
SkyJM-Edit 重磅开源|让图像编辑裁判模型"看懂指令再打分",效果刷新公开榜单
SkyJM-Edit (RubricRM-Edit)是一款面向指令式图像编辑(Instruction-based Image Editing)的生成式裁判模型,该模型基于 Qwen3.5训练。模型在推理过程中会针对每条编辑指令动态生成一份评分 Rubric,该Rubric包含指令对齐、源图保留、视觉质量等维度,同时模型会针对Rubric的评测维度和权重输出逐维度的分数和最终的加权分数结果。
在 MMRB2 / EditReward-ERB / EditScore-ERB 三个公开图像编辑评估基准上,SkyJM-Edit-9B 全面领先现有专用奖励模型(EditReward-7B、EditScore-7B),并在 EditScore-ERB 各细分指标上接近甚至超过 Gemini 3.1 Pro。
🔥 关键数字一图速览
| 模型 | MMRB2 | EditReward-ERB(Avg) | EditScore-ERB(Avg) |
| EditReward-7B | 67.2 | 38.4 | 78.3 |
| EditScore-7B | 55.6 | 28.8 | 61.9 |
| Gemini 3.1 Pro(闭源 MLLM) | 74.9 | 45.0 | 81.6 |
| SkyJM-Edit-4B(Ours) | 73.2 | 45.5 | 85.5 |
| SkyJM-Edit-9B(Ours) | 75.4 | 46.4 | 85.6 |
在 EditScore-ERB 上,SkyJM-Edit-9B Avg = 85.6,比最强闭源 MLLM 评审 Gemini 3.1 Pro(81.6)高 4.0 分;比专用奖励模型 EditReward-7B(78.3)高 7.3 分。
开源地址:
- modelscope:
- https://www.modelscope.cn/models/SKYLENAGE/SkyJM-Edit-4B
- https://www.modelscope.cn/models/SKYLENAGE/SkyJM-Edit-9B
- github:https://github.com/SKYLENAGE-AI/SKYLENAGE-JUDGER
为什么图像编辑特别需要"动态 Rubric"?
图像编辑天然是一个多目标博弈问题:
- 指令遵从(Prompt Following):改的是不是指令要的东西;
- 源图保留(Consistency):没让改的部分有没有被误改;
- 视觉质量(Overall Quality):编辑后的图还能不能看。
不同指令对这三个目标的权重是不一样的:
- "把背景换成沙滩" → 背景编辑权重大、主体保留权重大;
- "给人物加一顶红帽子" → 指令对齐 / 物体添加权重大、面部不被误改的保留权重大;
- "把这张图改成水墨风" → 风格迁移权重大、像素级保留反而要适当让位;
- "把广告牌上的文字改为'限时五折'" → 文字渲染权重最大,字体走样属于难以容忍的错误。
现有专用奖励模型主要有两类:
- 判别式标量奖励(如 EditReward):在 20 万+ 编辑偏好对上训练,拟合得到一个"好坏分数",但没法说清"好在哪、差在哪";
- 生成式打分器(如 EditScore):用 MLLM 给出更高保真度的评分,但不指定每条指令的具体 Rubric 与权重。
SkyJM-Edit 的核心思路:让奖励模型对每条编辑指令"自己写一份评分量规再打分",把指令遵从、源图保留、视觉质量、风格迁移、文字编辑等该不该评、按多大权重评,从隐式经验变成显式输出。
动态 Rubric 范式:从"标量分"到"可解释偏好"
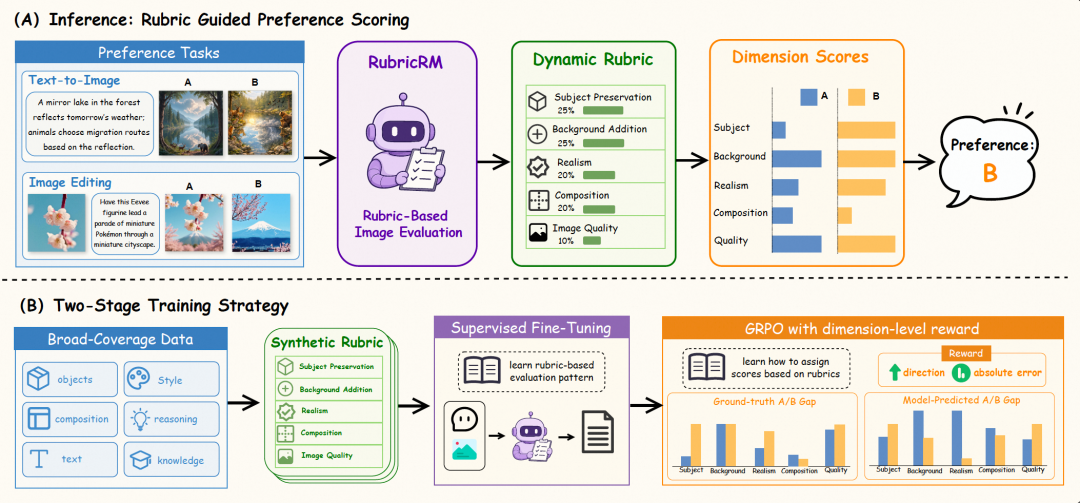
模型一次前向推理依次产出:
- Task Intent Analysis :对编辑指令的意图分析(要改什么 / 不能动什么 / 风格基调);
- 评估维度 + 权重 : 个维度 与权重 (满足 );
- 每个维度的分级标准 (0–4 分对应什么样的编辑结果);
- 对两张候选编辑结果逐项打分 ;
- 加权聚合得分 :

模型输出的最终偏好结果是通过比较S(I_A) 与 S(I_B) 的大小获得的。所有结果都是结构化的分数,可以详细查看模型的打分逻辑,你能看到模型在"指令对齐"上给了多少权重,又在"源图保留"上扣了多少分。
训练数据:覆盖 12 大类 30 子类
编辑数据本身就比纯文生图更"破碎":物体增删、颜色改变、背景切换、文字改版、风格转换、推理类编辑……每种子任务的评估重点完全不同。
训练数据统计
| 指标 | 数值 |
| 总样本对 | 30,695 |
| SFT / RL 拆分 | 15,695 / 15,000 |
| 一级 / 二级类目数 | 12 / 30 |
| 平均标签数 | 1.4 |
| 多标签样本占比 | 31.8% |
| 平均 Rubric 维度数 | 3.2 |
| A / B 偏好比 | 55.7 / 44.3 |
数据来源
- EditReward-Data:基于EditReward公开的 200K+ 编辑偏好对子集筛取;
- 不做合成补充:EditReward-Data 在编辑指令类目上本就相对均衡,我们直接基于其分布构造 Rubric 训练对,避免合成噪声引入额外偏置。
Rubric 轨迹合成:用人类偏好锚定teacher模型
为了既有结构化的 Rubric 轨迹、又不被teacher模型的偏好偏置污染,我们采用标签条件下的轨迹合成:
- teacher模型:Gemini 3.1 Pro;
- 合成时把人类偏好标签 y_j 一并喂给teacher模型,让它输出"任务意图分析 + 维度 & 权重 + 分级标准 + 逐维打分"五段式轨迹;
- 结构化校验:维度齐全、分数在 [0,4]、权重和 = 100%;
- 方向一致性校验:如果teacher模型轨迹的加权总分与人类偏好方向矛盾,整条样本丢弃。
teacher模型不再是"独立的偏好标注员",而是把人类偏好翻译成结构化 Rubric 的编排器。
编辑任务下 Rubric 关注什么?
把teacher模型生成的维度按语义聚合,可以看到编辑任务上 Rubric 天然覆盖了三大组:
- 指令 & 编辑(Instruction & Edit):Instruction Alignment、Object Edit、Text Editing、Attribute Edit;
- 保留(Preservation):Source Preservation(占比 20.9%,最高)、Subject Preservation;
- 场景融合 & 质量(Scene Integration / Quality & Realism):Background Edit、Visual Integration、Spatial Placement、Quality & Artifacts、Realism、Style Transfer。
Source Preservation维度占比最高(20.9%),这与"编辑必须不误伤无关内容"的常识完全一致,该结果是模型是在没有人类硬编码维度的前提下自己学到的。
两阶段训练:SFT 立"范式",GRPO 校"刻度"
Stage 1:Rubric Trajectory SFT — 学会"先写细则再打分"
输入 (source image, edit instruction, image_A, image_B),目标轨迹是teacher模型合成的完整结构化 Rubric。模型要同时掌握:
- 拆解编辑意图(改什么 / 不能动什么);
- 选择合适的维度并给出权重;
- 为每个维度写出 0–4 分的分级标准;
- 输出逐维打分并给出最终偏好。
Stage 2:维度级 GRPO — 让"维度上的偏好"也对齐
只判断最终偏好的奖励信号过于稀疏:两个 trajectory 哪怕维度打分一塌糊涂,只要最后选对了 A/B,最终奖励都是一样的。因此我们把奖励下沉到维度级。
为了让 rollout 的维度能与参考 trajectory 一一对应,我们在训练时固定 Rubric 部分(推理阶段仍由模型端到端生成 Rubric):
- 真值分差和预测分差定义 :,
- 方向因子 \phi_i :如果 则令 \phi_i = 1 ,如果并且 则令,如果 则令;
- 幅度因子;
- 总奖励 :。
上述公式这意味着不同的情况给予不同程度的惩罚,这种方案优先考虑方向是否正确,然后再奖励对分数差异的精确逼近。
实验结果
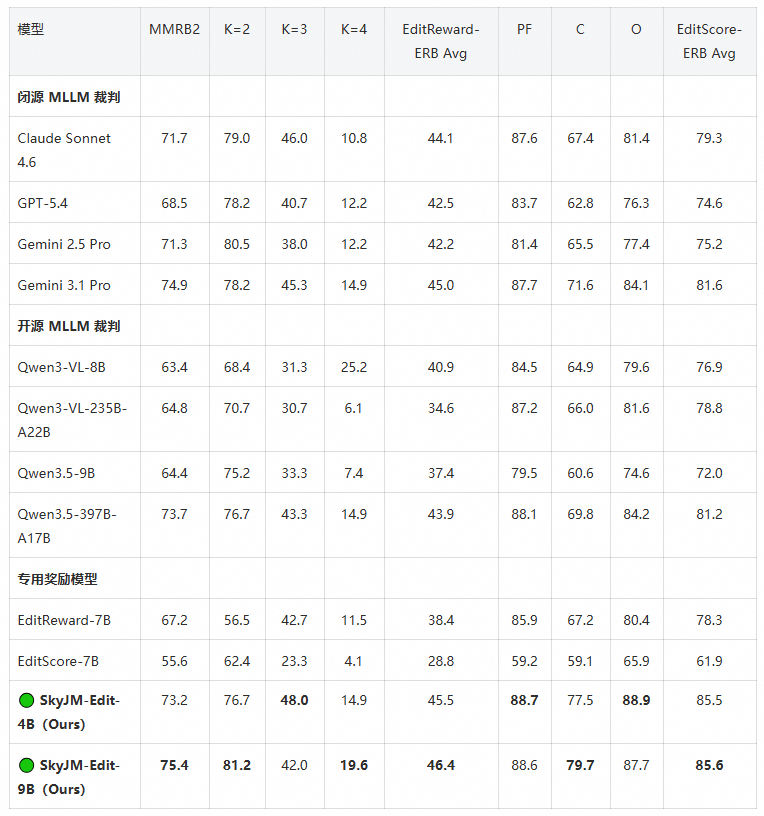
PF = Prompt Following,C = Consistency,O = Overall Quality;K=2/3/4 是 EditReward-ERB 的 K-way 偏好预测设置。
亮点:
- 9B 模型在 MMRB2(75.4)、EditReward-ERB Avg(46.4)、EditScore-ERB Avg(85.6)三项都登顶,全面领先现有专用奖励模型;
- MMRB2 上 SkyJM-Edit-9B(75.4)超过了 Gemini 3.1 Pro(74.9)和 Qwen3.5-397B-A17B(73.7);
- 在 EditScore-ERB 上,SkyJM-Edit 把 PF / C / O 三项指标同时拉高:4B 拿下 PF 88.7(最高)、O 88.9(最高),9B 拿下 C 79.7(最高),证明动态 Rubric 真的在同时平衡指令遵从、源图保留与视觉质量,而不是只优化某一个;
- SkyJM-Edit-4B 已经全面超越所有同级 baseline,甚至在 K=3、PF、O 这几个细分指标上反超 9B,说明小模型 + Rubric 范式能把容量花得很高效。
两阶段消融:SFT 立范式,RL 稳定再上一台阶
| 配置 | MMRB2 | EditReward-ERB | EditScore-ERB |
| Qwen3.5-4B(base) | 64.7 | 37.1 | 72.2 |
| + SFT | 71.5 ↑6.8 | 43.6 ↑6.5 | 83.3 ↑11.1 |
| + RL | 73.2 ↑1.7 | 45.5 ↑1.9 | 85.5 ↑2.2 |
| Qwen3.5-9B(base) | 64.4 | 37.4 | 72.0 |
| + SFT | 73.8 ↑9.4 | 45.0 ↑7.6 | 85.1 ↑13.1 |
| + RL | 75.4 ↑1.6 | 46.4 ↑1.4 | 85.6 ↑0.5 |
Rubric SFT 阶段贡献了绝大部分性能提升,这进一步说明:让模型学会"先写细则再打分"这件事本身,比只用偏好标签做监督更关键。维度级 GRPO 在此基础上对刻度进行校准。
Label-only vs Rubric-based SFT
我们把 Rubric 轨迹换成只用偏好标签的标准 SFT,结果显示:在 4B / 9B 两个 backbone 上,去掉 Rubric 监督会让 MMRB2 下降 2.3–4.6 分、EditReward-ERB 下降 4.2 分。实验结果表明收益不是来自"看了更多数据",而是来自"学会了 Rubric 这套评估范式"。
可解释性 Case:教学海报的"逐维点评"
Editing Instruction:为幼儿园教室制作一张以玩具飞机为主体的彩色教学海报,顶部加标题"Let's Learn About Airplanes!",左侧加事实"Airplanes travel high in the sky and can go really fast!",右侧加安全提示"Always fasten your seatbelt when flying!",底部加粗体写"Can you name the colors of this plane?"。
| 原图 | |
| Image1 | Image2 |
原图

Image1

Image2

模型对这条指令自动生成的 Rubric 与逐维打分(节选):
- Text Accuracy & Placement (40%):A 与 B 四段文字均存在、拼写正确、位置正确,底部均为粗体 → A 4/4,B 4/4
- Thematic Style & Aesthetics (30%):A 用云朵、放射状背景、卡通元素,更符合幼儿园海报风格;B 蓝天背景但整体风格偏一般 → A 4/4,B 3/4
- Content Preservation (30%):A 完美保留主体玩具飞机;B 在飞机上加了错误的"Black"标注,破坏了原图完整性 → A 4/4,B 2/4
加权总分:A = 4.00,B = 3.10 → 偏好 A。
这就是 Rubric 范式在编辑任务上的价值:你不再被动接受"A 比 B 好 0.9 分",而是看到模型究竟用什么权重在评估什么,"文字准确性"权重最大(40%),"风格"和"原图保留"各 30%。
本地部署
环境安装:
git clone https://github.com/SKYLENAGE-AI/SKYLENAGE-JUDGER
cd SKYLENAGE-JUDGER
uv venv .venv --python 3.11
source .venv/bin/activate
uv pip install -r requirements.txt
# For vllm backend
uv pip install "vllm>=0.19.0"模型下载:
modelscope download --model SSKYLENAGE/SkyJM-Edit-4B --local_dir SKYLENAGE/SkyJM-Edit-4B图像编辑推理脚本(4B模型):
# Image editing evaluation with 4B model
python run_inference.py \
--judge SkyJM-Edit-4B \
--model-path SKYLENAGE/SkyJM-Edit-4B \
--backend transformers \
--input edit_data.json \
--output result.jsonl
https://www.modelscope.cn/collections/SKYLENAGE/SkyJM

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献1005条内容
已为社区贡献1005条内容

所有评论(0)