
全球首个自回归视频-动作世界模型,LingBot-VA 正式开源!
继本周 LingBot-Depth、LingBot-VLA 及 LingBot-World 相继开源引爆社交网络后,今天,蚂蚁灵波团队为大家奉上本次「蚂蚁灵波开源周」的收官之作:具身世界模型 LingBot-VA。
传统的机器人学习范式,如模仿学习,往往需要大量的、与特定任务紧密耦合的“状态-动作”数据对,这使得模型难以泛化到新的任务和场景。而如 LingBot-World 的世界模型的出现,为解决这一问题提供了新的可能性。它通过在仿真或真实数据中学习世界的动态规律,构建一个可预测的“内部世界”。
然而,如何将世界模型的“预测”能力,高效、可靠地转化为机器人在物理世界中的“行动”能力,一直是具身智能领域的核心挑战。LingBot-VA 的设计,正是为了打通这条从“看懂世界”到“改变世界”的路径 ——
LingBot-VA 首次提出自回归视频-动作世界建模框架,将大规模视频生成模型的能力与机器人控制深度融合,模型在生成“下一步世界状态”的同时,直接推演并输出对应的动作序列,使机器人能够像人一样“边推演、边行动”,真正将世界模型的预测能力转化为物理世界的行动能力。
在多项真实机器人评测中,LingBot-VA 展现出对复杂物理交互的强适应能力,在成功率上显著超越了业界优秀的基线模型。
技术路线:为什么选择自回归视频模型?
团队观察到,自回归视频模型在处理时序信息时,展现出两大关键优势:长期记忆能力与少样本快速学习能力。这为机器人学习提供了一条极具潜力的新路径。
长时序一致性与记忆能力
在处理包含重复状态的复杂任务时(例如,在一个任务流中需要先后两次与同一个物体交互),传统模型往往会因为无法区分相似的状态而“迷失”,陷入循环或做出错误决策。LingBot-VA 则能够记忆完整的历史信息,从而精确理解当前的上下文,做出正确的判断。
团队使用一个需要机器人执行以下操作的任务进行测试:打开右边的盒子,关闭它,然后打开左边的盒子。右边的盒子在打开前和关闭后看起来完全一样,形成了循环状态。没有记忆的话,π0.5 无法区分这些状态,会陷入循环。蚂蚁灵波的模型记住完整历史,能够正确完成任务。
📎0bc3imabyaaapaaoez33rbuvaq6ddrbqahaa.f10002.mp4
动作陷入循环的π0.5
📎0bc3baacqaaaneannhl3ufuvacgdfaeaakaa.f10002.mp4
正确完成任务的 LingBot-VA
少样本快速学习
视频模型在适应新任务时表现出卓越的数据效率。仅需少量演示,模型就能快速调整其预测以匹配目标行为。这种少样本能力大大减少了在新场景部署机器人时的数据收集负担,使实际部署更加便捷。
正是基于这些观察,团队决定探索一条“世界模型赋能具身操作”的全新路径,其核心便是 LingBot-VA 所代表的视频-动作一体化建模。
技术架构:视频-动作一体化建模
LingBot-VA 的核心思想,是构建一个统一的、自回归的视频-动作生成模型。在每一个时间步,模型不仅要根据历史信息预测出下一帧的视频画面(Video),还要同步生成驱动机器人执行该画面的动作指令(Action)。
核心架构与机制
- Mixture-of-Transformers (MoT) 架构:采用了 MoT 架构,实现视频处理与动作控制两种模态的深度融合与协同处理。
- 闭环推演机制:为了避免模型在连续生成中偏离物理现实(即“幻觉”),LingBot-VA 在每一步生成时,都会将真实世界传感器(如摄像头)的实时反馈纳入考量,形成一个“预测-执行-感知-修正”的闭环,确保持续生成的画面与动作始终与物理现实对齐。
- 异步推理与持久化:为了突破大规模视频模型在机器人端侧部署的算力瓶颈,团队设计了异步推理管线,将动作预测与电机执行并行化处理。同时,引入基于记忆缓存的持久化机制与噪声历史增强策略,使得模型在推理时仅需更少的生成步骤,即可输出稳定、精确的动作指令。
这一系列设计,使得 LingBot-VA 在拥有大模型深刻理解能力的同时,也具备了在真实机器人上进行低延迟控制的响应速度。
真实与仿真环境下的性能表现
团队在多项高难度任务中,对 LingBot-VA 的性能进行了验证。
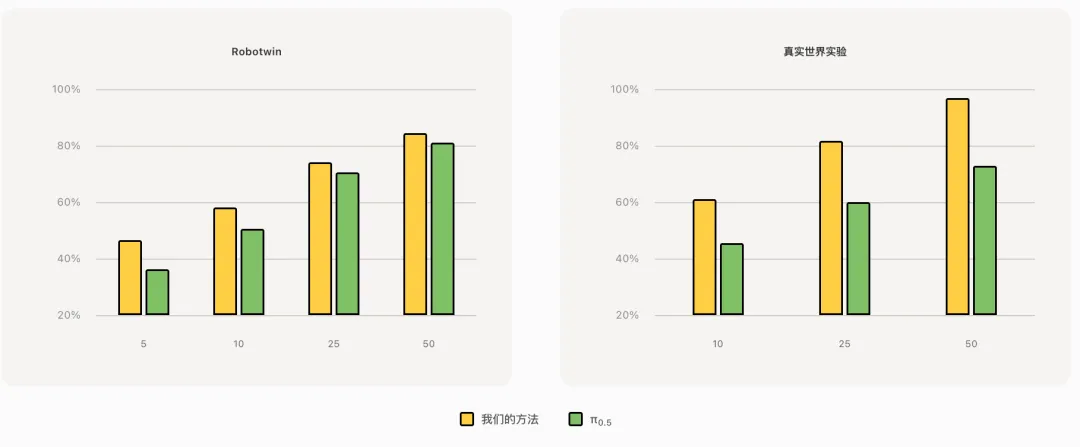
在多项真实机器人评测中,LingBot-VA 展现出对复杂物理交互的强适应能力。面对长时序任务(制作早餐、拾取螺丝)、高精度任务(插入试管、拆快递)以及柔性与关节物体操控(叠衣物、叠裤子)这三大类六项高难度挑战,仅需 30~50 条真机演示数据即可完成适配,且任务成功率相较业界强基线 Pi0.5 平均提升20%。
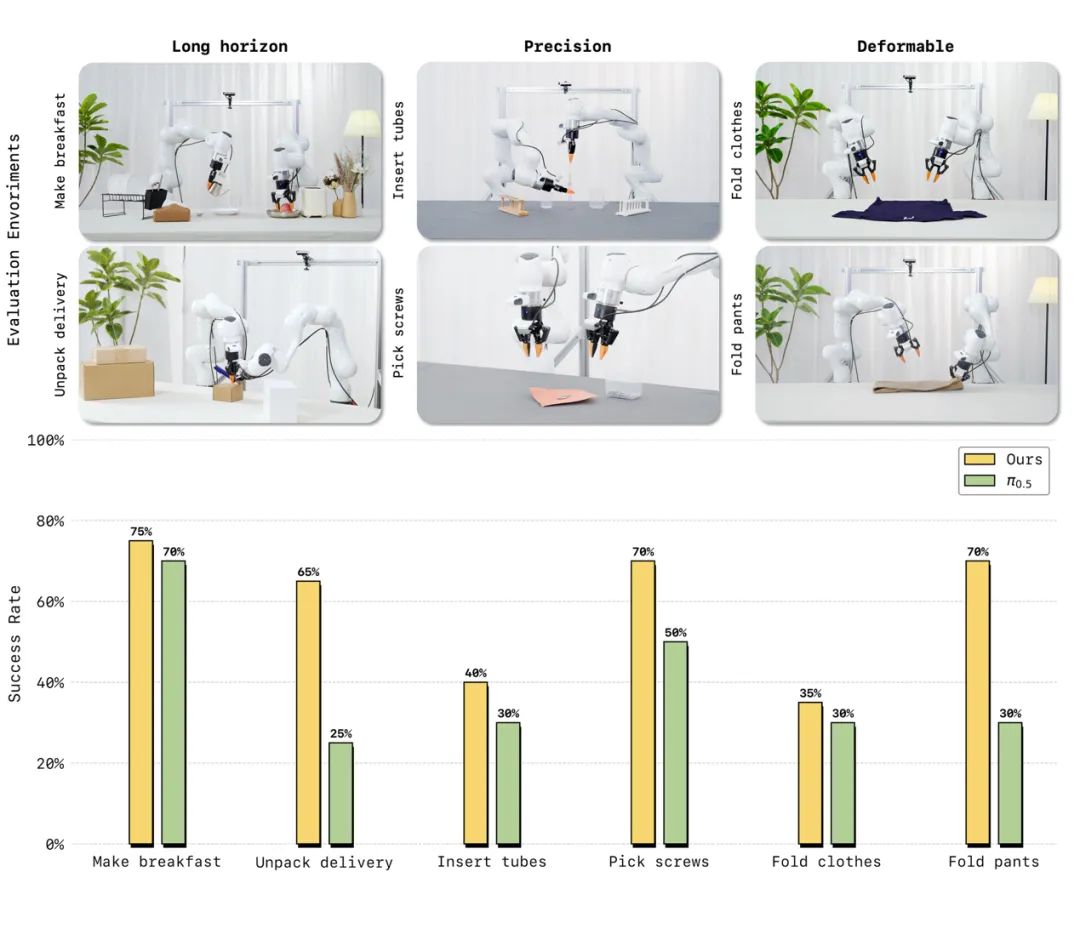
真机评测中,LingBot-VA在多项高难操作任务上性能超越业界标杆 Pi0.5
真机评测中,LingBot-VA在多项高难操作任务上性能超越业界标杆 Pi0.5
在仿真评测中,LingBot-VA 在高难度双臂协同操作基准 RoboTwin 2.0 上首次将成功率提升至超过 90%,在长时序终身学习基准 LIBERO 上达到 98.5% 平均成功率,均刷新了行业纪录。
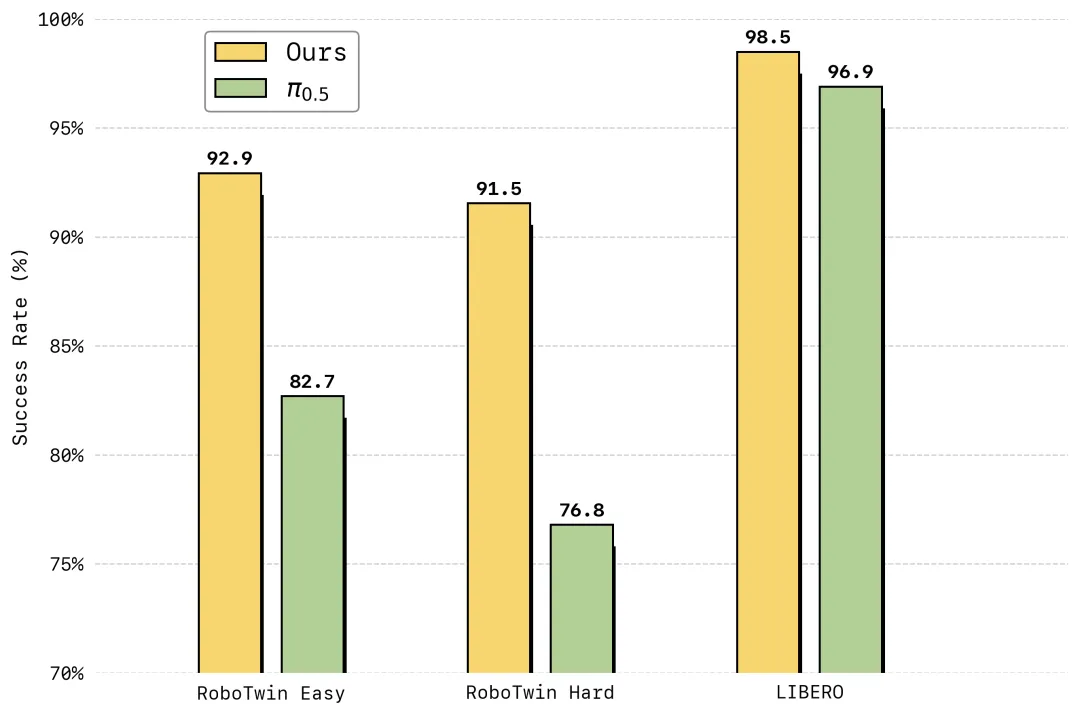
LingBot-VA 在 LIBERO 与 RoboTwin 2.0 仿真基准测试中刷新现有SOTA
目前,LingBot-VA 的模型权重、推理代码已全面开源,欢迎大家访问开源仓库。
Website:
https://technology.robbyant.com/lingbot-va
Model:
https://www.modelscope.cn/collections/Robbyant/LingBot-va
https://huggingface.co/collections/robbyant/lingbot-va
Code:
https://github.com/Robbyant/lingbot-va
Tech Report:
https://github.com/Robbyant/lingbot-va/blob/master/LingBot_VA_paper.pdf
承接前几日开源的 LingBot-World(模拟环境)、LingBot-VLA(智能基座)与 LingBot-Depth(空间感知),LingBot-VA 探索出一条“世界模型赋能具身操作”的全新路径。
本次开源周暂告一段落,但探索前沿技术的步伐不会停止。展望未来,期待继续与全球开发者、研究者、产业伙伴一起,探索具身智能的上限,加速构建一个深度融合开源开放、且服务于真实产业场景的 AGI 生态。
点击即可跳转模型链接

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献984条内容
已为社区贡献984条内容

所有评论(0)