
MemPrivacy 开源:让端云 Agent 记住你,但不把隐私交出去
Agent 真正进入日常工作流之后,一个问题越来越绕不开:它想要更懂你,就需要长期记忆;它一旦拥有健康、地址、邮箱、凭证、消费记录这些私人信息,就可能跟着记忆一起流向云端。
OpenAI 两周前开源发布了 openai/privacy-filter 隐私过滤模型,“Agent 记忆里的隐私保护”已经不再是边缘问题,而是下一代端云协同架构必须补上的基础能力。
这两天,记忆张量的 MemPrivacy 正式开源,希望更好的帮助 AI 解决这个问题。让云端大模型继续拥有推理和记忆能力,但让真正敏感的数据尽量留在本地。
MemPrivacy 采用了本地可逆伪匿名化的方案:
- 端侧识别隐私,把敏感内容替换成带语义类型的占位符;
- 云端只看到占位符,继续完成推理、工具调用和记忆处理;
- 回复回到本地后,再由本地映射表恢复真实内容。
论文发布当天,MemPrivacy 即登上 Hugging Face Daily&Weekly Papers 榜首。
一、为什么不能只靠“打码”:隐私保护最难的地方,是别把 Agent 变笨
大多数隐私保护方案采用简单粗暴的方法:检测到敏感信息,就删掉,或者替换成 ***。
这在普通表单里可能够用。
但在 Agent 场景里,问题会立刻变复杂。Agent 不是只做一次文本清洗,它需要理解上下文、形成记忆、调用工具,还要在后续对话里持续提供个性化服务。
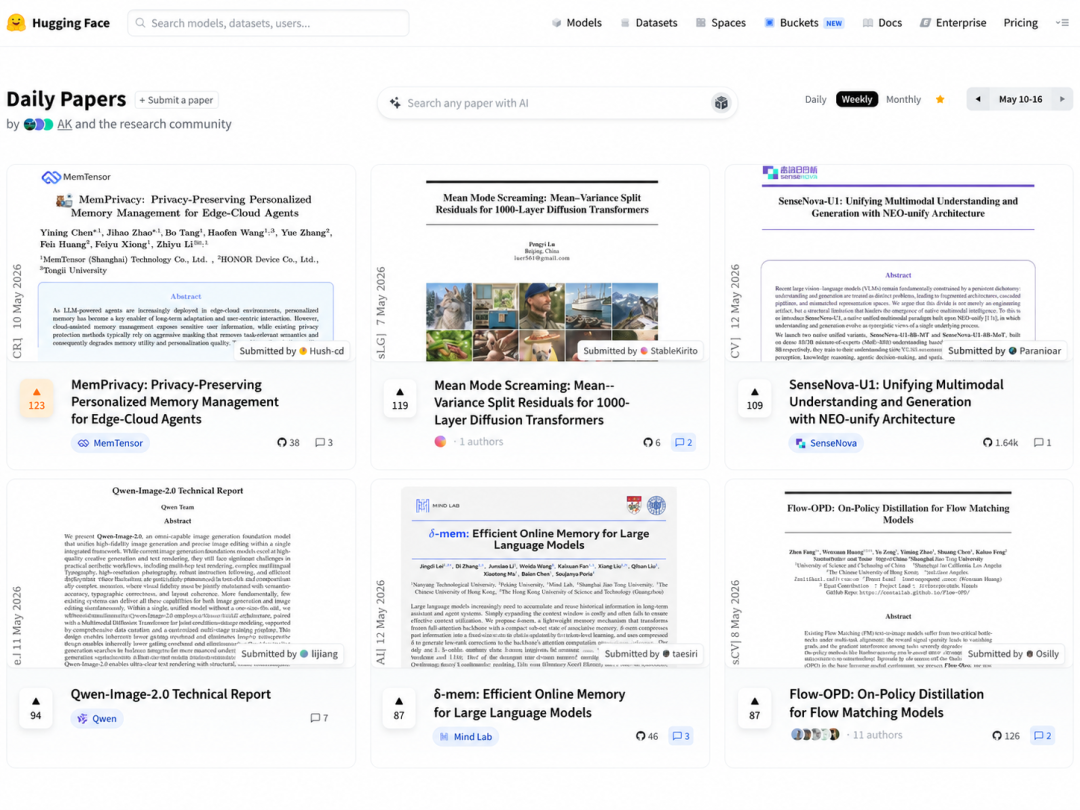
用户说:
我的血压今天是 160/110,帮我给医生写封简短邮件,发到 user@email.com。
如果完全不保护,云端 Agent 可以顺利写邮件,但血压值和私人邮箱都会进入云端上下文。
如果直接打码,句子可能变成:
我的血压今天是 ***,帮我给医生写封简短邮件,发到 ***。
隐私确实少了,但 Agent 也懵了:这是血压?金额?订单号?邮箱?它很难继续完成一个高质量的个性化任务。
MemPrivacy 希望走中间路线:
我的血压今天是 <Health_Info_1>,帮我给医生写封简短邮件,发到 <Email_1>。
云端看不到真实血压和邮箱,但仍然能理解这是一条健康信息和一个邮箱地址。它可以继续起草邮件、保留任务逻辑,本地再把占位符恢复成真实内容。
简单来说,就是把“钥匙”和“标签”分开:云端只拿到标签,本地才保留钥匙。
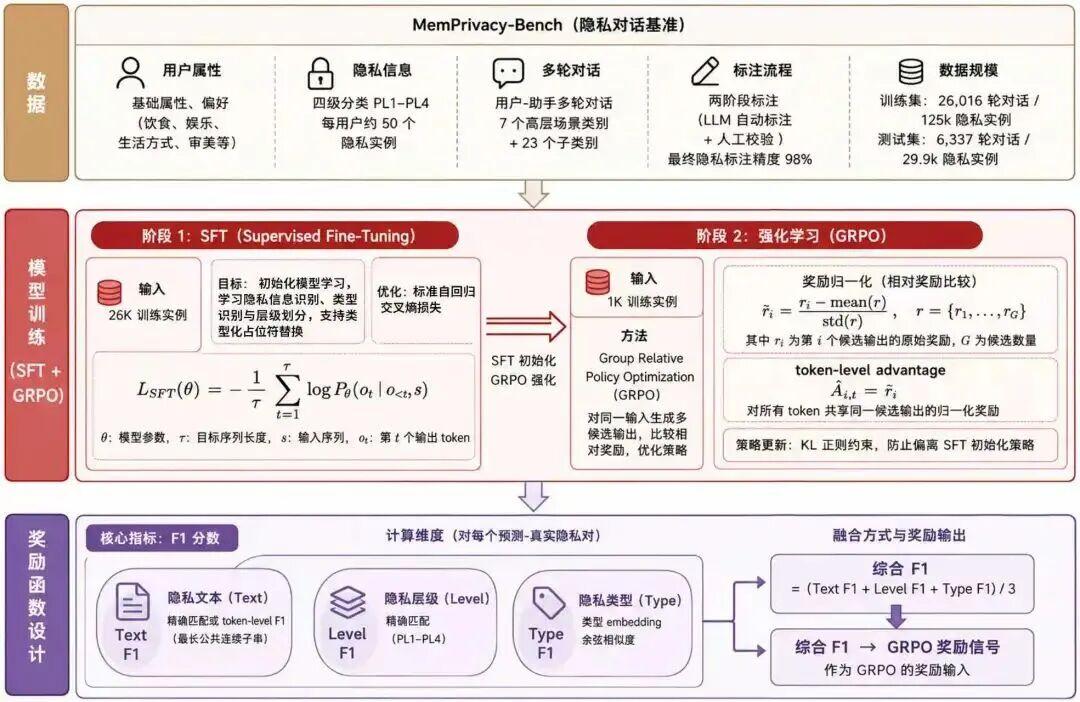
二、MemPrivacy 怎么跑起来:端侧脱敏、云端处理、本地恢复
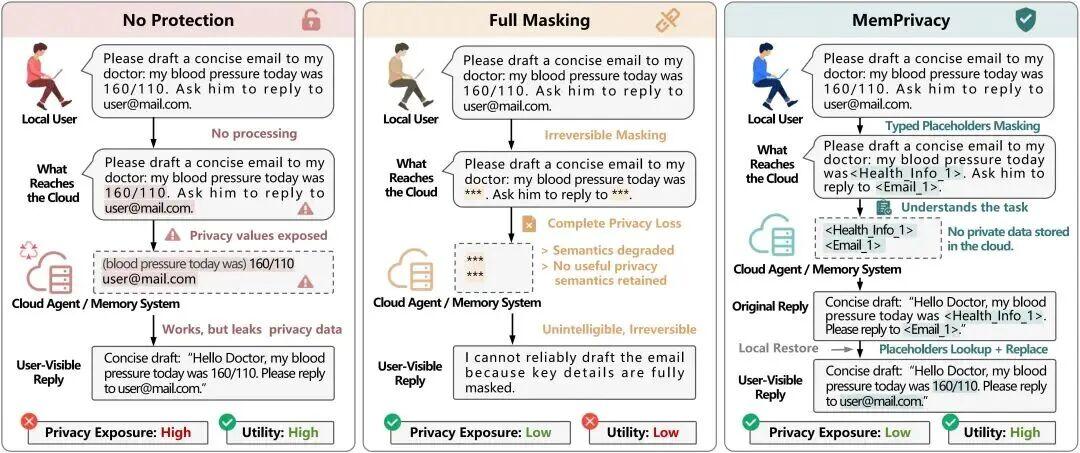
MemPrivacy 的核心流程分为三步。
2.1 端侧上行脱敏:敏感内容先在本地过一遍
用户输入会先经过本地的 MemPrivacy 模型。模型负责识别对话中的隐私片段,并根据保护层级判断哪些内容需要替换。
触发保护阈值后,真实文本会被替换成带语义类型的占位符,例如:
我的血压今天是 160/110 ↓我的血压今天是 <Health_Info_1>
真实值和占位符的映射关系保存在本地安全数据库中。
这一步像寄快递前先把身份证号和手机号从面单上拆下来,云端物流系统还能知道“这里有一个收件人联系方式”,但看不到真实号码。
2.2 云端安全处理:云端只处理占位符,不接触明文隐私
云端 Agent 收到的是已经脱敏的文本。
因为占位符保留了语义类型,Agent 仍然能理解句子结构和任务意图。它知道 <Health_Info_1> 是健康信息,<Email_1>是邮箱,不会把所有敏感内容都当成同一种东西。
这对长期记忆很关键。
它看不到 160/110 这个明文敏感数据,但依然知道这里是一个健康指标,因此可以继续进行推理、生成建议、形成记忆,甚至调用相关工具。
2.3 端侧下行恢复:回复后,本地再还原
云端生成回复后,如果其中包含占位符,本地系统会通过映射表恢复真实内容。
云端:您的血压 <Health_Info_1> 偏高 ↓本地:您的血压 160/110 偏高整个过程对用户来说是透明的,用户看到的是完整回复,云端看到的是经过类型化保护后的上下文。
三、四级隐私分类:不是所有“个人信息”都要用同一种力度保护
隐私不是非黑即白。
“我喜欢科幻片”和“我的 API Key 是 xxx”都跟个人有关,但风险完全不同。前者可能是个性化推荐需要的偏好,后者一旦泄露就可能造成账户接管或系统越权。
MemPrivacy 引入了以可识别性、潜在危害性与可利用性为准绳的四级隐私分类法 (PL1-PL4),从而支持用户根据需求自由调控脱敏阈值:
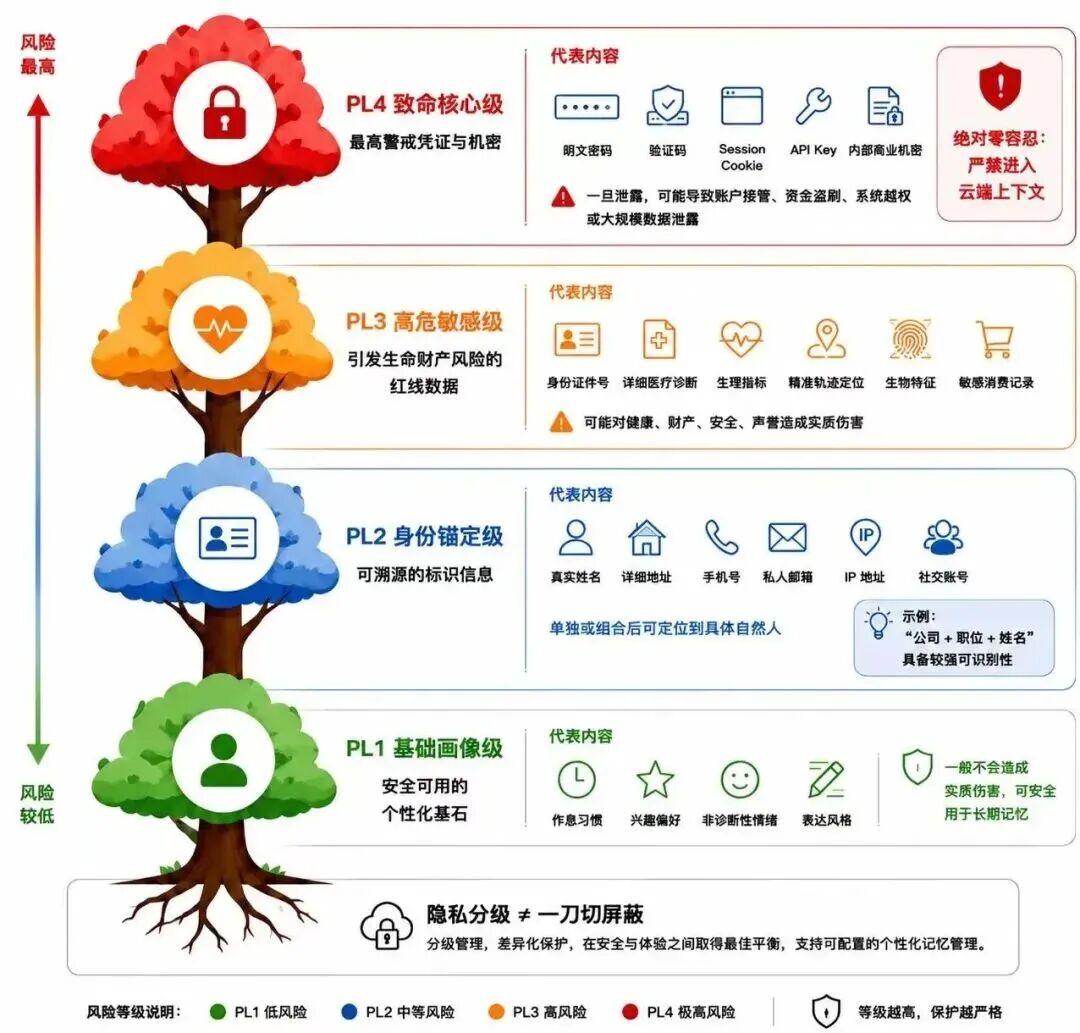
PL4:凭证与机密,最高优先级保护
这一层是最高风险信息,一旦泄露就可能带来直接损失。
包括明文密码、验证码、Session/Cookie 令牌、API Key、内部商业机密等。一旦泄露,可能导致账号接管、资金盗刷、系统越权或数据大规模暴露。
这类信息不适合进入云端上下文。
PL3:高危敏感信息,涉及健康、财产、安全和声誉
这一层是不能轻易公开的深层隐私,不一定能单独定位一个人,但被滥用后可能造成健康、财产、安全或声誉损害。
比如详细医疗诊断、生理指标、精准轨迹定位、生物特征、敏感消费记录等。
PL2:可识别身份信息,能定位到具体个人
PL2 主要是直接或间接定位自然人的标识信息。
真实姓名、详细收货地址、手机号、私人邮箱、IP 地址、社交账号等,都属于这一层。
还有一些组合信息也需要保护,比如“公司 + 职位 + 姓名”。单看每个字段可能不敏感,合起来就能把人锚定出来。
PL1:基础画像信息,保留个性化所需的低风险记忆
PL1 是低风险、但对个性化很有价值的信息。
比如,我每天早上 6 点跑步,我喜欢看科幻片,我偏好简洁一点的回复风格等
这类信息通常不需要脱敏。因为它们对 Agent 的个性化体验很重要,又不会直接造成严重隐私风险。MemPrivacy 会把这类信息作为安全可用的记忆基础,而不是全部清掉。
“我今天在超市花了 86 元”和“我在某医疗场景下产生了特定消费记录”,都涉及消费,但风险等级不一样。
前者可能只是普通生活偏好,后者可能关联健康状态,需要进入 PL3。MemPrivacy 希望模型能区分这种边界,而不是看到“金额”两个字就一刀切。
四、评测结果:准确率超过 OpenAI,几乎不损失系统效用
在隐私信息处理中,隐私检测尤为重要。漏掉敏感信息,是泄露风险。误杀太多上下文,是可用性损失。
为此,官方构建了 MemPrivacy-Bench,覆盖 200 个用户的对话历史、超过 15.5 万个隐私项,并包含中英双语隐私信息检测场景。同时,团队还在 PersonaMem-v2 上做了分布外测试,用来观察模型在陌生场景下的泛化能力。
4.1 隐私提取准确率
在隐私文本、隐私级别、隐私类型的综合 F1 指标上,结果可见:
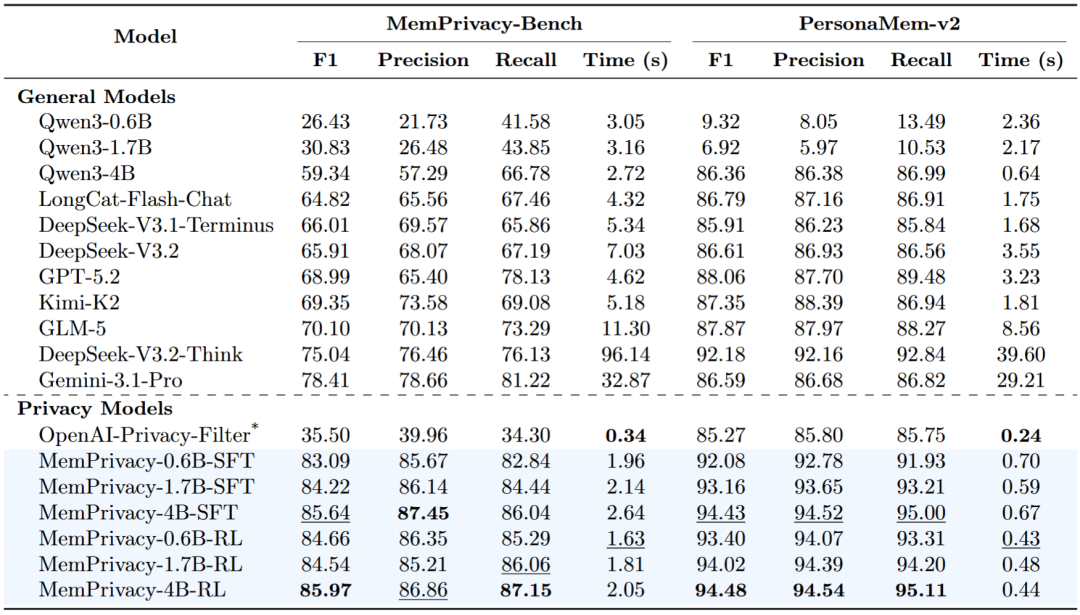
远超 OpenAI 专项模型:
在 MemPrivacy-Bench 上,OpenAI privacy-filter 的综合 F1 分数只有 35.50%。而 MemPrivacy-4B-RL 达到了 85.97%,两者差距高达50.47%!
在跨分布的 PersonaMem-v2 数据集上,MemPrivacy 依然领先 OpenAI 近 9%。
越级挑战通用大模型:
即使面对参数量极其庞大的最强通用模型 GPT-5.2、Gemini-3.1-Pro 以及 DeepSeek-V3.2-Think,MemPrivacy-4B 乃至仅有 0.6B 的微型版本在两个数据集上均实现了碾压。
这说明,隐私提取不是简单堆大参数就能解决的问题。真正重要的不是模型有多大,而是它是否理解「什么信息该被保护、该保护到什么程度、保护后还能不能继续被 Agent 使用」。
4.2 系统效用损失
隐私保护方案还面临一个更重要的问题:保护之后,Agent 会不会变笨?
官方在几个主流记忆系统平台上做了端到端测试,底座统一采用 GPT-4.1。
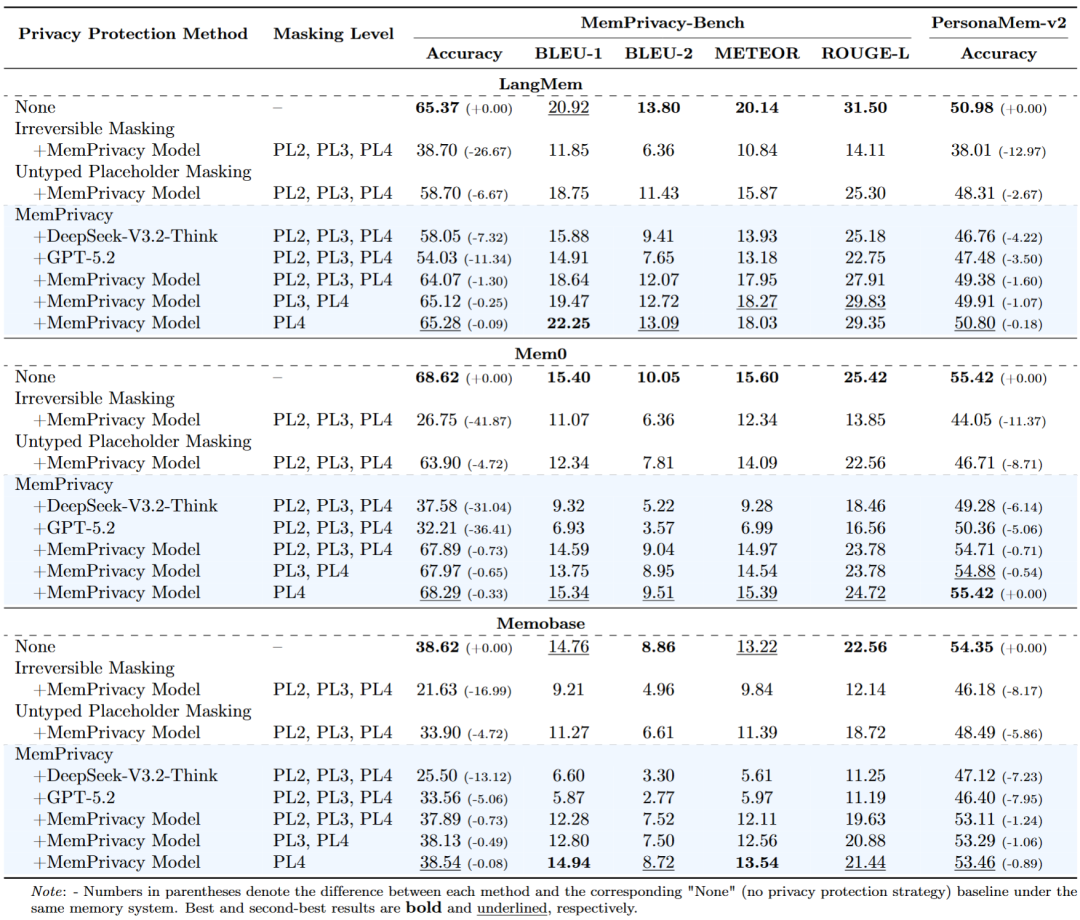
实验结果如下:
- 当采用传统的不可逆掩码(Irreversible Masking)时,三大记忆系统的准确率分别暴跌了 26.67%、41.87% 和 16.99%,模型几乎处于失忆状态。
- 而在 MemPrivacy 保护下(最高防御级别 PL4+PL3+PL2 全开),系统效用损失被死死控制在 0.71% ~ 1.60% 之间。如果用户仅选择保护最高风险的凭证级隐私(PL4),准确率下降甚至不到 0.89%。
MemPrivacy 真正做到了在不伤害智能体智商的前提下,把隐私泄漏风险降到了最低。
五、训练策略:先学会定位隐私,再学会拿捏边界
MemPrivacy 模型基座采用 Qwen3 系列,覆盖 0.6B / 1.7B / 4B 多个规格。
训练分成两个阶段:
5.1 SFT:让模型先掌握基础的识别与替换能力
第一阶段使用 26K 多轮对话数据进行监督微调。
这一步像教一个新同事看隐私标注规范:哪些是健康信息,哪些是身份标识,哪些是凭证,哪些低风险偏好可以保留。
没有这一步,模型很难稳定输出结构化的隐私片段和占位符。
5.2 GRPO:让模型在模糊边界上做得更稳
第二阶段引入 GRPO 强化学习,通过输出组的相对比较,以及提取结果 F1 分数形成结构化 Reward,继续优化模型策略。
隐私边界经常不是标准答案题。
“我在公司附近租房”可能只是普通生活信息;“我在某公司某部门负责某系统,并附带内网地址”就可能变成高风险组合信息。
强化学习阶段希望提升的,就是这类边界场景下的召回和精确率平衡能力。
写在最后
大模型比你更懂自己已经是趋势,但「比你更懂你」不意味着「让云端看光你」。这是 MemPrivacy 想要解决的问题。
它不是一套通用 PII 清洗工具,而是为端云协同 Agent 设计的专属隐私层——让真正的敏感数据留在本地,让推理和记忆继续发生在云端。这两件事过去经常被当作 trade-off,希望从今天开始,它们不必再是 trade-off。
目前,MemPrivacy 的模型权重和评测基准已全部开源。
相关链接
- 论文:https://arxiv.org/pdf/2605.09530
- 代码: https://github.com/MemTensor/MemPrivacy
- 模型:https://www.modelscope.cn/collections/MemTensor/MemPrivacy

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献966条内容
已为社区贡献966条内容

所有评论(0)