
Macaron-V1-Preview开源:749B Mixture-of-LoRA 架构,四项 Agent 基准全部超越 GPT 5.4、Claude Opus 4.6
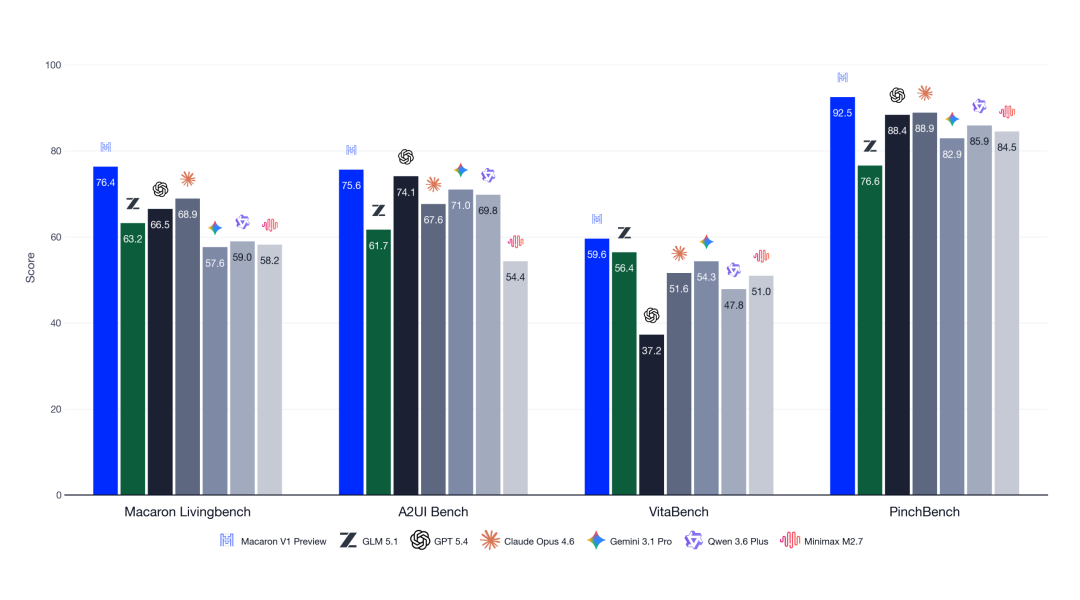
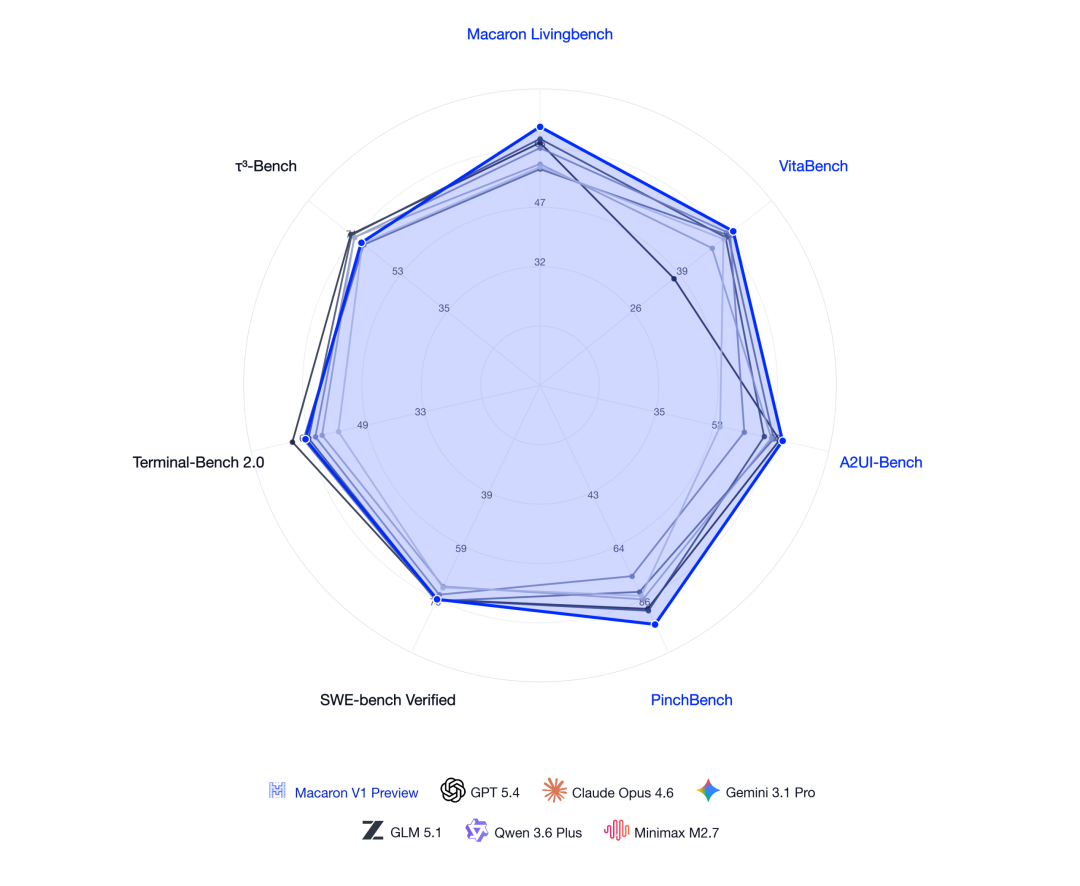
Mind Lab 正式发布 Macaron-V1-Preview ,一款基于 GLM5.1 后训练的 749B 智能体模型(744B 基座 + 5×1B LoRA),采用全新的 Mixture-of-LoRA(MoL)架构。MoL 将参数空间正交化,让每种智能体能力在各自独立的适配器空间中优化,在隔离冲突目标、避免多能力联合训练时常见优化干扰的同时,实现协同能力的共同提升。在四项智能体基准上,Macaron-V1-Preview 全部位列第一,领先 GPT 5.4、Claude Opus 4.6、Gemini 3.1 Pro 等主流模型。
Macaron-V1-Preview 提供两个版本,均基于 GLM5.1 进行后训练:
- Macaron-V1-Preview-749B:744B 基座 + 5 个 1B LoRA 专家适配器,完整 MoL 架构
- Macaron-V1-Preview-744B-Merged:744B 合并权重版本
开源地址:
- Macaron-V1-Preview-749B:https://modelscope.cn/models/mindlab-research/Macaron-V1-Preview-749B
- Macaron-V1-Preview-744B-Merged:https://modelscope.cn/models/mindlab-research/Macaron-V1-Preview-744B-Merged
- Technical blog:https://macaron.im/mindlab/research/macaron-v1-preview
个人智能体的三重核心特质
一个出色的个人智能体必须生活在用户所处的地方。日常生活充满了琐碎而关联的小决策:今晚吃什么、哪里有安静的位置、路况变化时如何改道、怎样在接送孩子的间隙安排牙医。这些事情单独看都不难,但它们的组合性、运动性,以及用户不断变化的意图和耐心,才构成真正的挑战。为了应对这种持续的、动态的摩擦,Mind Lab 认为一个好的个人智能体必须平衡三种核心特质:它必须是有能力的(Capable)——能够执行真实世界的任务和复杂推理;是连贯的(Coherent)——在长对话中维持记忆和上下文;是善于表达的(Expressive)——能通过最有效的界面即时传递信息,无论是一句简单的话、一张视觉卡片,还是一个交互式工具。
Mind Lab 选择了与这一愿景匹配的评测体系。Macaron LivingBench 是其旗舰基准,面向从 Macaron App 中蒸馏出的真实、动态的个人生活场景。
VitaBench 覆盖点餐和城市导航等具体日常生活场景。PinchBench 评估 OpenClaw 式的多步骤个人助手工作流。在编码方面,团队同时关注 SWE-Bench Verified 和 Terminal-Bench 2,在通用能力方面关注 τ³-bench。
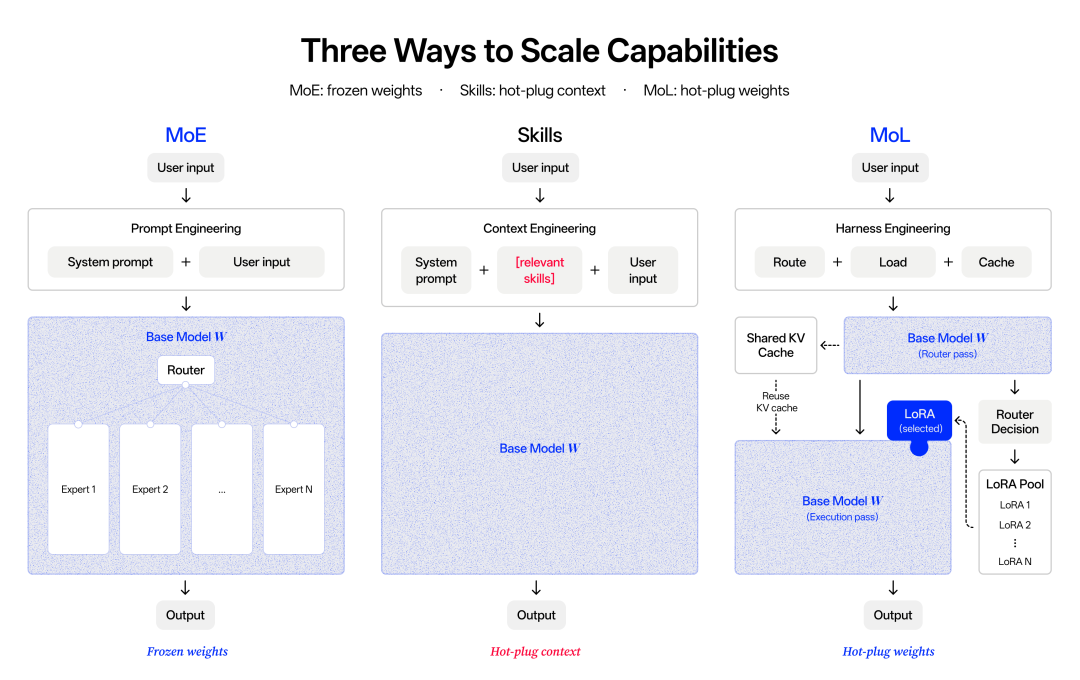
Mixture-of-LoRA:用架构解决能力冲突
现代后训练流水线将单一模型推过多种截然不同的任务,试图将所有能力融合到同一组权重中。Macaron 的训练过程越深入,团队就越清楚地发现,聊天、工具使用、推理和编码依赖不同的技能和截然不同的思维链模式。当这些技能共享同一参数空间时,它们会产生冲突:某个方向的提升会悄悄损害另一个方向的能力,合并后的模型在各专项前序模型擅长的领域反而表现更差。
Mixture-of-LoRA(MoL)从架构层面解决了这一冲突。其核心思想很简单:将共享技能和思维模式的任务聚类到同一个 LoRA 中,将技能差异大的任务放在独立的 LoRA 中,共享同一个冻结的基座模型。 相似任务共享一个 LoRA 以相互增强;技能差异大的任务各自拥有独立的 LoRA。新领域只需训练并注册一个新的 LoRA 即可接入,无需触碰基座或任何现有专家。代价是需要某种机制来决定每一轮使用哪个 LoRA,团队通过 Router Tool 解决。
Macaron-V1-Preview 配备了五个专家适配器:L0 用于默认聊天和通用对话,L1 用于个人生活任务,L2 用于编程任务,L3 用于 A2UI 生成式 UI,L4 用于 OpenClaw 式长程智能体任务(针对 OpenClaw Harness 进行了专项适配)。每个专家沿各自的轨迹独立发展,上线新能力变成了训练并注册一个新 LoRA 的过程。
这种整合同时重塑了模型的训练和服务方式。在上游,冻结 744B 基座将计算集中在 1B 适配器上,而 Rollout Routing Replay(R3)等流水线保持各适配器上 RL 的稳定性,实现有针对性的、低开销的适配器更新。在下游,这通过更低的认知负荷、更高的信息密度以及从对话到行动的无缝过渡来增强应用体验。
Router Tool:模型选择即工具调用
早期 MoE 风格的工作通常训练一个专用路由模型。Macaron 走了不同的路径——将模型选择暴露为 Harness 层面的工具调用(Tool Call),让标准基础设施处理其余部分。默认入口适配器为 L0,挂载一个 change_model 工具,通过标准 OpenAI 兼容的 Tool Call API 暴露。中央 LoRA 注册表 作为唯一事实来源,存储每个 LoRA 的 model_id、tier 和 routing_rule,注册新专家只是一次元数据变更。
智能体循环分为两个阶段:显式路由(Explicit Routing)——L0 发出 change_model 调用,切换到适合当前用户轮次的专家;隐式路由(Implicit Routing)——专家完成当前轮次后,脚手架自动返回 L0,下一条用户消息从默认入口重新开始。路由可调试(在 trace 中显示为工具调用)、可在标准基础设施上服务(vLLM 的 OpenAI 服务模式直接可用)、可回滚(新 L4 只需一次注册表更新)。
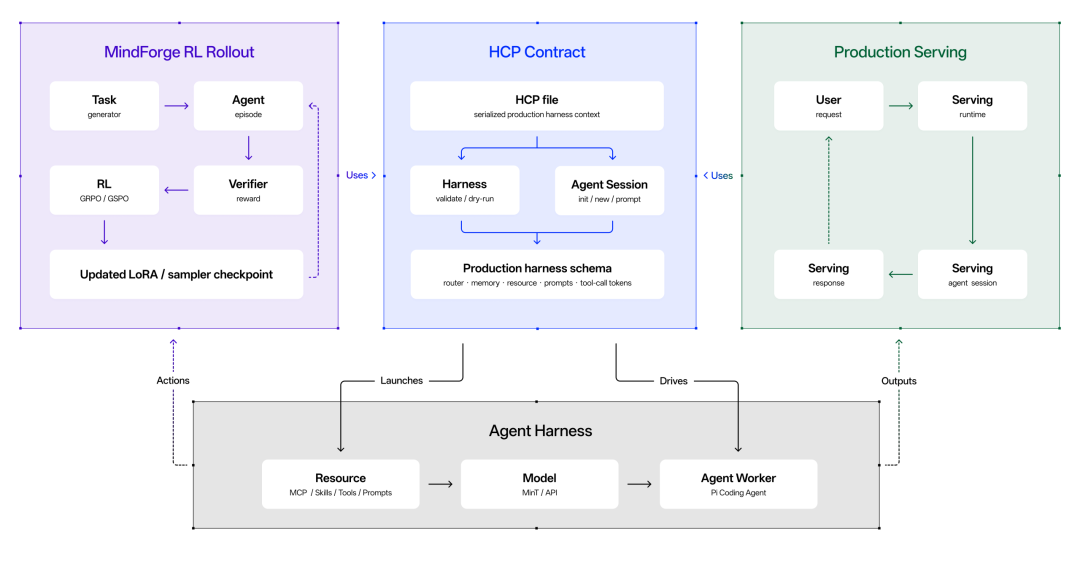
Router Tool 有一个实际代价:切换 LoRA 会使 KV 缓存失效,因为每个 LoRA 修改了注意力计算。原生方式下,每次 Router Tool 调用都意味着在新专家上进行完整的重新 prefill。为控制用户端延迟,团队进行了一系列跨 LoRA KV 缓存复用实验——在切换时保留现有 KV 缓存并接受由此引入的质量损失。复用缓存会带来一定的精度成本,但损失保持在智能体实际进行的切换类型的可接受范围内。团队将其视为 Macaron-V1-Preview 的一个可行折中方案,随着 MoL 服务的成熟还有进一步优化的空间。
模型部署指南
通过transformers推理
环境安装
pip install -U transformers accelerate peft safetensors
模型下载
modelscope download --model mindlab-research/Macaron-V1-Preview-749B --local_dir mindlab-research/Macaron-V1-Preview-749B
加载基础模型并挂载专家lora:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
repo_id = "mindlab-research/Macaron-V1-Preview-749B"
adapter = "l1"
tokenizer = AutoTokenizer.from_pretrained(
repo_id,
trust_remote_code=True,
)
base_model = AutoModelForCausalLM.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
model = PeftModel.from_pretrained(
base_model,
repo_id,
subfolder=adapter,
)
model.eval()

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献986条内容
已为社区贡献986条内容

所有评论(0)