
35B参数科学性能比肩万亿参数模型,『书生』科学大模型Intern-S2-Preview开源
继率先推出首个万亿参数科学大模型『书生』Intern-S1-Pro,上海人工智能实验室(上海AI实验室)于5月15日开源了新一代大模型预览版
Intern-S2-Preview,进一步拓展“可深度专业化通用模型”的能力边界并大幅降低使用门槛。其重要突破包括:
尺寸更小:以35B参数规模,实现在多个核心领域比肩万亿参数模型的能力;
科学能力更强,结构生成能力突破:科研团队通过提升任务难度及多样性,增强了小参数模型在复杂科学任务中的表现效果;例如,通过引入实数预测模块,首次在开源通用大模型中实现了材料晶体结构生成能力。
科学智能体能力领先,可更好地服务真实科研场景:不仅在综合科学场景编程任务中达到同量级领先水平,还在科学发现任务中超越Claude-Haiku-4.5、GPT5.4-Nano等主流闭源模型。
同时,Intern-S2-Preview 深化与昇腾算力生态的协同,在训练、推理与评测等关键环节实现全流程优化,进一步验证国产软硬件协同体系在科学大模型方向上的价值。
体验链接:
https://chat.intern-ai.org.cn/
GitHub:
https://github.com/InternLM/Intern-S1
ModelScope:
https://modelscope.cn/collections/Shanghai/_AI/_Laboratory/Intern-S2
探索任务Scaling和强化学习,加速实现“通专融合”
将万亿参数规模的科学多模态大模型浓缩为高效、易用的基座模型,是一项极具挑战的工作。其实现路径的核心思路,来自上海AI实验室对“通专融合”技术路线的持续探索。研究团队发现,模型能力进化并非仅依赖传统的参数扩容与数据增量外,通过提升任务难度、丰富任务多样性,亦可持续拉升模型能力上限,具备Scaling效应。
相较于Intern-S1-Pro,Intern-S2-Preview进一步将专业科学任务扩展为“全链路训练”范式:每一个专业科学任务均配备从预训练到后训练的高质量数据与训练策略,并依托稳定高效的训练基础设施,实现多任务融合训练。在这一过程中,当大量高难度、多样化任务进行统一融合训练时,小模型能够在多项科学任务上达到万亿参数模型的表现水平。这其中的关键在于全链路的“通专融合”机制:若仅优化单一训练阶段,往往会出现能力之间的“此消彼长”;而在全链路融合后,不同任务之间反而形成相互促进的协同效应,从而进一步释放模型在复杂科学任务中的整体潜力。
在此基础上,团队重点围绕强化学习开展多方面探索,赋能Intern-S2-Preview加速实现“通专融合”;
引导模型利用思维链来完成生物多组学理解等专业科学任务,依托思维链的泛化优势,实现以35B小参数模型比肩万亿参数模型的性能;
延长强化学习的训练步长,结合更加高难度(如研究生级别)的学科推理问题和专业科学任务,使得小模型能够在各类问题上得到充分训练,最终融会贯通,具备跨域推理能力;
在数据思维密度(IQPT,Intelligence Quality per token)理念指导下,探索思维链折叠等创新算法,通过构建数据思维密度杠杆,撬动模型性能提升。其中,在数学推理任务中,Intern-S2-Preview实现思维链长度极致压缩,但效果比肩参数量近300B的某最新模型,实现性能与效率的双重突破。
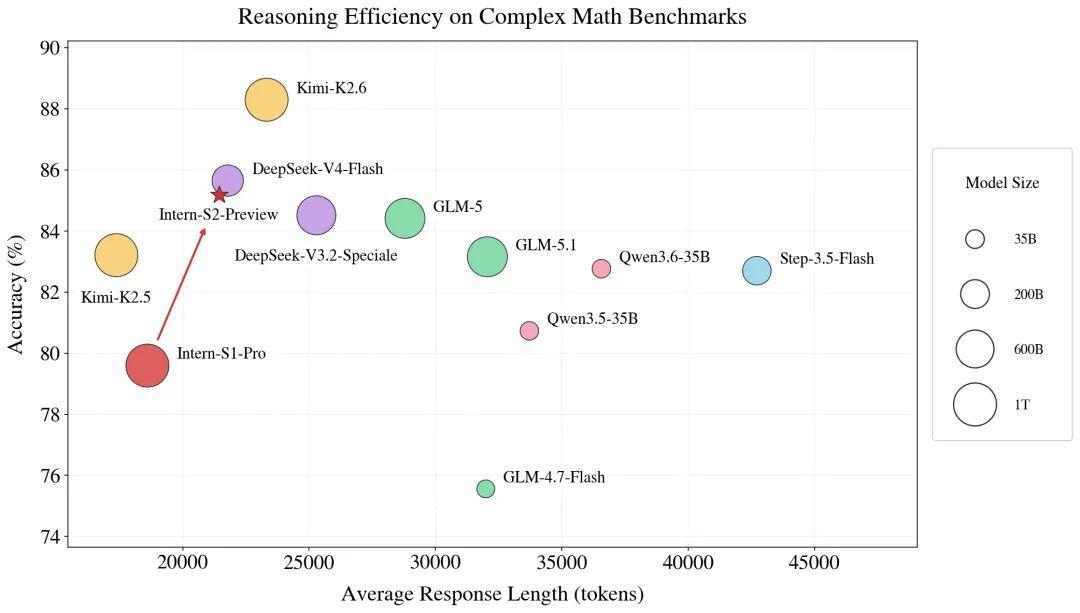
科学能力持续升级,比肩主流闭源模型
Intern-S2-Preview以赋能科学发现为核心目标,聚焦更复杂的科学场景开展探索。以小分子结构空间建模能力为例,其作为模型精准认知分子、晶体等微观结构的核心支撑,既决定了结构理解与生成的精度上限,也是适配复杂科研场景的基础。科研团队在此前引入傅里叶位置编码(FoPE)、重构时序编码器等创新的基础上,进一步强化该能力,并引入实数预测模块,首次在开源通用大模型中实现了材料晶体结构生成能力。
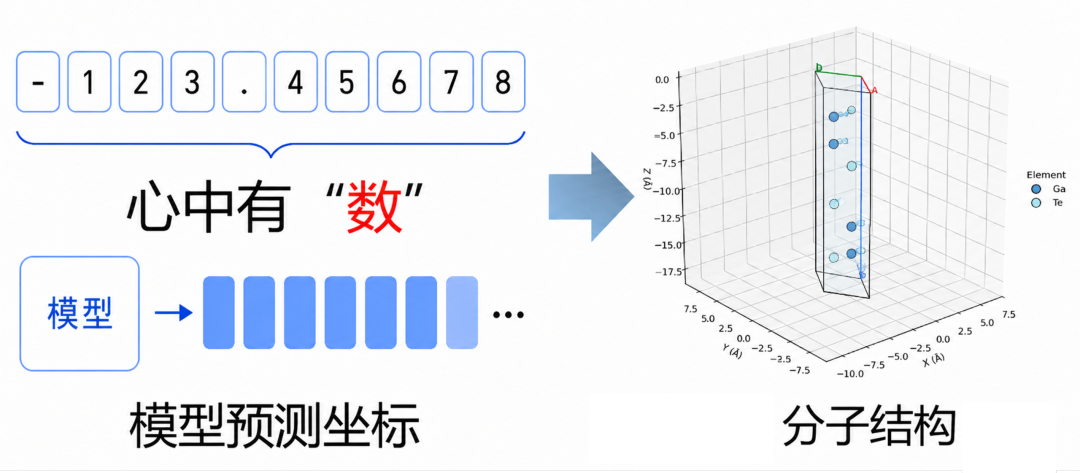
为精准验证这一能力,团队选取MolecularIQ评测集开展专项测试——该评测集重点考察模型对分子内部结构的空间建模与拓扑理解能力,相比传统仅通过分子式构成即可完成的任务,挑战性显著提升。评测结果显示:Intern-S2-Preview在MolecularIQ上取得57.26分,超过Gemini-3.1-Pro的41.33分。
如果说结构理解主要服务于科研中的分析与筛选环节,那么结构生成则是推动科研创新的“创造性任务”。其中,材料晶体结构生成领域此前长期依赖专业模型,而Intern-S2-Preview不仅填补了开源通用大模型在该领域的空白,也是首个能给出思考过程的结构生成模型。该任务需要模型生成数十个高精度的空间坐标以描述材料晶体结构,GPT-5.5等闭源模型生成的结构通过率约为10%,而Intern-S2-Preview的通过率超40%,显著提升了结构生成质量与可用性,为科研创新提供高效支撑。
通过上述创新,Intern-S2-Preview在无需依赖扩散模型的前提下,仍具备高精度坐标回归的潜力,这不仅降低了相关任务的实现成本,更为各类坐标回归类科研任务提供了全新的技术解决方案。
科学智能体能力升级,高效支撑复杂科研任务
得益于训练阶段引入系统化任务合成方法,Intern-S2-Preview通用智能体能力得到进一步提升。团队依托开源社区技能仓库与真实工具生态,构建贴近实际应用场景的高质量智能体训练数据,重点强化模型对复杂任务的步骤拆解、技能调用与自主执行能力,有效拓宽了从多轮对话到复杂任务规划、自主落地执行的能力边界。
在真实沙盒环境长程任务求解场景中,Intern-S2-Preview在PinchBench等通用智能体评测基准中展现出稳健的任务理解、工具调用、多步决策与状态追踪能力,能够在动态环境中持续完成任务执行,并根据环境反馈进行自我修正。同时,凭借持续增强的科学推理能力,Intern-S2-Preview在面向科学编程与算法求解的SciCode基准上表现优异,位居同量级模型前列,具备强劲的科学代码生成能力,可高效支撑科学计算、算法开发与科研脚本编写等复杂科研任务。
“算法-系统-算力”协同演进,提升训推效率
科研团队围绕模型训练、推理部署与自动化评测进行了系统优化,通过“算法-系统-算力”协同演进提升训推效率。
在昇腾A3超节点上,训练框架引入多项显存与内存优化技术,提升多模态长序列训练稳定性。同时针对变长输入场景优化计算流程,通过提前规划数据分块、减少主机与设备间的数据交互等,进一步提升整体计算效率。
在训推一体化方面,基于训练框架XTuner与部署推理框架LMDeploy,团队在支持多token预测强化学习的基础上,引入共享权重计算方式,减少训练与推理之间的不一致,同时提升生成结果的有效性,使训练更稳定、推理更高效。
针对多模态长序列训练中视觉模块耗时占比过高的问题,团队通过离线模拟不同序列长度下视觉与语言模块的算力占比,实现更均衡的资源分配,从而进一步提升整体训练效率。
自2023年书生大模型首次发布以来,上海AI实验室已逐步构建起丰富的书生大模型家族。同时首创并开源了面向大模型研发与应用的全链路开源工具体系,包含训练框架 XTuner、部署推理框架 LMDeploy、创新开放评测体系OpenCompass、智能文档解析引擎MinerU,形成覆盖数十万开发者参与的活跃开源社区。
自发布以来,Intern-S1多次登顶 HuggingFace 全球多模态榜单,累计下载量超过100万次。其卓越的跨模态科学理解能力不仅为科研提供了高效工具,也通过开源降低了全球科研团队迈入AGI for Science的门槛。未来,上海AI实验室将继续推动模型能力提升与科研范式创新,与全球合作伙伴共同构建更加开放、高效的科学AI生态。

欢迎扫码加入体验交流群
ModelScope API Inference体验
魔搭社区ModelScope 目前提供了限时限量免费的 Intern-S2-Preview API-Inference服务,欢迎大家体验~
https://modelscope.cn/models/Shanghai/_AI/_Laboratory/Intern-S2-Preview

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献966条内容
已为社区贡献966条内容

所有评论(0)