
Qwen3.5:迈向原生多模态智能体
除夕夜的饺子刚端上桌,通义千问 Qwen 团队就为全球开源社区奉上了一份技术厚礼——正式发布 Qwen3.5 系列,并同步开源其首款权重模型:Qwen3.5-397B-A17B。
Qwen3.5-397B-A17B 是一款原生视觉-语言模型(Native Multimodality),在保持 3970 亿总参数规模的同时,通过创新的架构设计实现了仅 170 亿的单次激活参数。这意味着,开发者现在可以用更低的推理成本,获得比肩甚至超越万亿级(1T+)模型的性能体验。
模型资源
- Github:https://github.com/QwenLM/Qwen3.5
- ModelScope:https://www.modelscope.cn/models/Qwen/Qwen3.5-397B-A17B
- blog:https://qwen.ai/blog?id=qwen3.5
- Qwenchat体验:https://chat.qwen.ai/
模型核心亮点
对于开发者而言,Qwen3.5-397B-A17B 最直观的冲击力在于其极致的效能比,以 17B 的激活量,挑战 1T 的极限。
- 稀疏混合专家架构(MoE)的进化:总参数 397B,但前向传播仅激活 17B。这种超高稀疏度使得它在显存占用与计算延迟之间取得了微妙的平衡。
- 性能跨代持平:在预训练阶段,Qwen3.5-397B-A17B 在中英文、多语言、STEM 及逻辑推理等全维度基准测试中,表现与参数量超过 1T 的 Qwen3-Max-Base 旗鼓相当。
- 多模态原生化:不同于传统的“外挂”视觉模块,Qwen3.5 实现了早期的文本-视觉深度融合,在视觉理解与视频处理能力上全面超越了同规模的 Qwen3-VL。
- 多语言支持:语言与方言支持从 119 种激增至 201 种。配合全新的 25 万词表(此前为 15 万),在大多数语言上的编解码效率提升了 10%–60%,极大地优化了多语言场景下的推理速度。
模型效果实例
具备 agent 能力的 Qwen3.5 能够结合多模态做到边思考、边搜索、边调用工具
Think, search, and create
📎0bc3oab4iaadsuandmuqlvuvg4gdyryahraa.f10002.mp4
代码及智能体
网页开发
Qwen3.5 可以协助进行网页开发,尤其在构建网页和设计用户界面等前端任务方面表现出色。它能够将简单的指令转化为可运行的代码,让网站创建变得更加轻松高效
📎0bc3hebhcaacamagdtmrevuveoodoe4qe4ia.f10002.mp4
📎0b2ejibikaacvmajkjer5ruveswdqvfafbia.f10002.mp4
OpenClaw
Qwen3.5 可与 OpenClaw 集成,驱动编程任务。通过将 OpenClaw 作为第三方智能体环境集成,Qwen3.5 能够进行网页搜索、信息收集和结构化报告生成——它结合自身的推理与工具调用能力,以及 OpenClaw 的接口,为用户带来流畅的编码和研究体验。
📎0bc3deat2aabuyacqrestvuvcgodhumqcpia.f10002.mp4
输出pdf预览 ⬇️
完整pdf文档详见官方blog示例:
https://qwen.ai/blog?id=qwen3.5#openclaw
视觉智能体
GUI 智能体
Qwen3.5 可作为视觉智能体,自主操作手机与电脑完成日常任务。在移动端,它已适配更多主流应用,支持自然语言指令驱动操作;在 PC 端,能处理跨应用的数据整理、多步骤流程自动化等复杂任务,有效减少重复性人工干预,提升工作效率。
prompt:Fill the missing rows and columns which show the total value
📎0bc3d4atmaabeuacao4stnuvch6dgypqcnqa.f10002.mp4
excel
视觉编程
Qwen3.5 能将手绘界面草图转化为结构清晰的前端代码,对简单游戏视频进行逻辑还原,或将长视频内容自动提炼为结构化网页或可视化图表,降低创意到实现的门槛。
input:
prompt:复刻这个小游戏的 HTML 代码
📎0bc3fiacyaaabiadxe4tv5uvakwdfqvaalaa.f10002.mp4
output:
📎0b2ezmaz2aabsyaiu7usk5uvds6dtxfqdhia.f10002.mp4
空间智能
借助对图像像素级位置信息的建模,Qwen3.5 在物体计数、相对位置判断、空间关系描述等任务中表现更准确。它能有效缓解因视角变化或遮挡导致的误判,在自动驾驶场景理解、机器人导航等具身智能应用中展现出良好的空间感知潜力。
input:
prompt:我的车在什么时候并线的,又在什么时候开始右转的
📎0bc34maa4aaameabgsutszuvby6db3rqadqa.f10002.mp4
output:
<think>
用户希望知道两个具体的时间点:
并线(变道)的时间:车辆从当前车道移动到右侧车道(或出口匝道)的时间。
开始右转的时间:车辆开始进行明显的右转动作的时间。
分析视频:
00:00 - 00:05: 车辆在高速公路上行驶,前方有一辆卡车。路面湿滑,有雾。车辆保持在当前车道(看起来是右侧车道,或者正在接近出口)。
00:05 - 00:06: 车辆开始向右移动。可以看到车道线(虚线)在车辆左侧,车辆正在跨越这条线进入右侧的出口匝道区域。这是一个并线动作。
00:06 - 00:08: 车辆完全进入了右侧的匝道/出口车道。此时车辆基本直行,沿着匝道走。
00:08 - 00:09: 车辆继续沿着匝道行驶,前方有红白相间的警示牌。
00:09 - 00:10: 车辆开始明显向右转弯。之前的行驶方向比较直,现在车头明显指向右侧的停车场/休息区入口。
00:10 - 00:13: 车辆正在转弯进入休息区。可以看到蓝色的停车标志(P)。
00:13 - 00:19: 车辆已经在休息区内行驶,寻找停车位。
确定时间点:
并线 (Lane Change):
在 00:05 左右,车辆开始向右偏离主路,跨越虚线。
到 00:06 时,车辆已经明显进入了右侧的出口车道。
所以并线发生在 00:05 - 00:06 之间。
开始右转 (Start Turning Right):
在 00:08 之前,车辆主要是在沿着出口匝道直行。
在 00:08 - 00:09 之间,车辆经过了红白警示牌,开始向右打方向进入休息区内部道路。
最明显的右转动作开始于 00:09,此时车头明显向右偏转,进入有蓝色指示牌的区域。
所以开始右转发生在 00:09 左右。
综合结论:
并线:约 00:05
右转:约 00:09
再仔细看一下并线。 00:00-00:04 车在行车道。 00:05 车开始向右靠,压过虚线。这是并线出主路。 00:06-00:08 车在减速车道/匝道上直行。 00:09 车头明显向右转,进入服务区/停车场。
所以: 并线时间:00:05 右转时间:00:09
让我们再精确一点。 00:05 时,车辆开始向右移动,跨越车道线。 00:09 时,车辆经过路口,明显向右转弯进入停车场区域。
最终回答构建: 并线发生在 00:05。 右转发生在 00:09。
</think>
根据视频画面分析:
并线时间:您的车在 00:05 开始向右并线,驶离主路进入出口匝道。此时可以看到车辆跨越了白色的虚线车道分隔线。
开始右转时间:您的车在 00:09 开始明显右转。此时车辆已经通过了红白相间的警示牌,车头向右偏转,准备进入右侧的停车/休息区域(可以看到蓝色的“P”字指示牌)。
更多带图推理、视觉推理示例详见blog Demo
https://qwen.ai/blog?id=qwen3.5#demo
技术路线
架构创新:Gated DeltaNet 与 MoE 的融合
模型基于 Qwen3-Next 架构,创新性地将线性注意力机制与稀疏混合专家架构相结合。
混合注意力机制:引入 Gated DeltaNet + Gated Attention,在提升模型长文本建模能力的同时,优化了计算稳定性。
高稀疏度 MoE:通过提高专家网络的稀疏度,在保证性能的前提下大幅降低了计算冗余。
这种混合架构设计,是其在 BFCL-V4、VITA-Bench、DeepPlanning 等全方位基准评测中表现优异的底层逻辑。
预训练:三维度推进
Qwen 团队从能力、效率与通用性三个维度重构了预训练流程:
能力:在更大规模的视觉-文本语料上训练,并加强中英文、多语言、STEM 与推理数据,采用更严格的过滤,实现跨代持平:Qwen3.5-397B-A17B 与参数量超过 1T 的 Qwen3-Max-Base 表现相当。
效率:基于 Qwen3-Next 架构——更高稀疏度的 MoE、Gated DeltaNet + Gated Attention 混合注意力、稳定性优化与多 token 预测。在 32k/256k 上下文长度下,Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-Max 的 8.6 倍/19.0 倍,且性能相当。Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-235B-A22B 的 3.5 倍/7.2 倍。
通用性:通过早期文本-视觉融合与扩展的视觉/STEM/视频数据实现原生多模态,在相近规模下优于 Qwen3-VL。多语言覆盖从 119 增至 201 种语言/方言;25 万词表(vs. 15 万)在多数语言上带来约 10–60% 的编码/解码效率提升。
后训练:强化学习的 Scaling Law
官方Blog提到,相比 Qwen3 系列,Qwen3.5 的 Post-training 性能提升主要归功于强化学习(RL)任务和环境的全面扩展。团队不再局限于针对特定指标或狭窄类别的 query 进行优化,而是更加强调 RL 环境的难度与可泛化性。实验证明,随着 RL Environment 的 scaling,模型在通用 Agent 能力上获得了显著增益。这种“授人以渔”的训练策略,使得模型在 Tool-Decathlon、MCP-Mark 等工具调用与规划任务上表现突出。
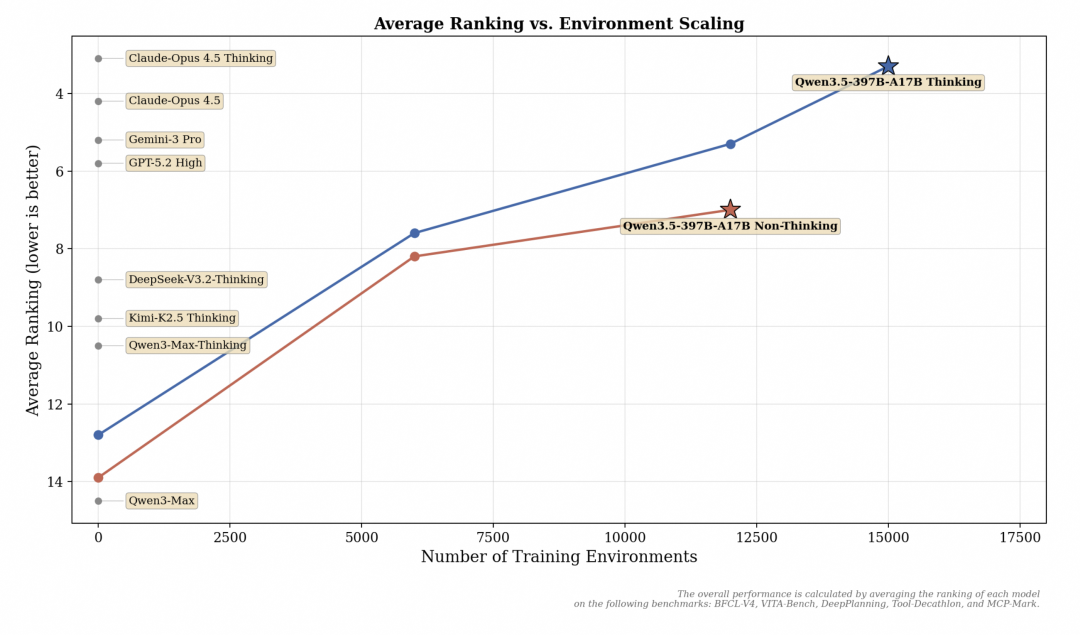
基础设施
为了支撑如此复杂的原生多模态模型训练,Qwen 团队在基础设施层进行了全栈优化。
异构并行与计算重叠
原生多模态训练最大的痛点在于视觉与语言组件的计算模式差异。Qwen3.5 采用了解耦的并行策略,在混合文本、图像、视频数据时,利用稀疏激活技术实现了跨模块的计算重叠。这一优化使得多模态训练的吞吐量几乎等同于纯文本基线,达到了近 100% 的硬件利用率。
异步强化学习框架
针对大尺寸模型的 RL 训练,团队构建了可扩展的异步框架:
- 训推分离架构:通过解耦设计,支持百万级规模的 Agent 环境交互,显著提升硬件利用率。
- 技术组合拳:引入投机采样(Speculative Sampling)、Rollout 路由回放和多轮 Rollout 锁定技术,将端到端训练速度提升了 3x–5x。
这种设计不仅消除了框架层的调度中断,更通过算法与系统的协同设计,有效缓解了 RL 训练中的数据长尾问题,提高了训练曲线的平滑度。
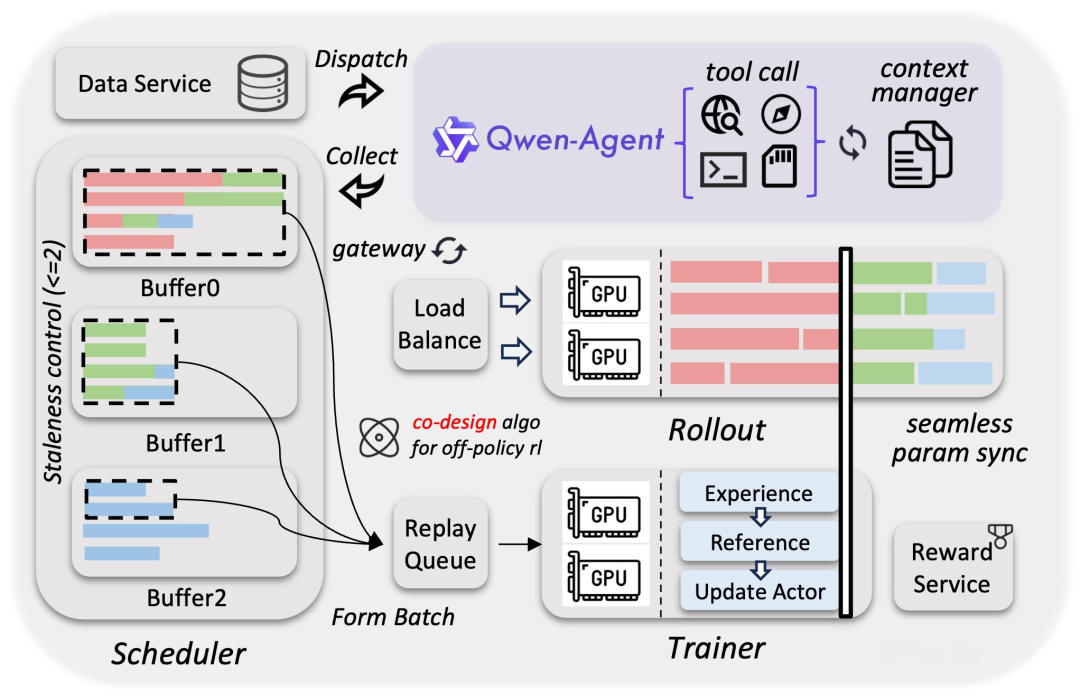
模型部署实践
SGLang
Qwen3.5 需要使用开源仓库主分支中的 SGLang,可在全新环境中通过以下命令安装:
uv pip install 'git+https://github.com/sgl-project/sglang.git#subdirectory=python&egg=sglang[all]'
以下命令将在 http://localhost:8000/v1 创建 API 端点:
标准版:以下命令可使用 8 块 GPU 上的张量并行创建最大上下文长度为 262,144 tokens 的 API 端点。
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model-path Qwen/Qwen3.5-397B-A17B --port 8000 --tp-size 8 --mem-fraction-static 0.8 --context-length 262144 --reasoning-parser qwen3
工具调用:若需支持工具调用,可使用以下命令。
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model-path Qwen/Qwen3.5-397B-A17B --port 8000 --tp-size 8 --mem-fraction-static 0.8 --context-length 262144 --reasoning-parser qwen3 --tool-call-parser qwen3_coder
多 Token 预测(MTP):推荐使用以下命令启用 MTP:
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model-path Qwen/Qwen3.5-397B-A17B --port 8000 --tp-size 8 --mem-fraction-static 0.8 --context-length 262144 --reasoning-parser qwen3 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
vLLM
Qwen3.5 需要使用开源仓库主分支中的 vLLM,可在全新环境中通过以下命令安装:
uv pip install vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
以下命令将在 http://localhost:8000/v1 创建 API 端点:
标准版本:以下命令可用于在 8 块 GPU 上使用张量并行(tensor parallel)创建一个最大上下文长度为 262,144 个 token 的 API 端点。
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-397B-A17B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3
工具调用(Tool Call):若需支持工具使用,可使用以下命令。
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-397B-A17B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder
多 Token 预测(MTP):推荐使用以下命令启用 MTP:
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-397B-A17B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
纯文本模式(Text-Only):以下命令会跳过视觉编码器和多模态分析,以释放内存用于额外的 KV 缓存:
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-397B-A17B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 --language-model-only
ModelScope API-Inference
ModelScope API-Inference已第一时间接入了 Qwen3.5-397B-A17B 的调用,社区提供免费调用额度,欢迎体验
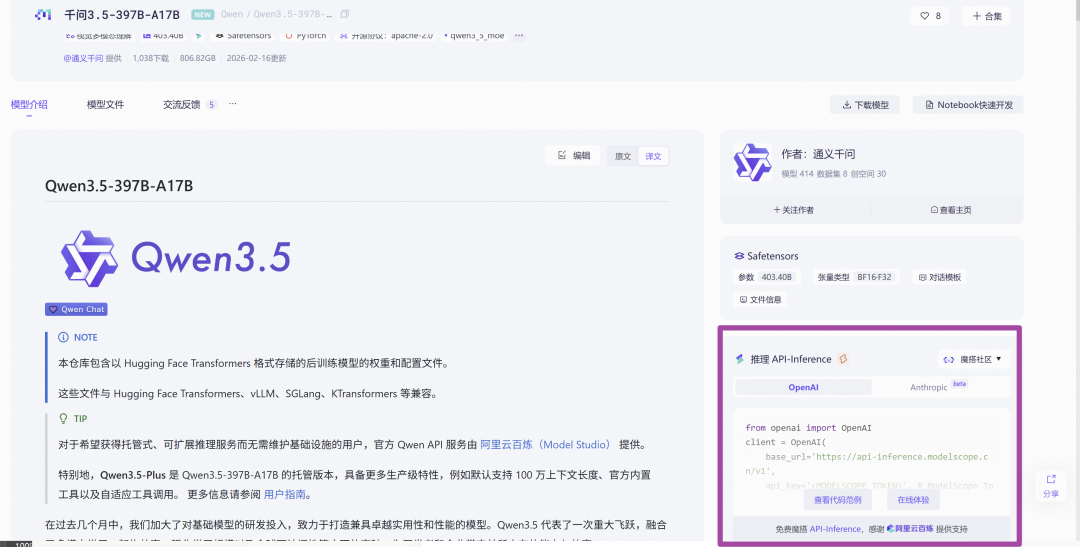
调用示例代码:
from openai import OpenAI
client = OpenAI(
base_url='https://api-inference.modelscope.cn/v1',
api_key='<MODELSCOPE_TOKEN>', # ModelScope Token
)
response = client.chat.completions.create(
model='Qwen/Qwen3.5-397B-A17B', # ModelScope Model-Id, required
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': '描述这幅图',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/audrey_hepburn.jpg',
},
}],
}],
stream=True
)
for chunk in response:
if chunk.choices:
print(chunk.choices[0].delta.content, end='', flush=True)
本次 Qwen3.5-397B-A17B 的推出:
突破了超大规模模型的推理成本难题:通过 17B 的激活参数实现 1T 的性能,Qwen3.5 证明了架构优化比单纯堆砌参数更有前景。它让中型开发者团队也有机会在本地或私有云上部署顶级性能的多模态模型。
开启了原生多模态的普及化:早期融合的架构让模型在处理图文混合任务时不再有“割裂感”,为构建下一代视觉助手、多模态 Agent 提供了最坚实的底座。
展现了强化学习的工程化典范:Qwen 团队展示了如何通过构建可扩展的 RL 环境来提升模型的逻辑上限,这为社区探索 O1 之外的推理提升路径提供了宝贵的经验。
点击即可跳转模型链接:https://www.modelscope.cn/models/Qwen/Qwen3.5-397B-A17B

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献969条内容
已为社区贡献969条内容

所有评论(0)