
North Mini Code开源:30B-A3B 编程 MoE,Cohere面向开发者的首个模型
引言
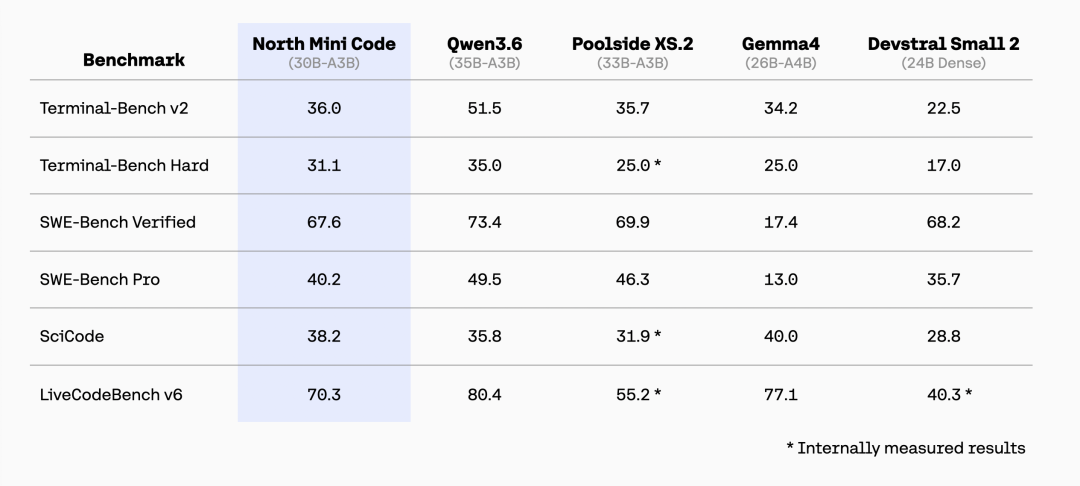
Cohere 开源了 North Mini Code,一个总参数 30B、激活参数仅 3B 的混合专家(MoE)编程模型,以 Apache 2.0 许可证发布。这是 Cohere 全新模型家族的首个模型,专为智能体软件工程(agentic coding)设计,覆盖复杂软件工程工作流、基于终端的智能体任务和高质量代码生成。研究团队采用多脚手架训练以保证模型跨智能体框架(harness)的稳健性,使其可作为 OpenCode 等代码智能体的可靠基础;BF16 与 FP8 量化权重均已放出。
开源地址:
- BF16: https://modelscope.cn/models/CohereLabs/North-Mini-Code-1.0
- FP8: https://modelscope.cn/models/CohereLabs/North-Mini-Code-1.0-fp8
技术架构
North Mini Code 是基于 Transformer 的仅解码器稀疏 MoE 模型。注意力层以 3:1 比例交替使用带 RoPE 的滑动窗口注意力和不带位置编码的全局注意力,前馈层为含 128 个专家、每 token 激活 8 个的 MoE 块,专家采用 SwiGLU 激活,路由器在 top-k 选择前对 logits 施加 sigmoid;稀疏层之前另设一个稠密层。
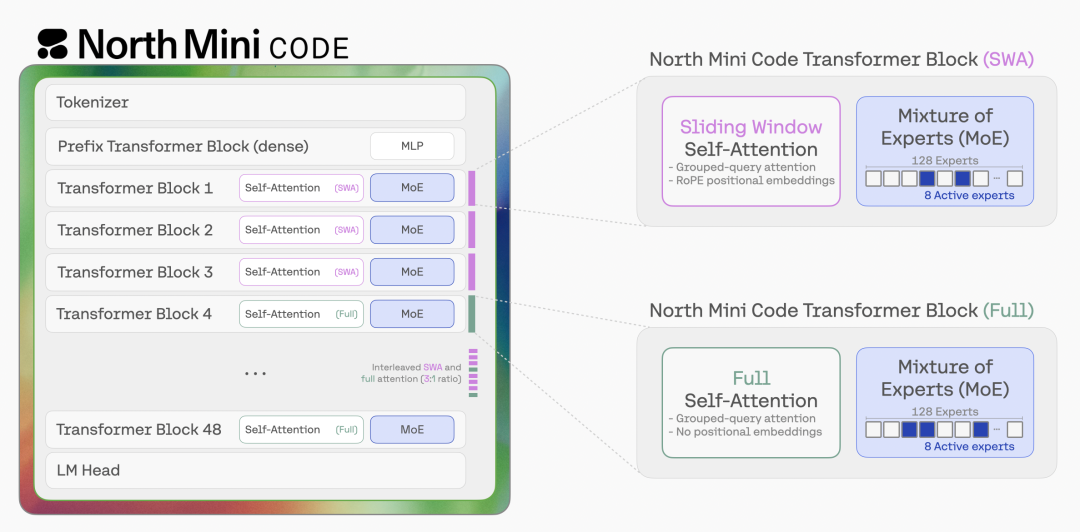
图: North Mini Code 是一个混合专家 Transformer 解码器,交替使用滑动窗口自注意力和全局自注意力。
面向编程卓越性的后训练
后训练分两阶段级联 SFT,再接基于可验证奖励的强化学习(RLVR),全程聚焦智能体编程。第一阶段在编程、推理、指令遵循等广泛领域训练,代码占可训练 token 的 70%(含 43% 智能体工具使用、27% 单轮竞赛或科学编程);第二阶段仅用 4.5B token 的智能体与推理数据,代码占比提升至 61%,且所有工具调用与补全均验证可执行、正确。两阶段上下文长度分别为 64K 和 128K,采用”从长到更长”的级联策略:先在较短数据上建立基线,再仅用高质量样本做长上下文训练——若直接混合长短数据,初期的 20B 非代码 token 会压过后期 1.5B 高质量代码 token,反而损害性能。数据来自容器化智能体编程环境,覆盖约 5000 个仓库的 7 万多个可验证任务,并与 SWE-Bench、SWE-Bench-Pro 的来源去重以防泄漏。SFT 仅作为 RLVR 的引导,经样本级过滤剔除无效工具调用、特殊 token 错误等异常后,最终 SFT 模型在 SWE-Bench Verified 上达到 80.2% pass@10,在 Terminal-Bench v2 上达到 55.1% pass@10。
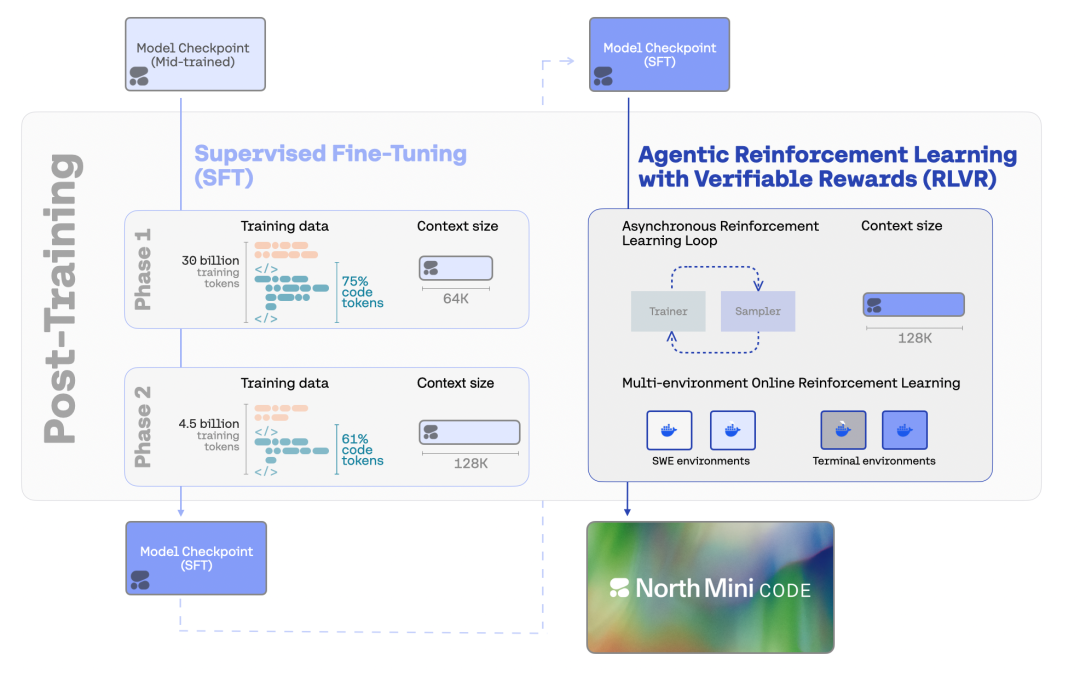
图: 后训练流程由两个阶段的监督微调(SFT)以及一个面向软件工程与终端任务、采用可验证奖励强化学习(RLVR)的阶段组成。
跨框架的稳健性
真实开发环境的智能体框架(harness)差异不止于提示,更在于工具使用模态:SWE-Agent 提供 bash、str_replace_editor、submit 等专用命令的丰富 CLI;mini-SWE-agent 仅有单一 bash 工具和原始 stdout;OpenCode 则用细粒度类型化工具并返回结构化 JSON。研究团队在第二阶段 SFT 中仅加入 6% 的基准框架数据(所选 SWE-Agent 占 50%),即在 OpenCode 评估上获得 10% 增益,同时不损害 SWE-Bench Verified 上 SWE-Agent 的表现;模型在 mini-SWE-Agent 上的 61.0% pass@1 几乎是跨框架迁移”免费”获得的,说明工具能力重叠的框架可正向迁移、技能互补而非冲突。针对 Terminal-Bench 采用的纯文本 Terminus 2 框架,仅加入不到 20% 的纯文本数据即可泛化,但需在各框架中引入足够变化(类似数据增强),迫使模型建立指令与行为的真实关联而非复述模板。
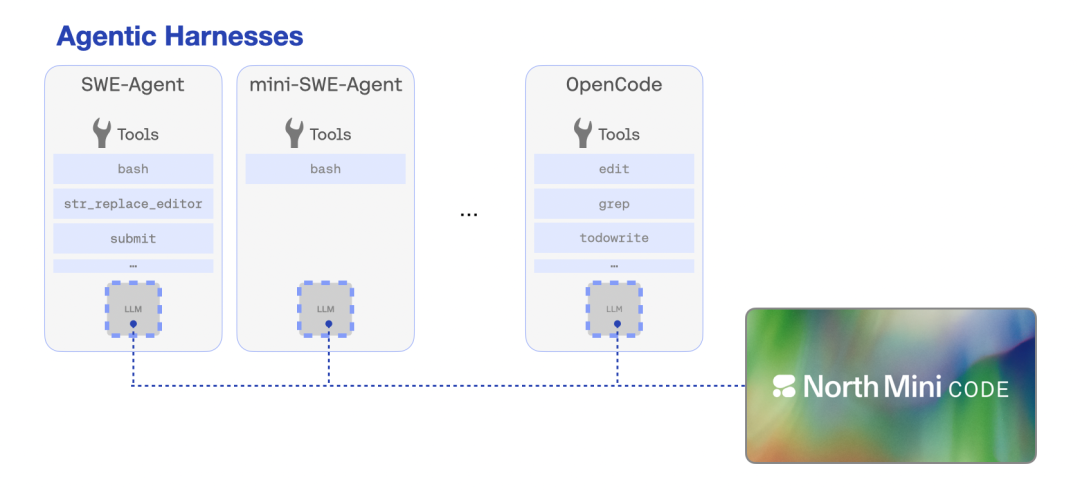
图: 后训练流程由两个阶段的监督微调(SFT)以及一个面向软件工程与终端任务、采用可验证奖励强化学习(RLVR)的阶段组成。
面向智能体编程的异步强化学习
编程智能体的 rollout 长且长度差异极大,最慢轨迹常是中位数的十倍。为避免同步训练空等长尾,研究团队将采样与学习解耦:训练器与持续产出 rollout 的 vLLM 边车并行,每 K=4 步同步一次权重,残余的轻微离策略在损失层面校正;并用窗口化 FIFO 队列在队首按完成顺序排空拖尾、其余保持输入顺序,在几乎不损失稳定性的前提下恢复吞吐。训练目标为 CISPO——带 token 级重要性采样校正的对数似然目标,重要性权重乘以对数似然而非概率比,并以更强正则化增强 RLOO,损失在 token 级聚合,使长轨迹的信用分配信号不被降权。整个 RL 为单次多环境在线训练,同时覆盖终端任务(ReAct + 基于 Harbor Tmux 的终端工具)与软件工程任务(SWE-agent 框架):每批 512 个 rollout、每 prompt 采样 8 个、共享 128K 上下文,按任务难度分配步数预算;环境提供预构建 Docker 镜像、自然语言指令和单元测试,采用二元奖励,无效工具调用记 0 分,使非法或格式错误的工具调用在最初几步内骤降。相比 SFT 初始模型,RLVR 使 Terminal-Bench v2 的 pass@1 提升 7.9%、SWE-Bench 提升 3.0%(均为绝对值),且联合训练优于分别训练、对分布外任务泛化更好,并产出更短的轨迹和更少的循环、失败调用。
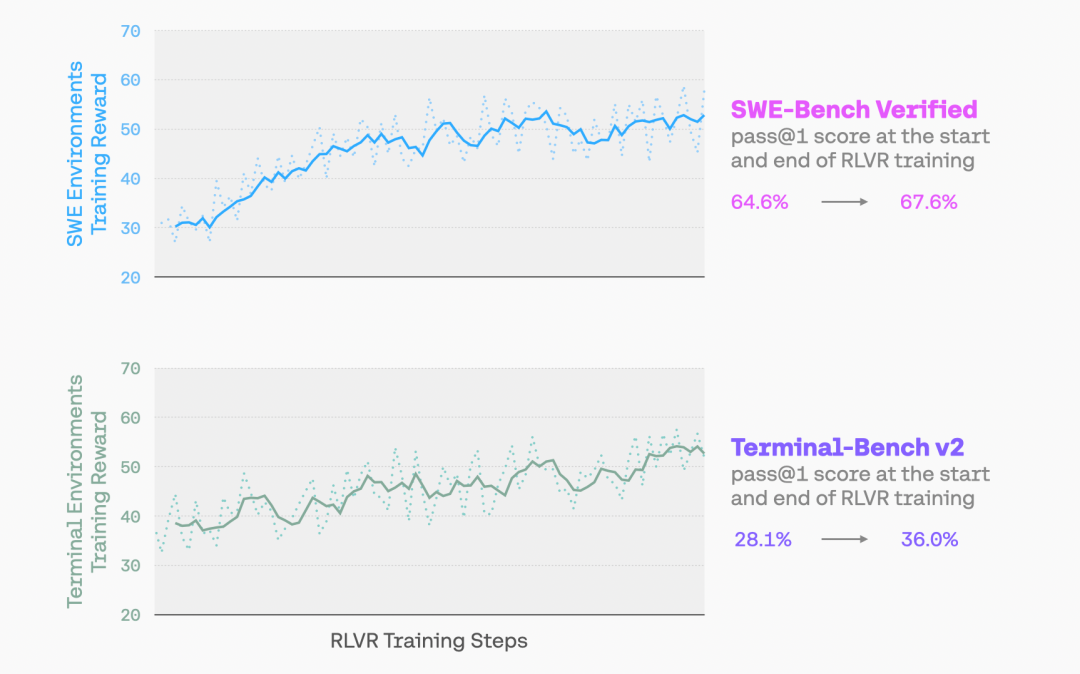
图: 多环境 RL 训练运行提升了模型在 SWE-Bench Verified 和 Terminal-Bench v2 等基准上的表现。左侧展示了 RLVR 训练过程中的学习曲线。
内部人工评估基准
作为对现有编程基准的补充,还开发了内部基准套件,用于在与人工标注者进行的成对评估中衡量模型在分布外问题上的表现。与其他基准设置一致,评估了通过 Harbor 集成在 OpenCode 中的各代模型。为理解模型表现,我们在四个不同的功能维度上进行基准测试:
- 代码解释(Code Explanation): 要求模型在 README 文件中或直接向用户解释给定代码仓库的特定技术方面。
- 代码编辑(Code Editing): 要求模型基于现有代码库实现某项功能。
- 数据可视化(Data Visualization): 给定数据样本,要求模型使用特定框架创建特定的可视化;不提供额外代码。
- 从零实现(Implementation from Scratch): 仅给定设计规范和需使用的软件包,要求模型从零创建一个项目,主要聚焦于前端设计。
评估者会获得基于评分标准(rubric)的打分问题,以帮助他们评估各项响应标准,并在给出两个模型轨迹之间的最终偏好评级之前,先对各次尝试单独评分。在 85 个样本上,RLVR 后的最终模型对仅 SFT 版本的总体胜率为 66.1%,其中代码编辑任务的提升最为明显。
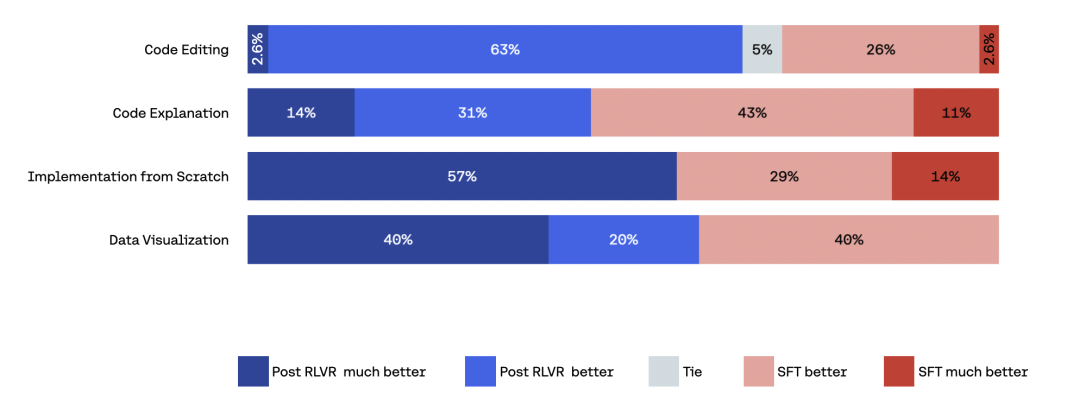
图: 在 85 个样本上,将 RLVR 后的最终 North Mini Code 检查点与仅经过 SFT 的检查点进行对比的成对偏好结果。
模型推理
使用transformers推理
环境安装
pip install transformers
模型下载
modelscope download --model CohereLabs/North-Mini-Code-1.0 --local_dir CohereLabs/North-Mini-Code-1.0
推理脚本:建议在生成时使用以下采样参数:temperature=1.0,top_p=0.95
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereLabs/North-Mini-Code-1.0"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
prompt = "Write a python program to check if a string is a palindrome or not."
# Format message with the North-Mini-Code-1.0 chat template
messages = [{"role": "user", "content": prompt}]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
)
gen_tokens = model.generate(
**input_ids,
max_new_tokens=1024,
do_sample=True,
temperature=1.0,
top_p=0.95
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
也可以通过transformers 的 pipeline 抽象接口使用该模型:
from modelscope import pipeline
import torch
model_id = "CohereLabs/North-Mini-Code-1.0"
prompt = """Given a list of unique words each of size k and an n sized word, w, where n is a multiple of k,
Write a program in python to determine the number of unique combinations of words in the list that can be concatenated to form an anagram of the word w.
"""
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": f"{prompt}"},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
outputs = pipe(
messages,
max_new_tokens=1024,
do_sample=True,
temperature=1.0,
top_p=0.95
)
print(outputs[0]["generated_text"][-1])
通过vllm使用
你也可以在 vLLM 中运行该模型。在新版本发布之前,请对 North Mini Code 使用 vLLM 的 main 分支,同时准确的响应解析还需要安装 Cohere 的 melody 库。
uv pip install "git+https://github.com/vllm-project/vllm.git"
uv pip install cohere_melody>=0.9.0
随后可以通过以下命令启动 vLLM 服务器:
VLLM_USE_MODELSCOPE=true vllm serve CohereLabs/North-Mini-Code-1.0 \
-tp 2 \
--max-model-len 320000 \
--tool-call-parser cohere_command4 \
--reasoning-parser cohere_command4 \
--enable-auto-tool-choice
在 OpenCode 中使用本地部署的 North Mini Code:
在新版本发布之前,请使用 OpenCode 的 main 分支。
# Example commands to install on linux
git clone https://github.com/anomalyco/opencode.gitcd opencode
# Install Bun
curl -fsSL https://bun.sh/install | bash
export BUN_INSTALL="$HOME/.bun"
export PATH="$BUN_INSTALL/bin:$PATH"
# node-gyp was needed by a dependency
bun add -g node-gyp
# Install dependencies
bun install
# Build CLI
bun run --cwd packages/opencode build/usr/bin/install -m 755 \
./opencode/packages/opencode/dist/opencode-linux-x64/bin/opencode \
/root/.local/bin/opencode

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献988条内容
已为社区贡献988条内容

所有评论(0)