
LingBot-VLA 具身大模型全面开源
继昨日开源高精度空间感知模型 LingBot-Depth 后,今天,蚂蚁灵波团队为大家带来了具身大模型 LingBot-VLA。
在上海交通大学开源的具身评测基准 GM-100(包含 100 项真实操作任务)测试中,LingBot-VLA 在 3 个不同的真实机器人平台上,跨本体泛化平均成功率相较于 Pi0.5 的 13.0% 提升至 15.7%(w/o Depth)。引入深度信息(w/ Depth)后,空间感知能力增强,平均成功率进一步攀升至 17.3%,展现了 LingBot-VLA 强大的准确性和泛化性。
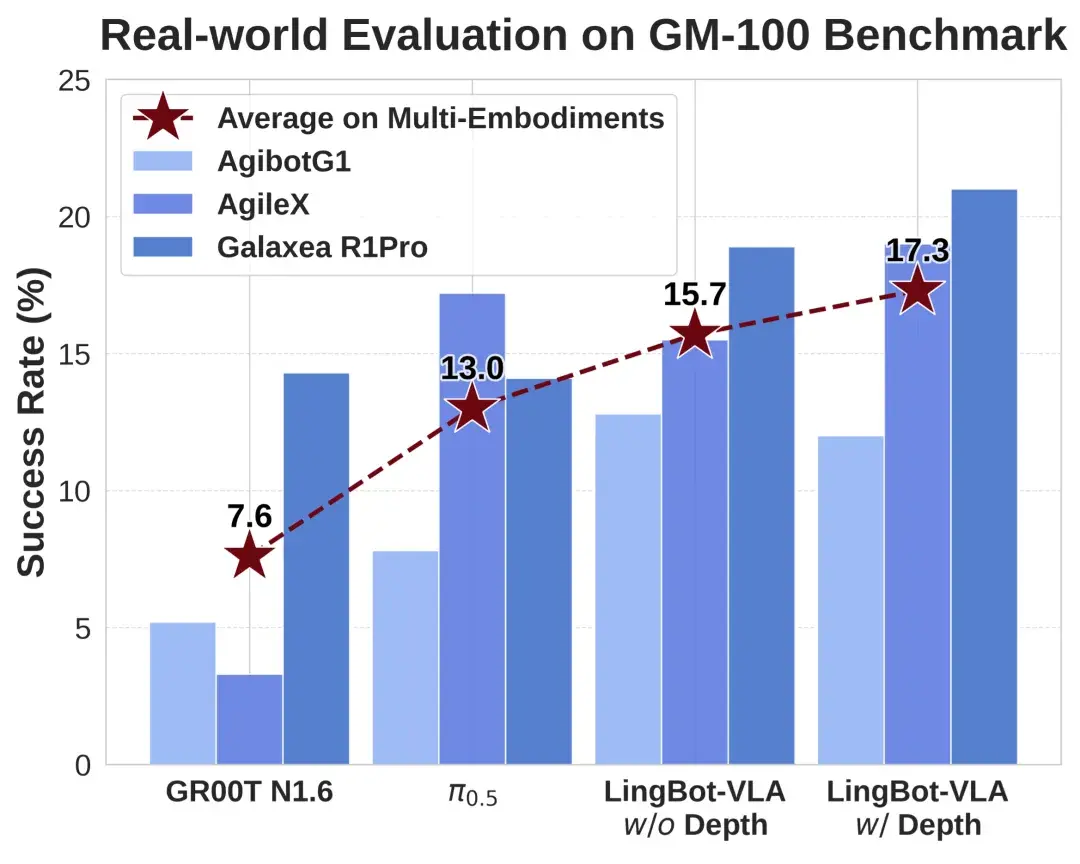
在 GM-100 真机评测中,LingBot-VLA 跨本体泛化性能领先
在 RoboTwin 2.0 仿真基准(包含50项任务)评测中,面对高强度的环境随机化干扰(如光照、杂物、高度扰动),LingBot-VLA 凭借独特的可学习查询对齐机制,高度融合深度信息,操作成功率比 Pi0.5 提升了 9.92%,实现了从虚拟仿真到真实落地的全方位性能领跑。
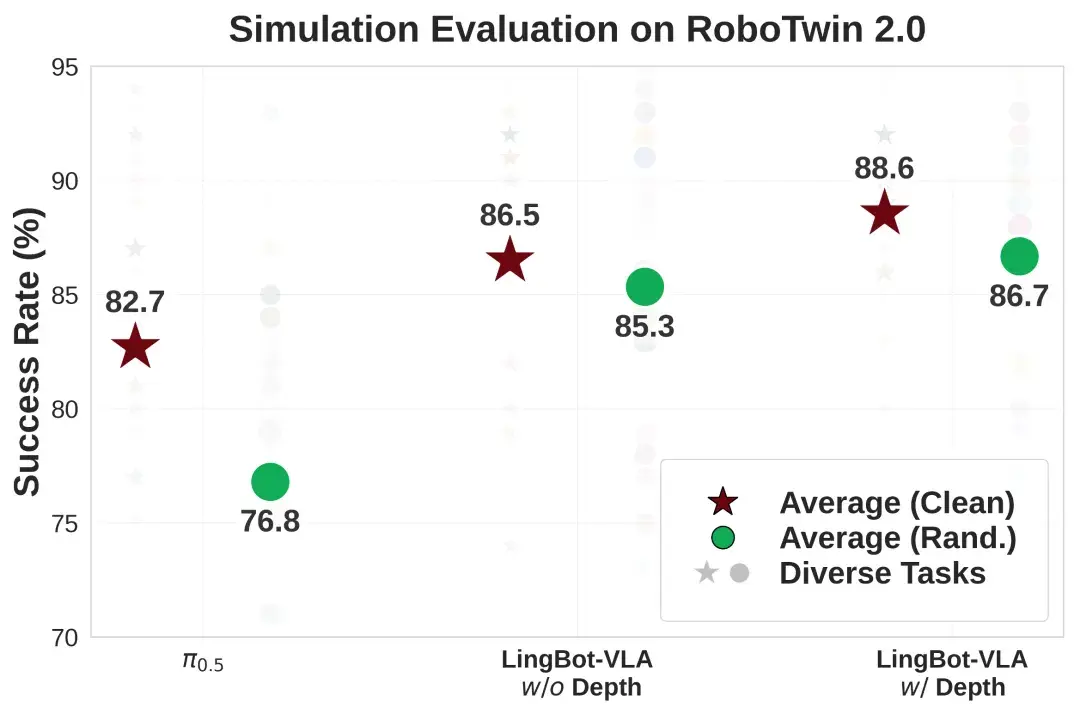
在 RoboTwin 2.0 仿真评测中,LingBot-VLA 跨任务泛化性能领先
01 Scaling Law 下的大规模真机数据预训练
长期以来,由于本体差异、任务差异、环境差异等,具身智能模型落地面临严重的泛化性挑战。开发者往往需要针对不同硬件和不同任务重复采集大量数据进行后训练,直接抬高了落地成本,也使行业难以形成可规模化复制的交付路径。
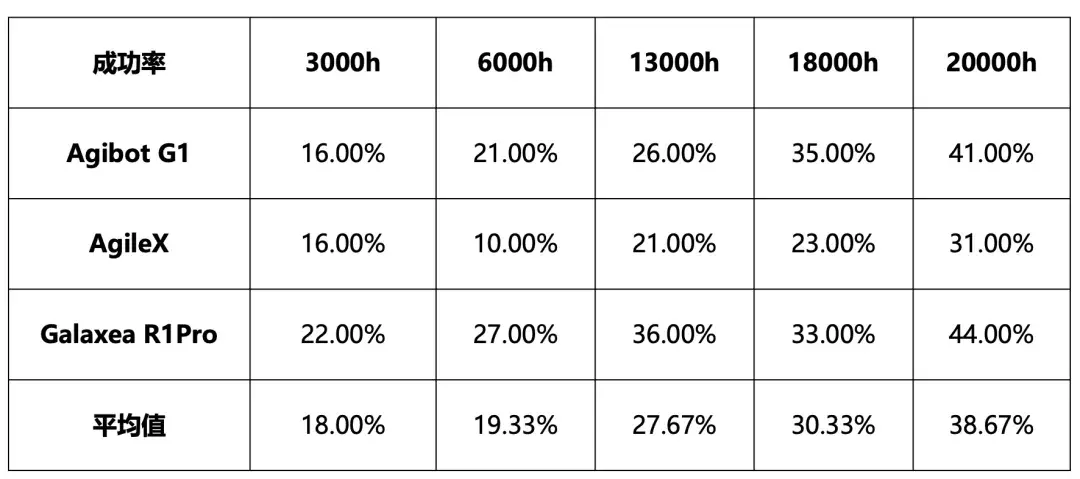
针对上述问题,团队基于在海量真实世界数据上的预训练,第一次系统研究了 VLA 模型在真实机器人任务性能上随着数据规模增长时的 Scaling Law。项目发现随着预训练数据规模从 3,000 小时扩展到 6,000、13,000、18,000,最终至 20,000 小时,模型在下游任务的成功率获得持续且显著的提升。值得注意的是,预训练数据量达到 20,000 小时时,模型性能仍呈现上升趋势,表明 VLA 的性能仍然能够随着数据量的增加而提升。这些实验结果证明了 VLA 模型在用真实数据预训练时呈现了良好的可扩展性,为未来的 VLA 开发和大规模数据挖掘提供了重要启示。

依此研究结果,团队仔细构造了 20,000 小时的真实机器人训练数据,涵盖了 9 种主流的双臂机器人构型(包括 AgileX Cobot Magic,Galaxea R1Pro、R1Lite 、AgiBot G1等)。为了进行精确的数据标注,数据里的视频由人工标注者按原子动作进行切分,并用大模型标注视频对应任务和子任务。在 codebase 的开发中,适配了 Fully Sharded Data Parallel (FSDP) 分布式、混合精度、算子融合等优化,从而让同一个“大脑”可以快速迁移至不同形态的机器人上,并在任务变化、环境变化时保持可用的成功率与鲁棒性。
02 深度信息辅助的机器人操控性能提升
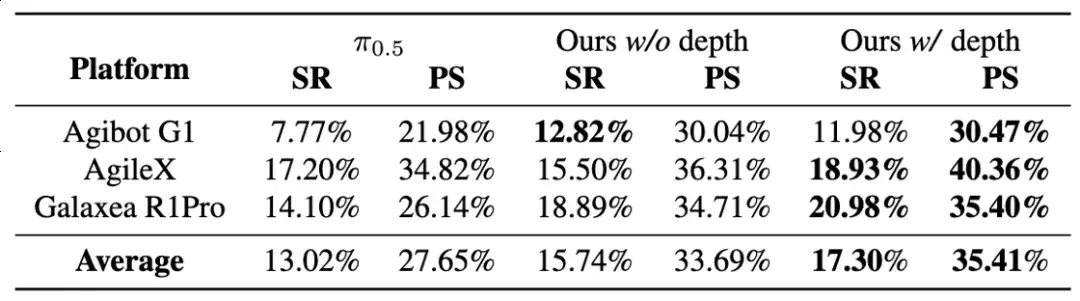
真机实验结果

仿真实验结果
为了显式捕捉操控环境中的空间感知能力,并进一步提升机器人执行的鲁棒性,团队采用了一种基于查询向量(query)的深度蒸馏方法。具体而言,团队引入了与三视角操作图像相对应的可学习 queries,这些 queries 经 VLM 处理后,与 LingBot-Depth 输出的 depth embeddings 进行对齐。这种对齐机制在维持模型训练与推理的效率的同时,有效将深度信息集成到 LingBot-VLA 中。在真实机器人平台和仿真环境下进行的广泛实验证明,深度信息的融入提升了 LingBot-VLA 的操控性能。
03 后训练成本低、效率高、代码全开源,真正实用的 VLA 模型
得益于涵盖主流构型和详尽任务的大规模预训练,LingBot-VLA 具备强大的通用操控能力,并且能够将其高效迁移到多样的下游机器人任务中。实验表明,LingBot-VLA 在下游任务中能够使用更少的数据,达到超越 π0.5 的性能;并且性能优势会随着数据量的增加而持续扩大。目前,LingBot-VLA 已与星海图、松灵、乐聚等知名机器人厂商完成适配,验证了模型在不同构型机器人上的跨本体迁移能力。
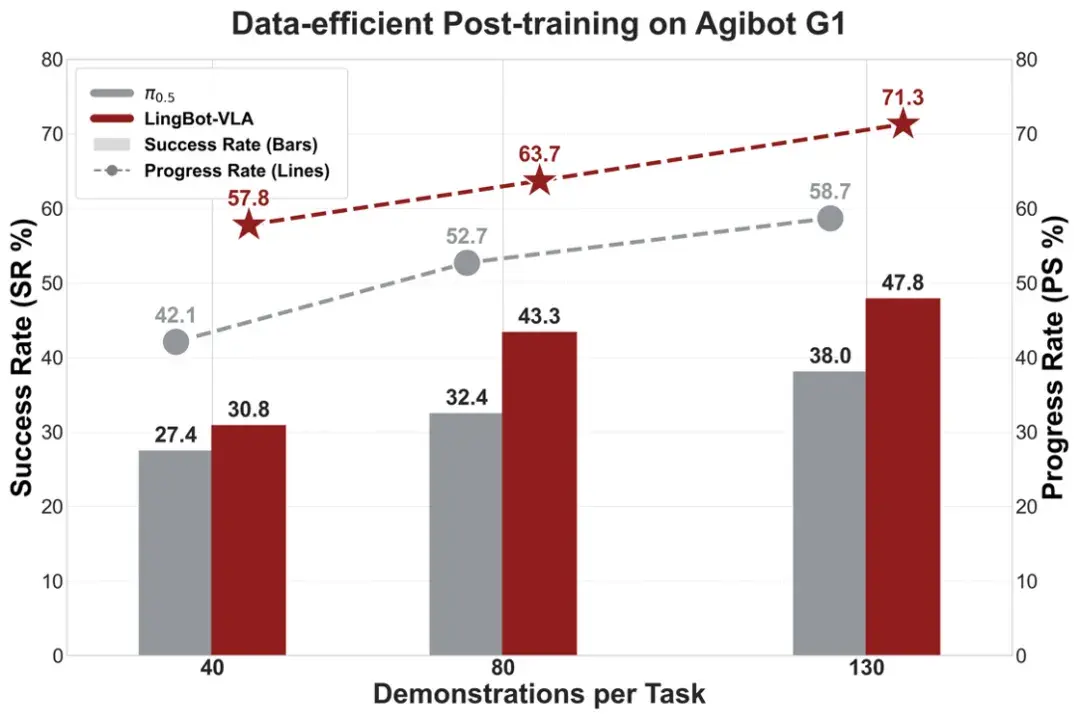
与此同时,团队构建了一套高效的后训练工具链,在 8 卡 GPU 配置下实现了单卡每秒 261 个样本的吞吐量,其训练效率达到 StarVLA、OpenPI 等主流框架的 1.5~2.8 倍,实现了数据与算力成本的双重降低。
此次开源,团队不仅提供了模型权重,还同步开放了包含数据处理、高效微调及自动化评估在内的全套代码库。团队希望这一举措可以大幅压缩模型训练周期,降低商业化落地的算力与时间门槛,助力开发者以更低成本快速适配自有场景,提升模型实用性。
目前团队的模型、后训练代码、技术报告、以及团队和上海交大共同打造的 GM-100 Benchmark 已全部开源,欢迎大家访问团队的开源仓库。
- Website:
https://technology.robbyant.com/lingbot-vla - Model:
https://huggingface.co/collections/robbyant/lingbot-vla
https://www.modelscope.cn/collections/Robbyant/LingBot-VLA - Datasets:
https://huggingface.co/datasets/robbyant/lingbot-GM-100 - Code:
https://github.com/Robbyant/lingbot-vla - Tech Report:
https://arxiv.org/abs/2601.18692
具身智能的大规模应用依赖高效的具身大模型,这直接决定了模型是否可用以及能否用得起。团队希望通过 LingBot-VLA 的开源,积极探索具身智能上限,推进具身智能研发早日进入可复用、可验证、可规模化落地的新阶段。
本周,团队已相继开源 LingBot-Depth 和 LingBot-VLA 两款模型,未来几天,团队还将陆续为大家带来团队在具身智能领域智能基座方向的更多成果。团队期待与全球开发者、研究者、产业伙伴一起,加速具身智能技术的迭代与规模化应用,助力 AGI 更快到来。
点击即可跳转模型链接
https://www.modelscope.cn/collections/Robbyant/LingBot-VLA

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 1
1- 0



 已为社区贡献984条内容
已为社区贡献984条内容

所有评论(0)