
Gemma 4 开源发布: Google 迄今最强开放模型,主打推理与 Agent 能力
近日,Google 正式开源 Gemma 4 系列,基于与 Gemini 3 相同的技术底座构建,采用 Apache 2.0 许可。本次发布包含四个规格:E2B、E4B、26B MoE 和 31B Dense,覆盖从端侧到服务器的多种部署场景。核心亮点在于参数效率极高——31B 模型在 Arena AI 文本排行榜位列开放模型第 3,26B 位列第 6,性能超越多个 20 倍参数量级的模型。在边缘侧,E2B 和 E4B 模型重新定义了设备端的实用性,它们优先考虑多模态能力、低延迟处理以及无缝的生态集成,而非单纯追求参数规模。
Gemma 4 全系列针对复杂推理和 Agentic 工作流做了重点优化,不再局限于简单对话场景。对开发者而言,这意味着可以用较低的硬件成本,在自有基础设施上运行接近前沿闭源模型水平的能力。
自初代发布以来,Gemma 生态已积累超 4 亿次下载和 10 万+ 衍生模型,社区基础成熟。
- Model:https://www.modelscope.cn/collections/google/Gemma-4
- Gemmaverse:https://deepmind.google/models/gemma/gemmaverse
以下视频来自谷歌开发者
📎0bc3b4a7maab3malyo6o5ruvcd6d6yhqd5qa.f10002.mp4
模型特性
Gemma 4 之所以能成为Google迄今最强大的开放模型系列,归功于以下核心特质:
- 高级推理: 能够进行多步规划和深度逻辑推理,Gemma 4 在需要此类能力的数学和指令遵循基准测试中表现出显著的提升。
- 智能体工作流: 原生支持函数调用 (Function-calling)、结构化 JSON 输出和原生系统指令,构建能够与不同工具和 API 交互并稳定执行工作流的自主智能体。
- 代码生成: Gemma 4 支持生成高质量的离线代码,能够将您的工作站转变为本地优先的 AI 代码助手。
- 视觉与音频: 所有模型均原生支持视频与图像处理,支持可变分辨率,并在 OCR (光学字符识别) 和图表理解等视觉任务中表现出色。此外,E2B 和 E4B 模型还具备原生音频输入功能,可用于语音识别和理解。
- 更长的上下文: 可无缝处理长文本内容。边缘模型支持 128K 上下文窗口,更大参数的模型则提供高达 256K 的支持,可以在单次提示中处理整个代码库或长篇文档。
- 支持 140 多种语言: Gemma 4 经过 140 多种语言的原生训练,帮助开发者为全球用户构建包容、高性能的应用。
适配各类硬件灵活推理
Gemma 4 模型权重针对特定硬件和使用场景进行了量身定制,确保您随时随地都能获得顶尖的推理能力:
26B 和 31B 模型: 单卡可跑的前沿级推理模型
未经量化的 bfloat16 权重可以高效适配单个 80GB NVIDIA H100 GPU,为研究人员和开发者在常用硬件上提供顶尖的推理能力。对于本地配置,量化版本可在消费级 GPU 上原生运行,为 IDE、编程助手和智能体工作流提供动力。 26B 混合专家模型 (MoE) 专注于低延迟,推理时仅激活 38 亿参数,提供极快的每秒 Token 生成数;而 31B Dense 则追求极致的原始质量,为微调提供了强大的基础。
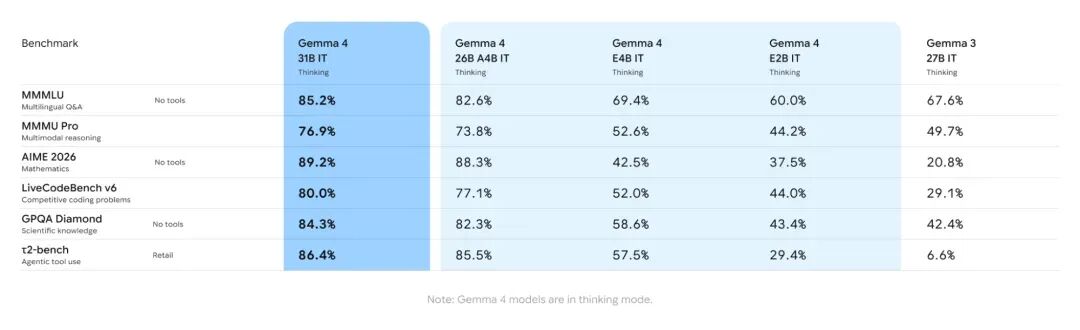
以上模型通过大量不同的数据集和指标进行了评估,以涵盖文本生成的各个方面。其他基准测试可前往请前往官方 Model Card 中查看
Model Card :
https://ai.google.dev/gemma/docs/core/model_card_4?hl=zh-cn
模型推理最佳实践可见模型详情:
- gemma-4-31B:
https://www.modelscope.cn/models/google/gemma-4-31B
- gemma-4-26B-A4B:
https://www.modelscope.cn/models/google/gemma-4-26B-A4B
E2B 和 E4B 模型: 面向端侧和 IoT 的轻量多模态模型
这些模型从底层开始构建,旨在实现计算和内存效率的最大化,在推理时分别激活 20 亿和 40 亿的有效参数,以节省内存和延长电池寿命。通过与 Google Pixel 团队以及高通、联发科等移动硬件领军企业的紧密合作,这些多模态模型可以在手机、树莓派、NVIDIA Jetson Orin Nano 等边缘设备上实现近乎零延迟的完全离线运行。Android 开发者现在即可在 AICore 开发者预览版中原型化智能体流程,实现与 Gemini Nano 4 的前向兼容。
模型推理最佳实践可见模型详情:
- gemma-4-E2B:https://www.modelscope.cn/models/google/gemma-4-E2B
- gemma-4-E4B:https://www.modelscope.cn/models/google/gemma-4-E4B
模型微调
ms-swift 第一时间支持了 Gemma4 系列模型的微调,包括文本、图像、语音和视频模态。ms-swift是魔搭社区官方提供的大模型训练框架,ms-swift开源地址:https://github.com/modelscope/ms-swift
环境准备:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
pip install transformers -U
可直接运行训练脚本如下:
# 2 * 20GiB
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 \
swift sft \
--model google/gemma-4-E2B-it \
--dataset 'AI-ModelScope/LaTeX_OCR:human_handwrite
#2000
' \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--tuner_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--freeze_aligner true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 4096 \
--output_dir output \
--warmup_ratio 0.05 \
--deepspeed zero2 \
--dataset_num_proc 4 \
--dataloader_num_workers 4
对验证集进行推理:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--load_data_args true
如果您需要自定义数据集微调模型,你可以将数据准备成以下格式:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg"]}
{"messages": [{"role": "user", "content": "<audio>语音说了什么"}, {"role": "assistant", "content": "今天天气真好呀"}], "audios": ["/xxx/x.mp3"]}推送微调后的模型到ModelScope:
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'点击直达模型合集

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献970条内容
已为社区贡献970条内容

所有评论(0)