mode = True
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)显存占用:
模型微调
ms-swift支持了对DeepSeek-OCR进行微调,训练和推理脚本参考:https://github.com/modelscope/ms-swift/tree/main/examples/models/deepseek_ocr
在开始微调之前,请确保您的环境已准备妥当。
pip install "transformers==4.46.3" easydict
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .如果您需要自定义数据集微调模型,你可以将数据准备成以下格式,并在命令行中设置`--dataset train.jsonl --val_dataset val.jsonl`,验证集为可选。
{"messages": [{"role": "user", "content": "<image>Free OCR."}, {"role": "assistant", "content": "..."}], "images": ["/xxx/x.jpg"]}
{"messages": [{"role": "user", "content": "<image><|grounding|>Convert the document to markdown."}, {"role": "assistant", "content": "xxx"}], "images": ["/xxx/x.jpg"]}示例微调脚本如下,显存占用为24GiB:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model deepseek-ai/DeepSeek-OCR \
--dataset 'AI-ModelScope/LaTeX_OCR:human_handwrite#20000' \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--freeze_aligner true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 4096 \
--output_dir output \
--warmup_ratio 0.05 \
--dataset_num_proc 4 \
--dataloader_num_workers 4训练完成后,使用以下命令对验证集进行推理:
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--load_data_args true \
--max_new_tokens 2048推送模型到ModelScope:
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'
结语:一张图,不只是图
DeepSeek-OCR 的野心,远不止于“更好的 OCR”。
它试图回答一个根本问题:
“对于 LLM 来说,文字是否必须以 token 形式存在?”
如果答案是否定的,那么 视觉,或许就是下一代长上下文处理的“压缩算法”。
未来,我们或许会看到:
- 对话历史被自动“绘制成图”存入记忆;
- 万页文档只需几百 token 就能被模型“读懂”;
- LLM 的上下文长度,不再受限于显存,而取决于“你能画多清晰的图”。
这,或许就是 多模态智能的下一程。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献966条内容
已为社区贡献966条内容

所有评论(0)