
腾讯混元重建后首作 Hy3 preview 来了!开源!主打全面实用性,Agent能力大幅提升
4 月 23 日,腾讯混元 Hy3 preview 语言模型发布并开源。这是一个快慢思考融合的混合专家模型,总参数295B,激活参数 21B,最大支持 256K 上下文长度。这是混元重建后训练的第一个模型,也是混元迄今最智能的模型,在复杂推理、指令遵循、上下文学习、代码、智能体等能力及推理性能上实现了大幅的提升。
Github:
https://github.com/Tencent-Hunyuan/Hy3-preview
模型合集:
https://www.modelscope.cn/collections/Tencent-Hunyuan/Hy3-preview
2026年2月,腾讯混元对其预训练与强化学习基础设施进行了重构,并公布了模型研发的三项原则:
能力综合发展:不主张单一能力突出,认为即便是代码智能体这类应用,也需要推理、长文本、指令遵循、对话、代码、工具调用等多种能力的协同。
评测贴近实际:减少对公开榜单的依赖,转而通过自建题库、最新考试题、人工评测、产品众测等方式衡量模型的实际表现。
注重性价比:通过模型架构与推理框架的协同优化降低任务成本,以提升应用的商业可行性。
01模型表现
多个测评结果显示,Hy3 preview 模型能力全面提升。
1. 出色的上下文学习和指令遵循能力
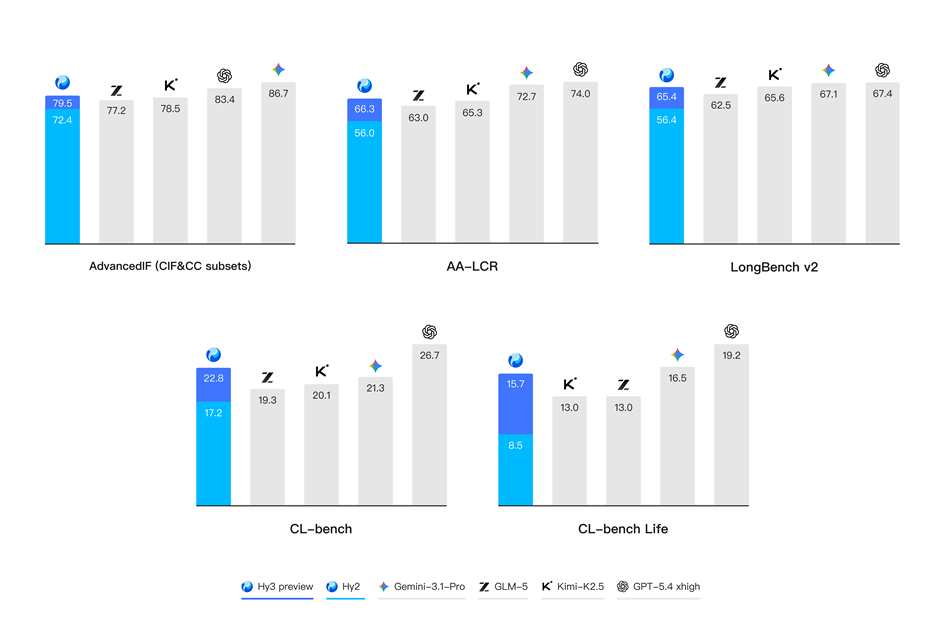
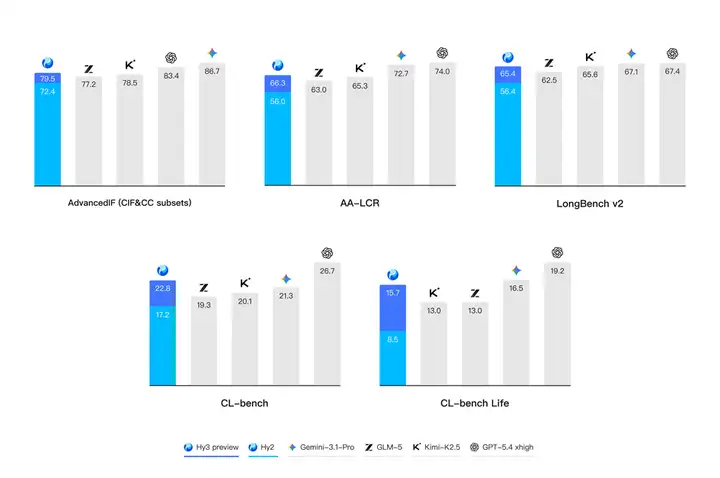
在各种真实的生产与生活场景,理解杂乱冗长的上下文并遵从复杂多变的规则是模型的首要挑战。基于腾讯业务场景的灵感,腾讯混元提出了 CL-bench和 CL-bench-Life 来创新性地评估模型的上下文学习能力,并在 Hy3 preview 显著地提升了模型上下文学习和指令遵循能力。
2. 复杂推理能力突出,清华数学博士资格考试国内分数最高
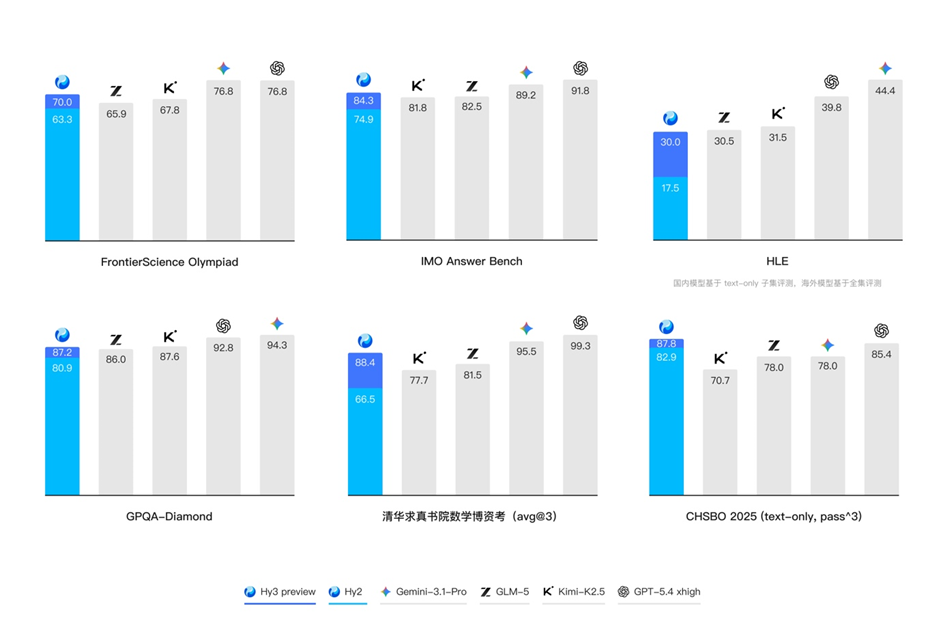
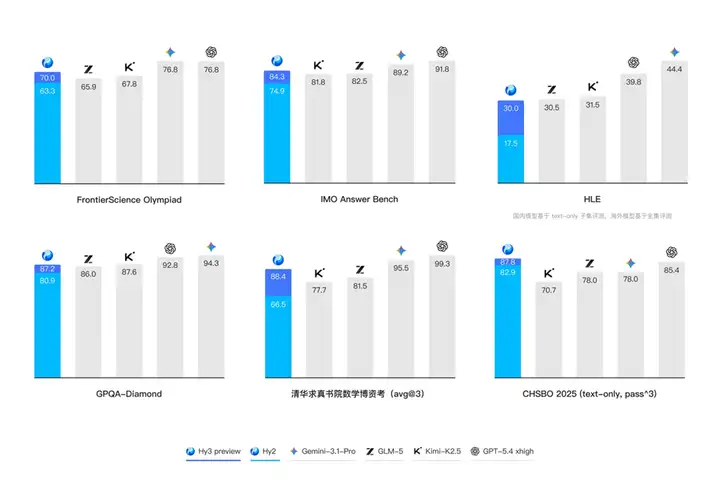
复杂推理能力是模型解决各种问题的基础。Hy3 preview 在 FrontierScience-Olympiad、IMOAnswerBench 等高难度理工科推理任务中表现突出,并在最新的清华大学求真书院数学博资考(26春)和 全国中学生生物学联赛(CHSBO 2025) 中取得优异成绩,展现了可泛化的强推理能力。
3. 代码与智能体提升最为显著,展现出高性价比
代码和智能体是 Hy3 preview 提升最为显著的方向。得益于预训练及强化学习框架的重建和强化学习任务规模的提升,腾讯混元以较快的速度在 SWE-Bench Verified、Terminal-Bench 2.0 等主流代码智能体基准以及 BrowseComp、WideSearch 等主流搜索智能体基准中取得了有竞争力的结果。
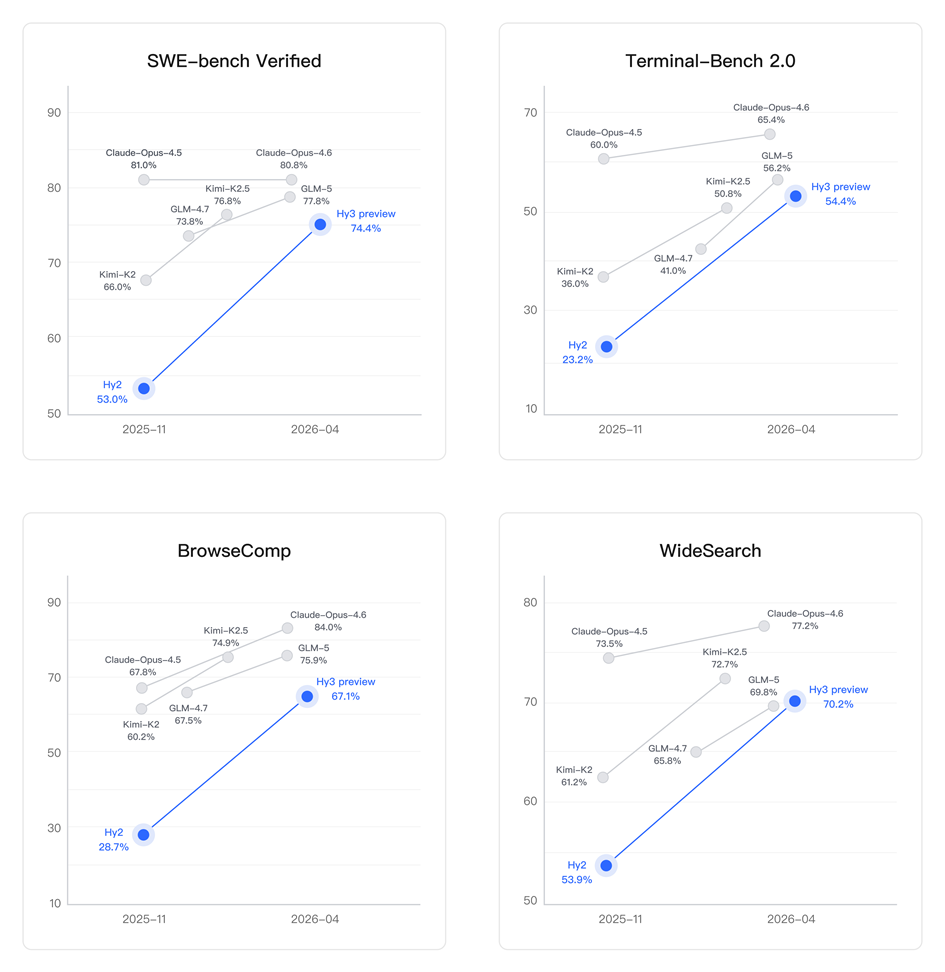
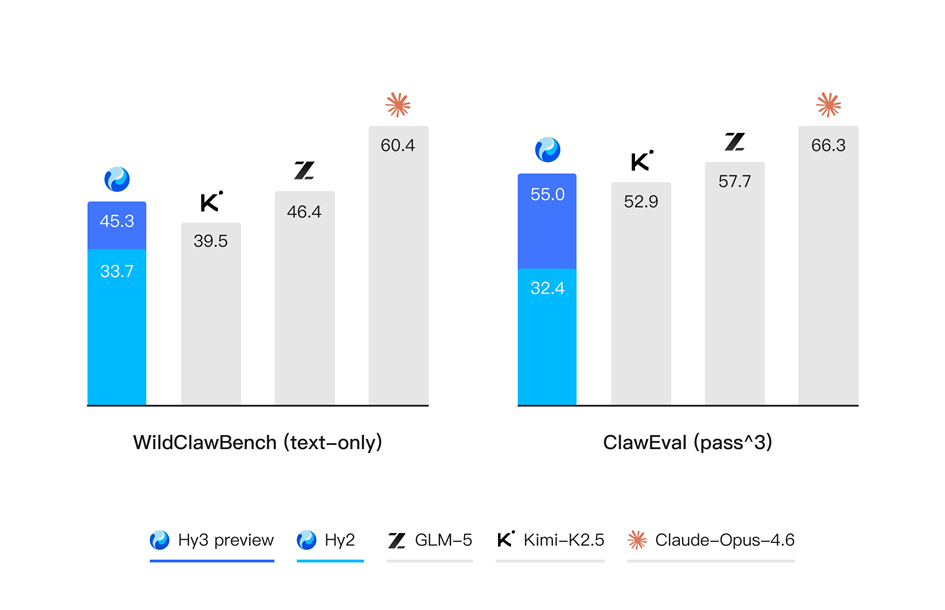
在数字世界中,代码关注的是模型在开发环境中的执行能力,搜索则聚焦于开放信息空间中的检索、筛选与整合能力,两者共同决定了模型在复杂智能体场景(例如OpenClaw)中是否真正具备可用性。Hy3 preview 在 ClawEval 和 WildClawBench 等评测中表现突出,表明我们的智能体能力正在稳步走向全面与实用。
除了公开榜单,腾讯混元还进一步构建了多个内部的评测集,对模型在真实开发场景中的表现进行评估。结果表明,无论是在后端工程任务集Hy-Backend,贴近真实用户开发交互的 Hy-Vibe Bench,还是高难度软件工程开发任务集 Hy-SWE Max 上,Hy3 preview 均体现出了强竞争力。
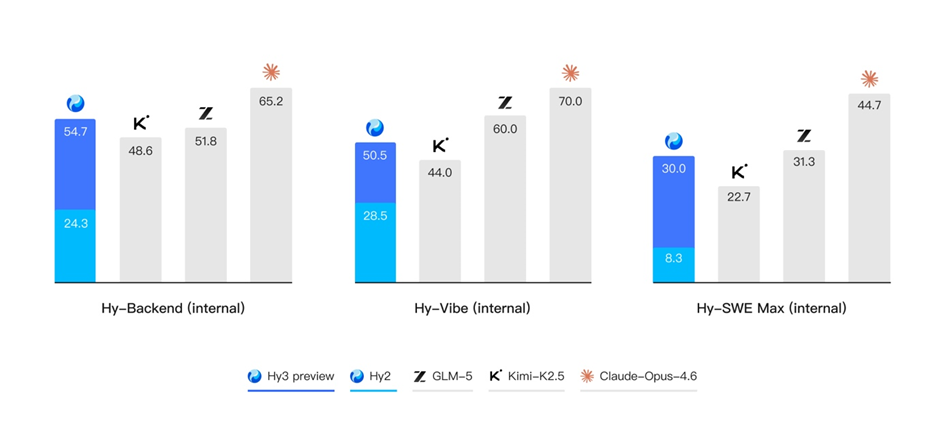
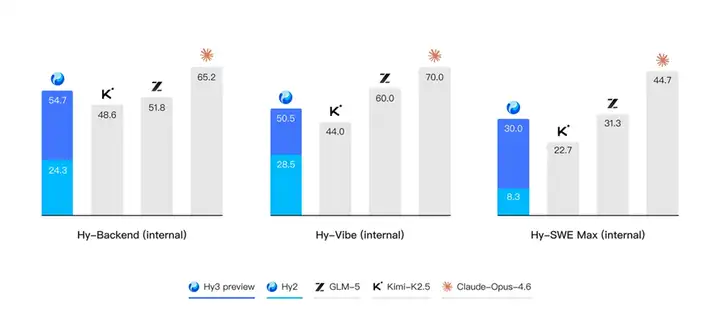
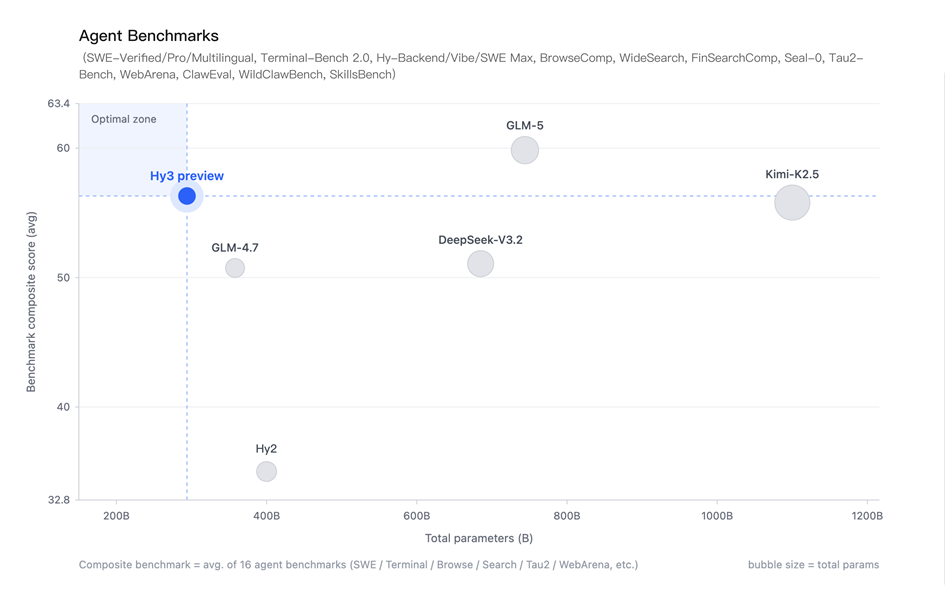
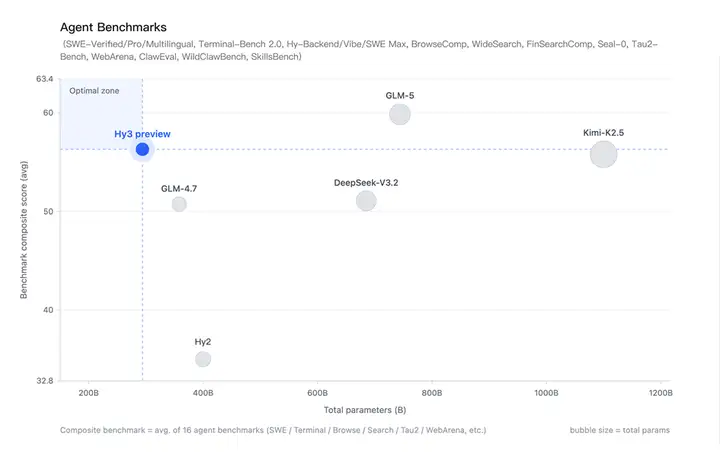
比较各个开源模型的大小与智能体综合表现,Hy3 preview 展现出高性价比。
02应用表现
在正式上线前,Hy3 Preview已在腾讯核心 AI 产品中完成多场景验证,并取得明确正收益。从开发者应用视角看,这一轮升级的关键不在单点能力,而在“模型 × 产品 × 场景”的整体协同效率。
在元宝、ima 等核心应用中,模型在意图理解、长文处理与检索任务上的准确性与覆盖度显著提升,同时通过文风与表达调优,交互更接近“活人感”。而在 CodeBuddy / WorkBuddy 等开发与办公场景中,性能指标直接转化为生产力:首 token 延迟降低 54%,端到端时长降低 47%,成功率达 99.99%+,并可稳定支撑最长 495 步的复杂 Agent 工作流,覆盖文档处理、数据分析到工具链编排。
进一步在 AI 分身、客服、AI NPC 及 AI PPT 等场景中,Hy3 Preview 展现出更成熟的上下文承接与角色一致性,显著减少幻觉与主观偏差,生成质量与稳定性同步提升。
整体来看,Hy3 Preview 的核心价值在于:不仅“更强”,更“可用”。对于开发者而言,这意味着更低延迟、更高成功率与更稳定的复杂任务执行能力,真正把模型能力转化为可落地的应用生产力。同时,得益于模型与推理框架的深度协同,以及算子性能与量化算法等系统级优化,整体推理效率进一步提升 40%,在同等成本下实现更高的智能密度,模型使用成本也较上一代显著下降。
03模型实战
模型部署&推理
Hy3-preview总参数量295B,推荐使用8张H20-3e或更大显存GPU部署。
vLLM部署
从源码构建vLLM:
uv venv --python 3.12 --seed --managed-python
source .venv/bin/activate
git clone https://github.com/vllm-project/vllm.git
cd vllm
uv pip install --editable . --torch-backend=auto
启动启用 MTP 的 vLLM 服务器:
VLLM_USE_MODELSCOPE=true vllm serve tencent/Hy3-preview \
--tensor-parallel-size 8 \
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 1 \
--tool-call-parser hy_v3 \
--reasoning-parser hy_v3 \
--enable-auto-tool-choice \
--served-model-name hy3-preview
SGLang部署
从源码构建SGLang:
git clone https://github.com/sgl-project/sglang
cd sglang
pip3 install pip --upgrade
pip3 install "transformers>=5.6.0"
pip3 install -e "python"
启动启用 MTP 的 SGLang 服务器:
SGLANG_USE_MODELSCOPE=true python3 -m sglang.launch_server \
--model tencent/Hy3-preview \
--tp 8 \
--tool-call-parser hunyuan \
--reasoning-parser hunyuan \
--speculative-num-steps 1 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 2 \
--speculative-algorithm EAGLE \
--served-model-name hy3-preview
部署完成后,通过兼容OpenAI的API调用:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="Tencent-Hunyuan/Hy3-preview",
messages=[
{"role": "user", "content": "Hello! Can you briefly introduce yourself?"},
],
temperature=0.9,
top_p=1.0,
extra_body={"chat_template_kwargs": {"reasoning_effort": "no_think"}},
)
print(response.choices[0].message.content)
推荐参数:temperature=0.9,top_p=1.0。推理模式通过reasoning_effort控制:复杂任务(数学、编程、推理)设为"high",直接响应设为"no_think"(默认)。
模型训练微调
Hy3-preview支持全量微调和LoRA微调,集成DeepSpeed ZeRO和LLaMA-Factory。
硬件要求
- LoRA微调:最少单机8卡(每卡80GB显存以上)
- 全量微调:最少4机32卡(每卡80GB显存以上)
训练数据格式
支持慢思考(reasoning_effort: "high")和快思考(reasoning_effort: "no_think")两种模式,训练数据为标准messages格式的jsonl文件。慢思考模式需在assistant消息中额外提供reasoning_content字段。
快速启动
训练前需先将原始检查点转换为HuggingFace兼容格式(专家权重融合为3D张量):
python convert_ckpt_to_outer.py --input_dir <原始检查点目录> --output_dir <输出目录> --workers 8
python check_converted.py <转换后目录> --spot-check 3 # 验证转换结果
单机训练:
cd train
pip install -r requirements.txt
bash train.sh
多机训练需配置免密SSH登录,在
train.sh
开头设置
HOST_GPU_NUM
和
IP_LIST
后在主节点执行即可。
关键参数
--deepspeed:提供zero2/zero3/zero3+offload三档配置,显存需求依次递减--use_lora:启用LoRA训练,配合--lora_rank、--lora_alpha等参数--make_moe_param_leaf_module:MoE模块不被zero3拆分,显存占用会显著增加--gradient_checkpointing:启用梯度检查点节省显存
也可使用LLaMA-Factory进行微调,提供了LoRA和全量微调的配置文件模板,详见train/llama_factory_support目录。
模型合集
https://www.modelscope.cn/collections/Tencent-Hunyuan/Hy3-preview

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献986条内容
已为社区贡献986条内容

所有评论(0)