
众智 FlagOS Skills:让 AI Agent 一句话搞定国产芯片开发
FlagOS Skills 正式上线魔搭 Skills中
FlagOS Skills 1.0——首个面向异构 AI 芯片的 AI Agent 专业技能库——已发布到魔搭社区 Skills 中心,并在魔搭首页作为合集置顶首推,并同步上线众智FlagOS社区平台。FlagOS Skills覆盖模型迁移、算子开发、性能调优等场景,让 Claude Code、Cursor、Codex 等 AI 编程工具直接具备面向各种AI芯片的开发能力。
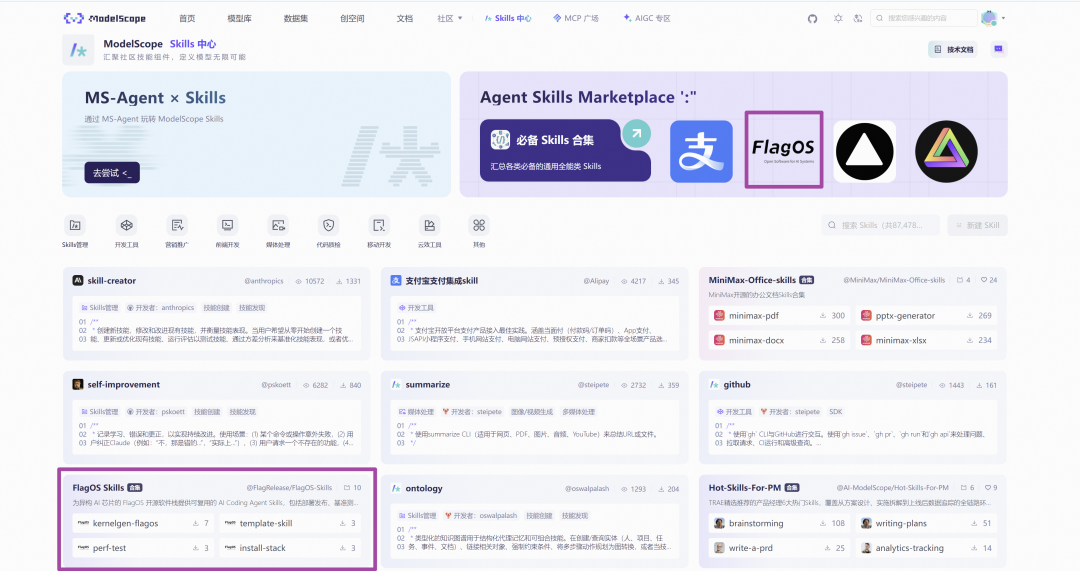
图一 魔搭 Skills 中心首页 FlagOS Skills 合集展示
魔搭Skills中心:https://www.modelscope.cn/collections/FlagRelease/FlagOS-Skills
FlagOS skills:https://github.com/flagos-ai/skills
为什么需要 FlagOS Skills?
让 AI 模型跑在国产芯片上,开发者要处理的问题很多:上游框架版本差异、芯片算子覆盖度、编译后端适配、推理服务配置、性能调优……相关知识散落在 GitHub Issue、芯片厂商文档和工程师的经验里。
FlagOS Skills 把这些知识整理成 AI 智能体可以直接执行的标准化流程。每个 Skill 是一个文件夹,包含 SKILL.md 指令文件、参考文档、脚本和资源,遵循 Agent Skills 开放标准。区别于简单的 prompt 模板不同,每个 Skill 封装的是完整的领域工作流。
以 model-migrate-flagos 为例,它的文件夹结构如下:
skills/model-migrate-flagos/
├── SKILL.md # 入口:YAML frontmatter(名称+描述)+ 详细执行指令
├── references/
│ ├── procedure.md # 逐步迁移流程
│ ├── compatibility-patches.md # 0.13.0 兼容性补丁目录
│ └── operational-rules.md # 操作规范(通信、调试、容错)
└── scripts/
├── validate_migration.py # 自动化代码审查
├── benchmark.sh # 性能基准测试
├── serve.sh / request.sh # 本地服务 + 测试请求
├── e2e_eval.py # 端到端精度对比
└── e2e_test_prompts.json # 测试用例(5 文本 + 5 多模态)智能体启动时先读 SKILL.md,再按需加载 references 和 scripts——既有判断依据,又有可执行的工具。下面我们就根据两个典型的案例去讲解下FlagOS Skills是如何工作的。
实战一:把新模型迁移到 FlagOS 多芯片平台
它解决什么问题
上游 vLLM 发布了对新模型(如 Qwen3.5、DeepSeek-V3 等)的支持。如果希望这些模型在 FlagOS 上运行,需要将上游最新 vLLM 的模型代码 backport 到 vllm-plugin-FL 插件中(当前版本为 vLLM v0.13.0)。在此过程中,还需要处理 API 差异、import 路径变更以及配置注册等问题,并最终完成端到端的精度验证,整体流程较为复杂且耗时较长。
现在,在 Claude Code 里输入一句话就能启动整个流程:
/model-migrate-flagos kimi_k25
📎0bc3xecekaaeluaicp6ikjuvjoodiw4qiria.f10002.mp4
视频1、model-migrate-flagos 模型迁移Demo
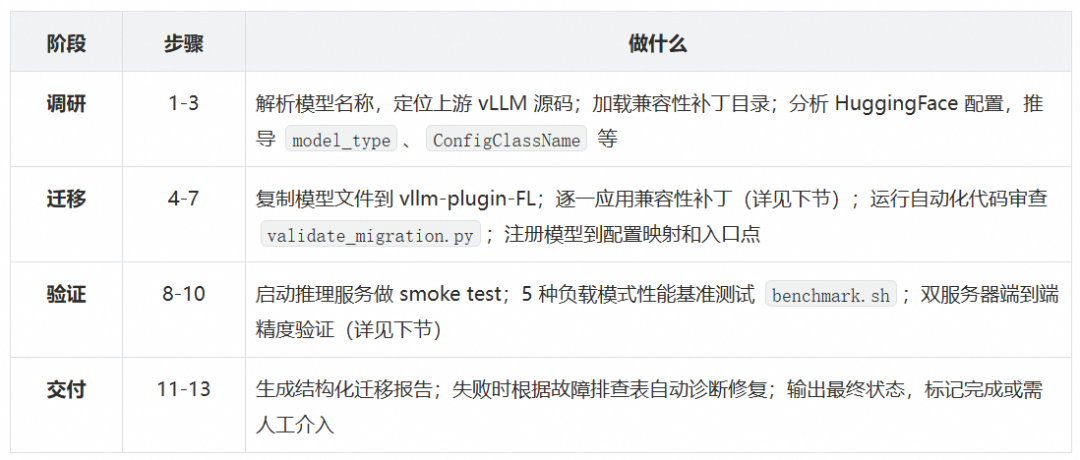
13 步标准流程
智能体按照 SKILL.md 中的标准流程,分四个阶段执行:
兼容性补丁匹配
模型迁移的难点不在执行步骤,而在过程中的判断。compatibility-patches.md 记录了 vLLM 0.13.0 与上游之间的所有已知差异,智能体在第 5 步根据实际遇到的错误按需匹配:

这些都是实际迁移中反复踩过的坑,每个模型的代码结构不同,需要的补丁组合也不同,智能体要根据上下文判断该用哪些,不管是脚本和prompt都无法实现。
端到端精度验证
第 10 步的 E2E 验证是整个流程中最关键的质量关卡,采用双服务器 token 级对比:
- 本地服务:
serve.sh启动 plugin 版本的 vLLM(端口 8122,VLLM_FL_PREFER_ENABLED=false) - 远程参考服务:
e2e_remote_serve.sh通过 SSH 在另一台机器上启动上游原版 vLLM - 对比:
e2e_eval.py向两个服务发送相同的测试 prompt(5 条文本 + 5 条多模态),逐 token 比较输出
如果精度有偏差,能直接定位迁移引入的问题(如:plugin 版本输出不同)。
真实示例
Example 1: 用户输入 /model-migrate-flagos kimi_k25智能体发现 kimi_k25 是 DeepseekV2 的 wrapper,按 wrapper 模式处理——复制文件、应用 P1+P2 补丁、创建 config bridge、注册、验证、测试、benchmark、E2E 验证,全部通过。
Example 2: 用户输入 "migrate qwen3_5 again, upstream updated"幂等重跑——覆盖已有文件、重新应用补丁、重新验证、重跑 E2E 确认无回归。
实战二:用 AI 生成和优化 GPU 算子
kernelgen-flagos 是 KernelGen 2.0 的智能体技能入口,通过 MCP 协议连接 KernelGen Operator Development MCP Toolkit,支持算子生成、优化和跨平台特化。
📎0bc3pibqyaadp4amixgpz5uvg6wdbr5agdaa.f10002.mp4
视频2、 kernelgen-flagos 算子生成 Demo
KernelGen 的生成流程
KernelGen 不是纯靠 LLM 从零生成代码,而是一套结构化的四步流程:
- 收集 Kernel 信息:从用户的自然语言描述中提取算子参数(输入/输出类型、形状、计算逻辑)
- 搜索相似代码片段:在已有代码库中检索相似实现作为参考(用户可选择是否采用)
- 生成 Kernel 代码 + CUDA 实现:同时生成 Triton Kernel 和对应的 CUDA 实现,后者作为 PyTorch benchmark 基准
- 测试:用 CUDA 实现作为 ground truth 测试 Kernel,输出 Correctness(正确性)和 Speedup Ratio(加速比)
第 2 步的代码检索说明 KernelGen 内置了 RAG 机制——先找到相关的已有实现作为参考,再在此基础上生成。这是它在正确性上显著超过纯 LLM 方案(99% vs 90%)的关键原因之一。
生成完成后,从生成到贡献的路径已完全自动化:如果在 FlagGems 仓库下开发,专门适配的子技能会自动完成格式转换与目录对齐,将 4 个核心产物(kernel、baseline、accuracy test、speedup test)直接注入 src/flag_gems/experimental_ops/ 目录,开发者无需手动调用转换脚本,即可一键生成合规的 PR。
三种使用场景
场景一:为 FlagGems 或 vLLM 生成算子
智能体自动检测当前仓库类型(FlagGems / vLLM / 通用 Triton),分发到对应的子技能。
/kernelgen-flagos Generate a ReLU operator, classification is pointwise.
Input: torch.Tensor (any shape, floating-point). Output: torch.Tensor,
logic is max(0, input). Integrate into FlagGems. Use MetaX.生成的文件自动提交到 FlagGems 项目,包含 @pointwise_dynamic 封装、_FULL_CONFIG 注册和算子签名对齐。支持 6 种测试设备:NVIDIA、华为昇腾、海光、天数智芯、摩尔线程、沐曦 (默认是NVIDIA)。
场景二:优化已有算子(当前仅支持 NVIDIA)
通过 MCP 迭代循环——分析瓶颈、应用优化策略、运行 benchmark、根据结果调整——直到达到目标加速比。
Optimize the index_put operator. Optimize 5 iterations.
场景三:跨平台特化(当前支持 NVIDIA → 华为昇腾)
将 CUDA 实现的算子迁移到华为昇腾,自动处理架构差异、Grid 配置和内存对齐。
Migrate the CUDA-implemented operator fused/silu_and_mul.py to the
Ascend chip, stored in FlagGems _ascend/fused/silu_and_mul.py,
ensuring accuracy verification passes.接入方式
使用 kernelgen-flagos 需要先连接 KernelGen MCP Toolkit(详细文档):
- 访问 https://kernelgen.flagos.io/login 获取 Bearer Token
- 连接 MCP:
# Claude Code
claude mcp add --transport sse --scope user \
-H "Authorization: Bearer <your Token>" \
kernelgen-mcp http://kernelgen.flagos.io/sse
# VS Code + Copilot:提示安装 skill 后自动配置 mcp.json
# OpenClaw:提示连接 MCP 后重启- 安装 Skill:
npx skills add flagos-ai/skills --skill kernelgen-flagos
子技能一览
kernelgen-flagos 是一个统一入口,包含 9 个子技能:
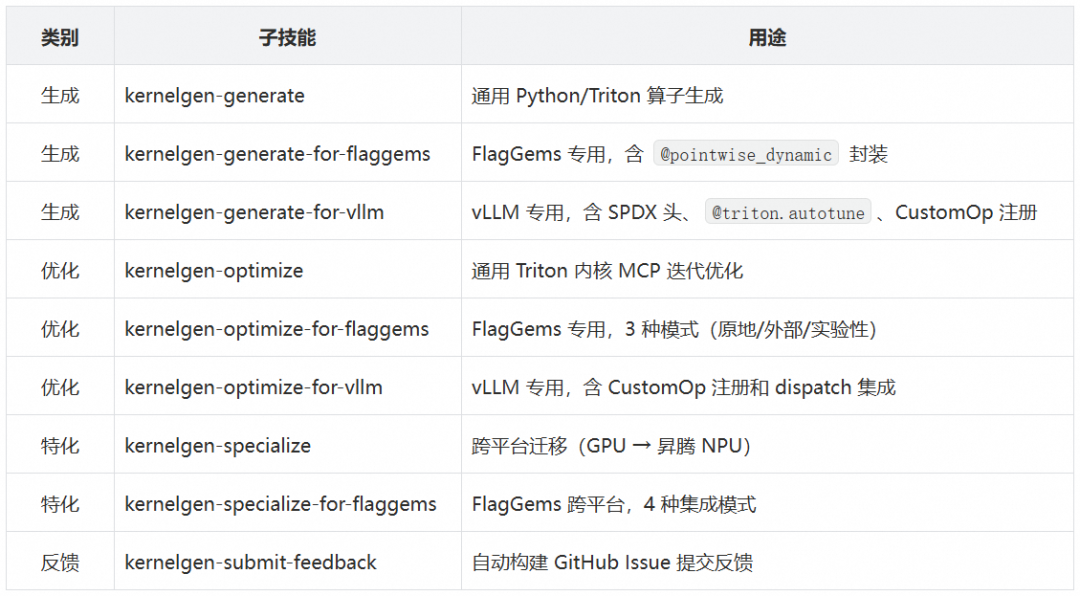
实测数据
在 KernelGen-Bench(110 个算子)上的对比测试,结果如下:
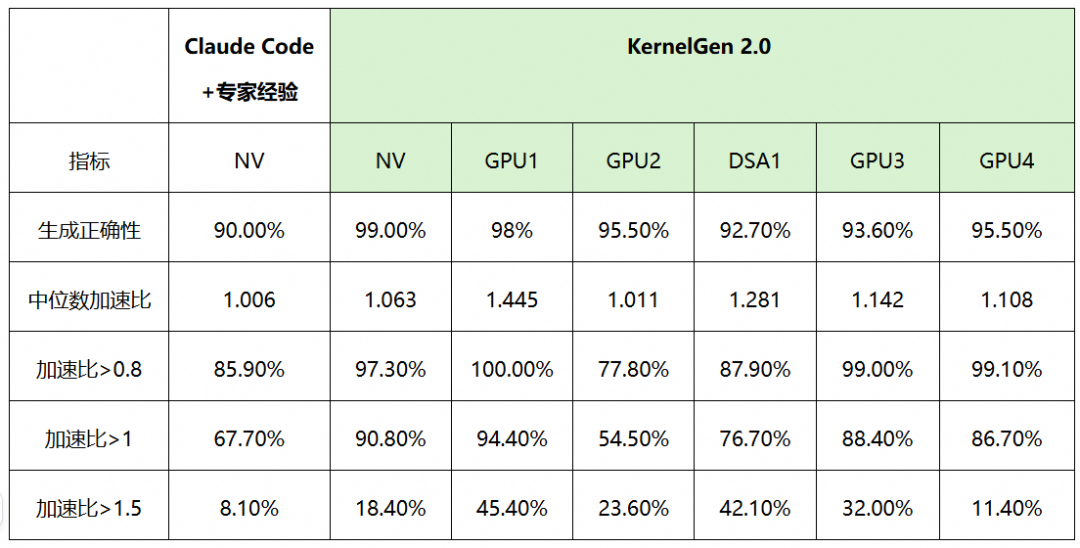
表1、KernelGen 2.0 vs Claude Code,及其在多芯片上的性能指标对比
KernelGen在英伟达上的算子生成正确性和加速比均显著超过Claude Code,在5种国产AI芯片上均获得高于95%的生成正确性,超过50%的算子性能优于芯片原生实现。
FlagOS Skills 全景
FlagOS Skills 在 FlagOS 架构中的位置
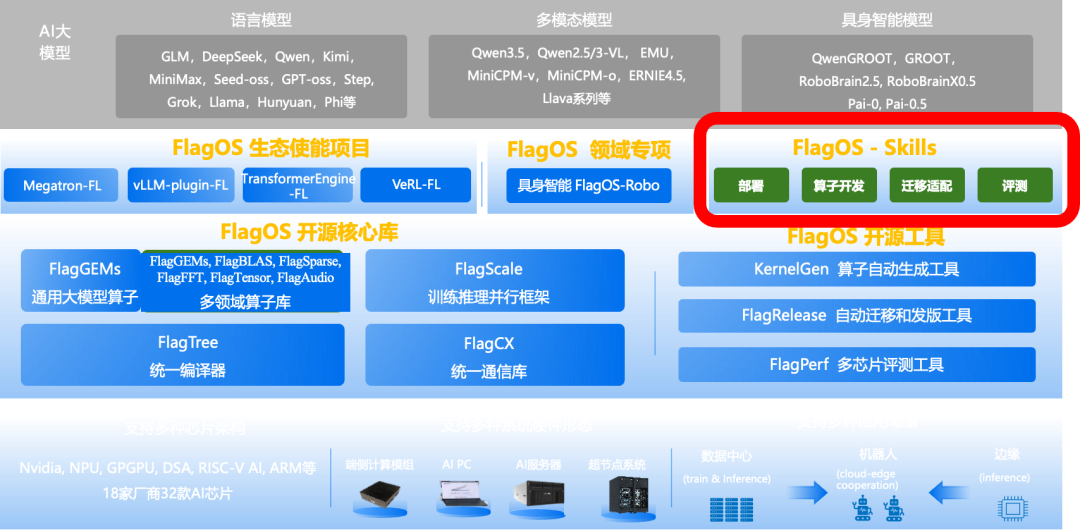
Skills 位于工具层,调用下面三层的能力:model-migrate 操作的是 FlagScale 层的 vllm-plugin-FL,kernelgen 生成的算子进入 FlagGems 层,gpu-container-setup 处理的是底层芯片环境。
FlagOS Skills 技能总览
FlagOS Skills 1.0 共发布 12 个技能:
- 部署与发布

- 基准测试与评测

- 算子与内核开发

- 开发者工具

另有多个 Skill 在规划中:FlagPerf 用例创建、部署后自动评测、复杂算子开发、实验性算子推广、算子诊断、异构训练配置等。
5 分钟上手
FlagOS Skills 兼容所有支持 Agent Skills 开放标准 的 AI 编程工具,安装后,在对话中提及 skill 名称或使用 / 命令即可触发。
# 一次安装所有 skills(推荐)
npx skills add flagos-ai/skills --all
# 安装指定 skill
npx skills add flagos-ai/skills --skill model-migrate-flagos
# 全局安装(用户级别)
npx skills add flagos-ai/skills --skill kernelgen-flagos --global
加入社区
FlagOS Skills 欢迎社区贡献。当前特别需要的方向:
- 新芯片后端适配(Dispatch 算子扩展、FlagCX 通信后端、FlagGems 芯片后端)
- 算子诊断与调优
- 异构训练配置
- FlagPerf 用例创建
GitCode:https://gitcode.com/flagos-ai/skills
GitHub:https://github.com/flagos-ai/skills
FlagOS SkillHub:https://skillhub.flagos.io
魔搭 Skills 中心:https://www.modelscope.cn/collections/FlagRelease/FlagOS-Skills
KernelGen 平台:https://kernelgen.flagos.io
KernelGen 文档:https://docs.flagos.io/projects/kernelgen/en/latest/
关于众智 FlagOS 社区
为解决不同AI芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智FlagOS社区,目前已经有78家成员单位。
FlagOS是一款专为异构AI芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
GitHub:https://github.com/flagos-ai
GitCode:https://gitcode.com/flagos-ai/
社区: https://flagos.io
点击 直达skills 合集
https://www.modelscope.cn/collections/FlagRelease/FlagOS-Skills

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献965条内容
已为社区贡献965条内容

所有评论(0)