
DSpark 开源:DeepSeek-V4 在线服务的投机解码框架,单用户生成速度提升 60%–85%,配套 DeepSpec 训练仓库一并开放
大模型在线服务的核心矛盾是:用户希望"出字越快越好",而生成本质上是一个 token 接一个 token 算出来的串行过程,单用户速度受限于一次 forward 的延迟。业界过去几年的常见解法叫"投机解码 (Speculative Decoding)"——再训一个小很多的草稿模型 (drafter) 一次猜几个 token,主模型只做"验证",猜对的就一次提交、猜错的丢掉。猜的越准、一次提交越多,用户感受到的速度就越快。
DeepSeek 联合北京大学开源的 DSpark 就是这套思路的最新工程化版本,目前已经替换 DeepSeek-V4 生产环境原有的 MTP-1 基线。它的两个核心组件是"半自回归生成"和"置信度调度验证"——前者让草稿模型既快又准,后者让验证阶段能根据当前 GPU 负载自动决定一次提交几个 token。
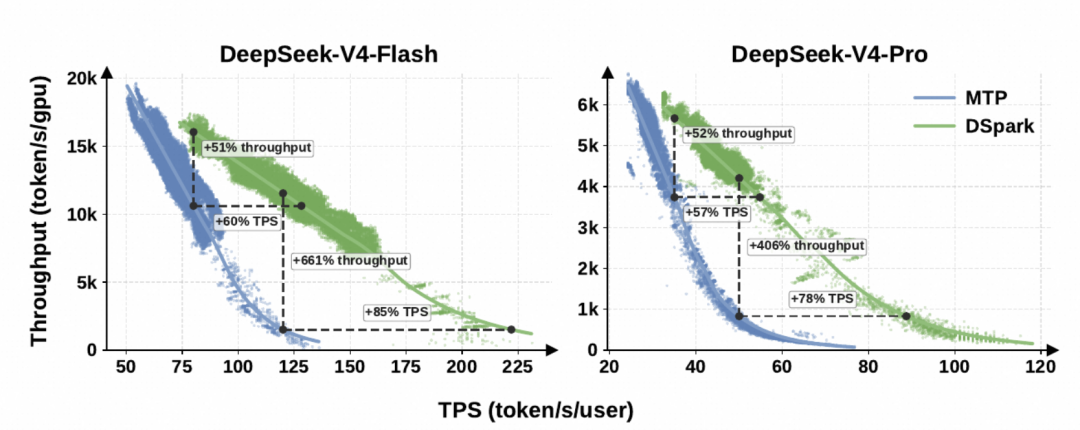
在 DeepSeek-V4 真实生产流量下,相同总吞吐下单用户生成速度 V4-Flash 提升 60%–85%、V4-Pro 提升 57%–78%,并能稳定支撑 V4-Flash 120 TPS、V4-Pro 50 TPS 这种此前 MTP-1 无法维持的严格交互档位。
开源地址:
- DeepSeek-V4-Pro-DSpark:https://modelscope.cn/models/deepseek-ai/DeepSeek-V4-Pro-DSpark
- DeepSeek-V4-Flash-DSpark:https://modelscope.cn/models/deepseek-ai/DeepSeek-V4-Flash-DSpark
- Github:https://github.com/deepseek-ai/DeepSpec
效果与指标
看这套方案到底快多少,要分两个层面:离线看草稿模型"一次能让主模型接受几个 token"( accepted length,越大越快);在线看在 GPU 总产出不变的前提下"用户那一端每秒能看到多少字"(TPS/user,最接近用户的真实感受)。
离线: accepted length(每轮解码平均接受 token 数)
| Target | Drafter | Math 均值 | Code 均值 | Chat 均值 |
| Qwen3-4B | Eagle3 | 4.56 | 3.87 | 2.40 |
| Qwen3-4B | DFlash | 4.80 | 4.44 | 2.95 |
| Qwen3-4B | DSpark | 5.57 | 5.12 | 3.49 |
| Qwen3-8B | DSpark | 5.65 | 5.28 | 3.50 |
| Qwen3-14B | DSpark | 5.63 | 5.24 | 3.47 |
| Gemma4-12B | DSpark | 5.65 | 5.09 | 3.25 |
横向比较:在 Qwen3-4B 上,DSpark 在 Math / Code / Chat 三个场景每回合分别比 Eagle3 多接受 1.0 / 1.2 / 1.1 个 token、比 DFlash 多 0.8 / 0.7 / 0.5 个 token;切到 Qwen3-8B / 14B / Gemma4-12B 上数字几乎不动,说明这个增益不挑底座。
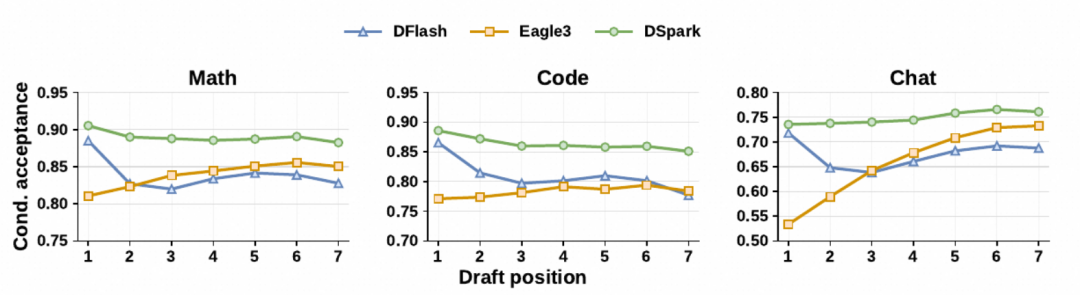
上图中横轴是草稿块里的位置 (1, 2, 3, …),纵轴是该位置被主模型接受的条件概率。并行草稿 (DFlash) 越靠后位置越容易猜错、曲线尾部塌;自回归草稿 (Eagle3) 第一个 token 就只能用小网络做、曲线头部低;DSpark 把两类草稿的优势合并,整条曲线都更平。
在线:DeepSeek-V4 真实生产流量下的表现(对比原有 MTP-1 基线)
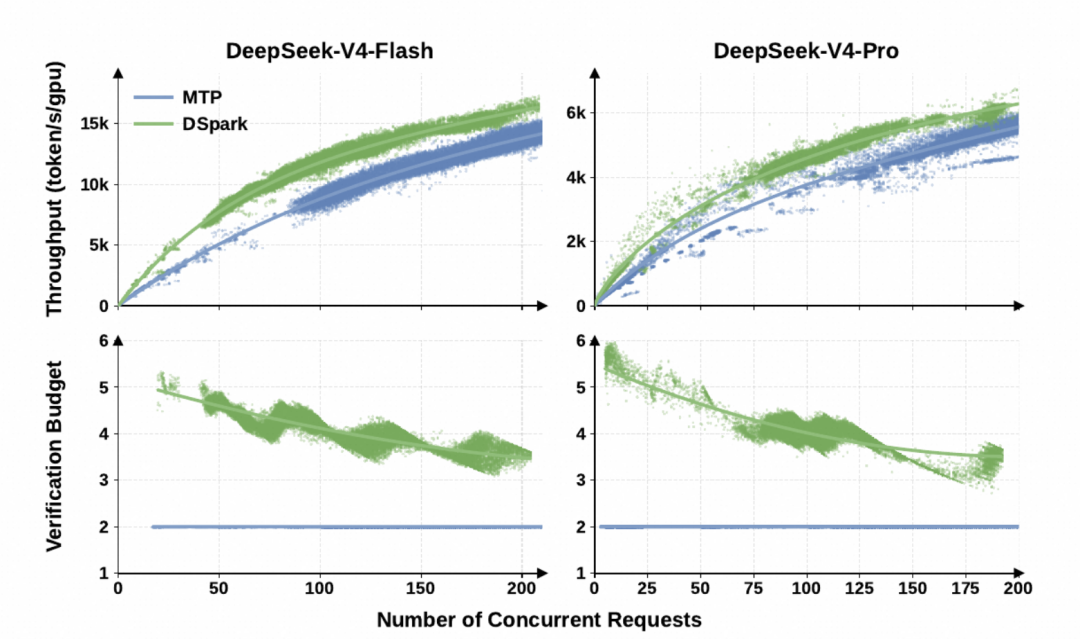
DeepSeek-V4 原本生产环境用的方案是 MTP-1,换成 DSpark 之后,同样的 GPU 资源能多服务 ~51%/52% 的用户,单个用户感受到的出字速度还快了 60-85% / 57-78%。
| 引擎 | SLA(TPS/user) | 同样 GPU 下总产出提升 | 单用户感受到的"出字速度"提升 |
| V4-Flash | 80字/秒 | +51% | 60–85% |
| V4-Pro | 35字/秒 | +52% | 57–78% |
技术创新
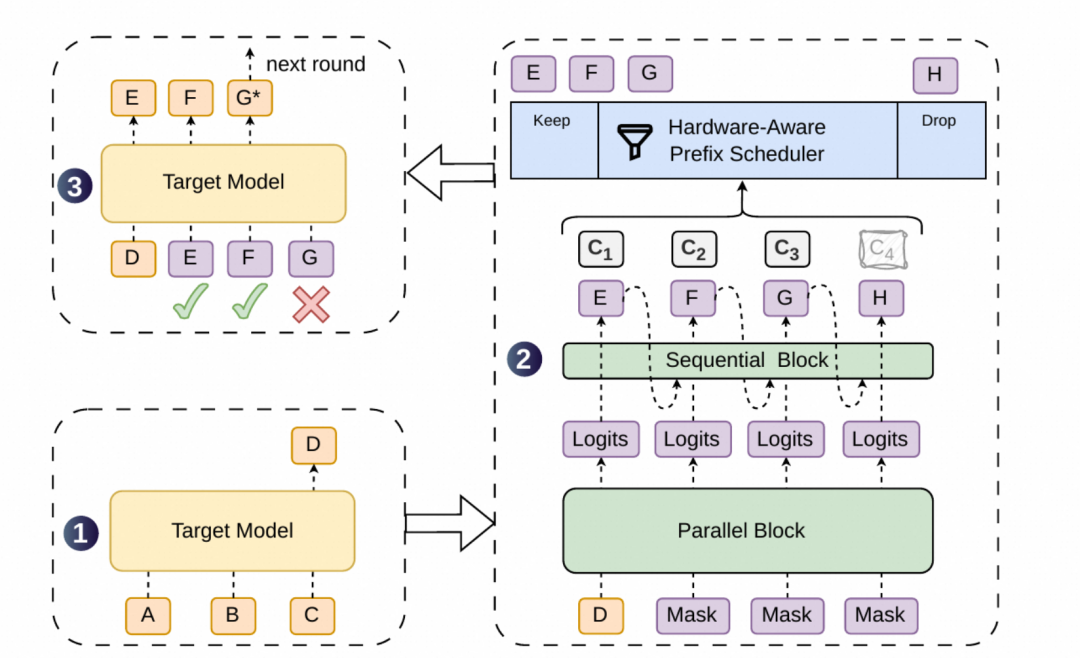
DSpark 真正新的地方就三件:草稿模型怎么又快又准、怎么知道每个 token 该不该提交、怎么让调度器根据 GPU 当前负载自动决定一次提交多少 token。如下图:左下 ❶ 主模型先给一个 anchor D,右侧 ❷ 草稿模型用 Parallel Block + Sequential Block 一次出 E/F/G/H 与各自的置信度 c₁–c₄,Hardware-Aware Prefix Scheduler 按置信度决定 keep E F G、drop H,左上 ❸ 主模型只验证保留下来的 E F G,被接受的 E F 进入下一轮、被拒的 G 重抽。
3.1 半自回归生成:并行 backbone + 轻量 sequential head
并行草稿(DFlash 这类)一次出整块 token、速度快,但每个位置独立预测,块尾部容易塌;自回归草稿(Eagle3 这类)保留 token 间依赖、但每多一个 token 草稿耗时就线性涨一次,只能用浅网络。DSpark 把草稿过程一拆为二——并行 backbone 一次出 γ 个 hidden state 与 base logits,sequential head 在 base logits 上叠一个前缀相关的转移偏置 让块内 token 互相打个招呼。head 默认用 Markov head:B 只依赖前一个 token、用低秩分解 ,开销几乎为零。整体上保留了并行的速度、补上了自回归的连贯性。
3.2 Confidence Head + STS 校准:让每个 token 自报"会不会被接受"
调度器需要知道"这第 k 个 token 大概率会被接受吗",所以 DSpark 为每个 draft 位置训练一个置信度分数 ,建模"前 k−1 个 token 都被接受的条件下、第 k 个也被接受的概率",监督信号取自草稿分布与主模型分布的 TV 距离。原始 会过度自信(论文 Alpaca 上 ECE 达 3%–8%,即自报 80% 把握实际只有 73% 命中),DSpark 引入 Sequential Temperature Scaling (STS) 逐位做 1D 校准,最终把 ECE 压到约 1%——这是后面调度器敢直接用置信度做排序的前提。
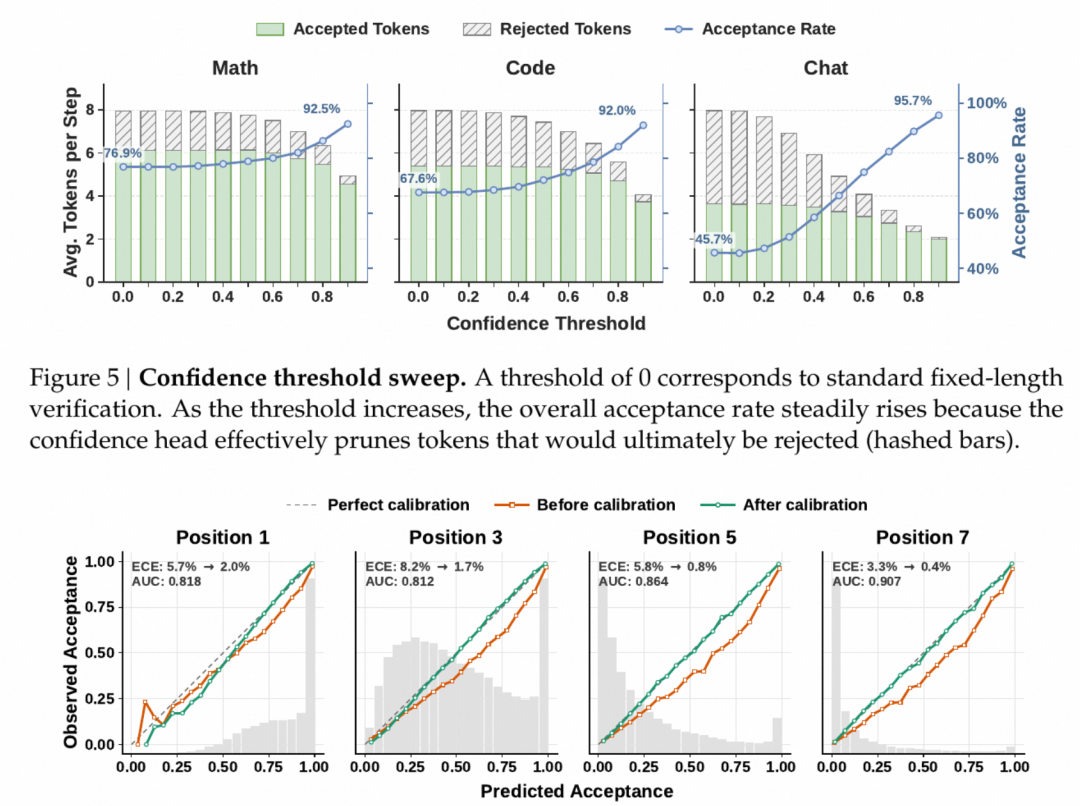
3.3 Hardware-Aware Prefix Scheduler:把置信度变成"该发多少 token"
有了每个 token 的可信置信度,调度器要回答的就是"这一轮所有用户加起来该发多少 token 给主模型验证"——多了浪费 GPU,少了速度跟不上。DSpark 把它建成全局吞吐 的最大化问题( 是预期接受 token 数,SPS 是一次性 profile 出的"batch size→每秒步数"曲线),按累积存活概率 降序贪心加入候选、 下降即早停。
其余工程实现——batch 内变长 verification 的 flatten + marker tensor kernel、训练用的 CE+TV+Conf 三项损失加位置权重、hidden state communication 与 anchor-bounded sequence packing 等系统优化——见论文正文。
如何使用
代码与环境安装
git clone https://github.com/deepseek-ai/DeepSpec.git
cd DeepSpec
python -m pip install -r requirements.txt
训练自己的 drafter:DeepSpec 仓库同时提供 Eagle3、DFlash、DSpark 三套实现。
bash scripts/train/train.sh离线评测:
仓库自带 Math (GSM8K/MATH500/AIME25)、Code (MBPP/HumanEval/LiveCodeBench)、Chat (MT-Bench/Alpaca/Arena-Hard) 三类评测集以及benchmark 脚本,可直接复现论文结果。
bash scripts/eval/eval.sh

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献1004条内容
已为社区贡献1004条内容

所有评论(0)