
智谱旗舰模型GLM-4.6开源发布,代码能力对齐Claude Sonnet 4
GLM,也来啦!就在今天,智谱AI开源发布了GLM-4.6。
作为GLM系列的最新版本,GLM-4.6是系列最强的代码Coding模型(较GLM-4.5提升27%)。在真实编程、长上下文处理、推理能力、信息搜索、写作能力与智能体应用等多个方面实现全面提升。如下:
- 高级编码能力:在公开基准与真实编程任务中,GLM-4.6的代码能力对齐Claude Sonnet 4,是国内已知的最好的Coding模型;
- 上下文长度:上下文窗口由128K→200K,适应更长的代码和智能体任务;
- 推理能力:推理能力提升,并支持在推理过程中调用工具;
- 搜索能力:增强模型的工具调用和搜索智能体,在智能体框架中表现更好;
- 写作能力:在文风、可读性与角色扮演场景中更符合人类偏好。
GLM-4.6已上线智谱MaaS平台http://bigmodel.cn,已经在Hugging Face、ModelScope开源,遵循MIT协议。
代码仓库:
https://github.com/zai-org/GLM-4.5
模型链接:
https://www.modelscope.cn/models/ZhipuAI/GLM-4.6
技术博客:
https://z.ai/blog/glm-4.6
Coding能力创国产模型新高
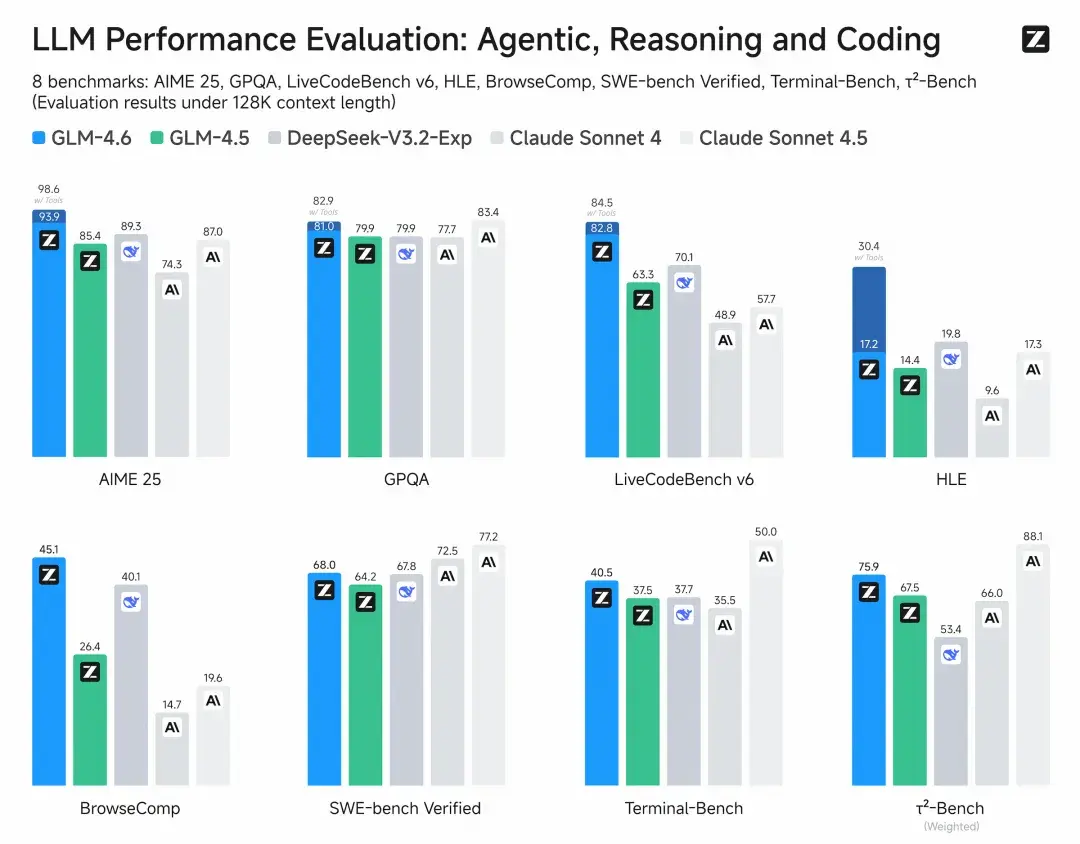
1. 综合评测
在8大权威基准:AIME 25、LCB v6、HLE、SWE-Bench Verified、BrowseComp、Terminal-Bench、τ^2-Bench、GPQA 模型通用能力的评估中,GLM-4.6在部分榜单表现对齐Claude Sonnet 4/Claude Sonnet 4.5,稳居国产模型首位。
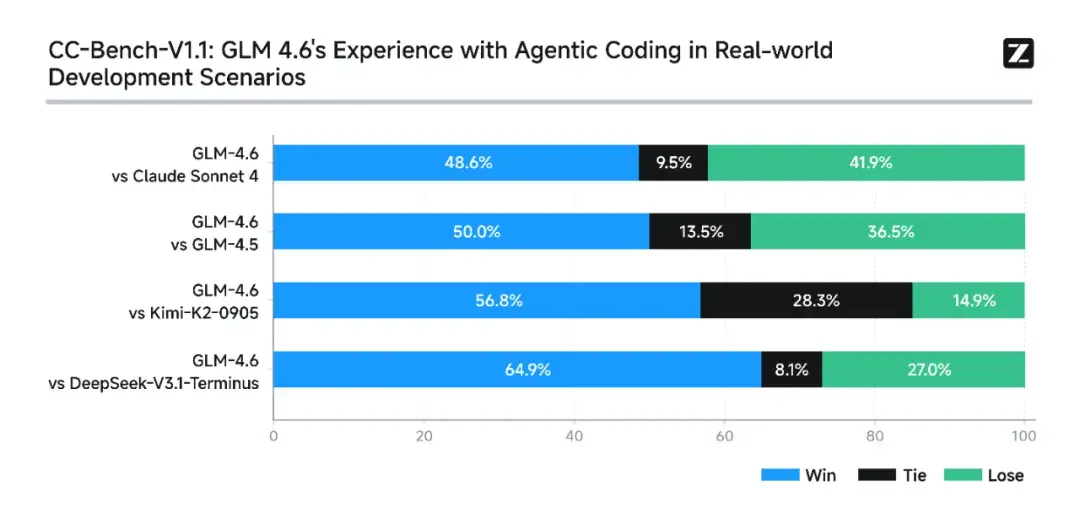
2. 真实编程评测
为了测试模型在实际编程任务中的能力,我们在Claude Code环境下进行了74个真实场景编程任务测试。结果显示,GLM-4.6实测超过Claude Sonnet 4,超越其他国产模型。
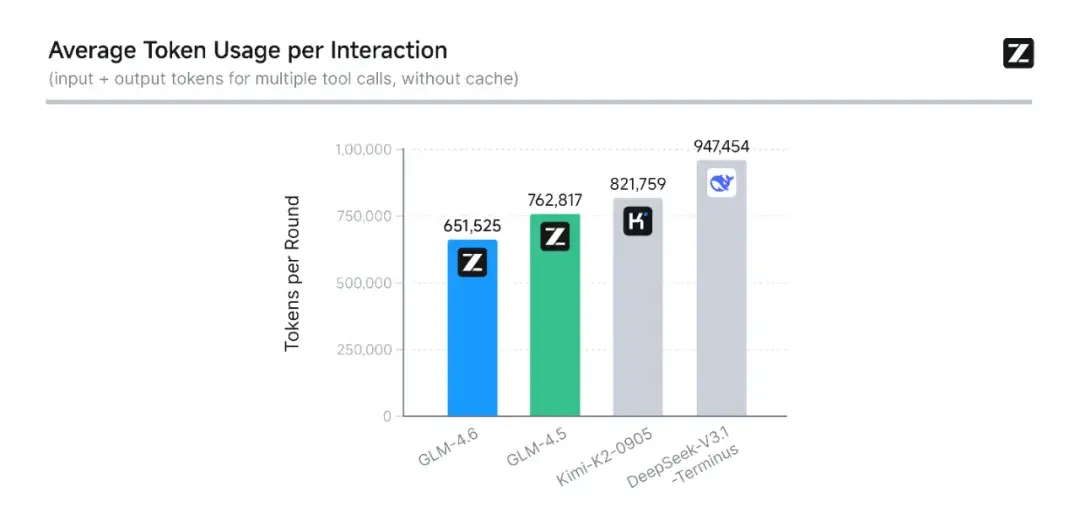
在平均token消耗上,GLM-4.6比GLM-4.5节省30%以上,为同类模型最低。
为确保透明性与可信度,智谱已公开全部测试题目与Agent轨迹,供业界验证与复现。
数据集:
https://www.modelscope.cn/datasets/ZhipuAI/CC-Bench-trajectories
GLM-4.6的上一代模型GLM-4.5首次在单个模型中实现将推理、编码和智能体能力原生融合。GLM-4.5在代码能力上的突出表现让其取得一些成绩,在OpenRouter上稳居全球前十供应商,自发布后智谱MaaS平台API商业化实现10倍以上增长。
模型推理上,GLM-4.5 和 GLM-4.6 都使用相同的推理方法
GLM-4.6www.modelscope.cn/models/ZhipuAI/GLM-4.6

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐

 0
0 0
0- 0



 已为社区贡献993条内容
已为社区贡献993条内容

所有评论(0)