
码上生花:用API链接Qwen-Image系列及衍生LoRA生态模型
随着8月份 Qwen-Image 的开源发布,以及后续 Qwen-Image-Edit ,Qwen-Image- Edit-2509的接连更新,短短三个月的时间里,Qwen-Image系列已经成为开源社区首选的的图片生成、图像编辑模型。Qwen-Image系列模型在复杂文本渲染场景下,尤其是中文字符的排版、字体还原与语义一致性方面,表现远超同类模型,能真正实现“所写即所得”。
ModelScope社区除了支持了Qwen-Image模型的开源首发,也在第一时间将Qwen-Image系列模型的生图,以及微调训练等能力,上线到了平台的AIGC专区(https://www.modelscope.cn/aigc/)。我们也看到,社区开发者的创作热情被Qwen-Image所点燃,围绕着一系列模型的LoRA层出不穷,包括最近在Hugging Face上强势出圈的多角度转换模型,也都来自于ModelScope AIGC的模型训练平台:
下面是近期使用ModelScope AIGC专区训练出来的一些优秀的社区LoRA:
| 模型名称 | 模型功能简介 | 示例效果图 |
| Qwen-Edit-2509-Multiple-angles | 支持摄像头多角度视角变换控制 | |
| Qwen-Image-Edit-2509-Light_restoration | 光线增强,去除阴影 | |
| Qwen-Image-Edit-2509-Fusion | 矫正产品透视和光影,将物品无缝融入背景 | |
| Qwen-Image-Edit-2509-Relight | 重新照明图像,模拟窗帘漫射光等效果 | |
| Multiple-characters LoRA | 支持单张图生成多人物角色,同场景多角度呈现 | |
| Qwen-Image-Edit-2509-White_to_Scene | 将白底产品图转换为真实场景图,让物品融入场景 | |
| Qwen-Edit-2509-Workflow | 多功能编辑工作流合集:扩图、修图、虚拟试穿、姿态控制等 |
除了在AIGC专区能直接页面生图以外,ModelScope的AIGC专区同样通过API-Inference的接口,对外开放。为包括Qwen-Image在内的所有AIGC模型提供了API调用的支持。除了 Qwen-Image、Qwen-Image-Edit 、Qwen-Image- Edit-2509 这几个基础模型以外,ModelScope还为在平台上衍生的庞大LoRA模型家族,也提供了通过 API 接口,实现开箱即用的用户体验。
这里我们主要介绍 Qwen-Image 模型系列家族通过ModelScope API-Inference 调用。更多通过AIGC专区的页面使用方式,欢迎访问AIGC专区(https://www.modelscope.cn/aigc/)。
开启API-Inference使用
- 已注册 ModelScope 账号并完成实名认证
- 已获取访问令牌(Access Token):https://modelscope.cn/my/myaccesstoken
- 已绑定阿里云账号
快速开始
所有Qwen-Image系列的模型调用API的范例代码,都可以直接在模型页面上直接找到。以Qwen/Qwen-Image-Edit-2509为例:
https://www.modelscope.cn/models/Qwen/Qwen-Image-Edit-2509
从页面上即可看到通过API调用来实现包括多图编辑在内的典型使用场景所需的代码:
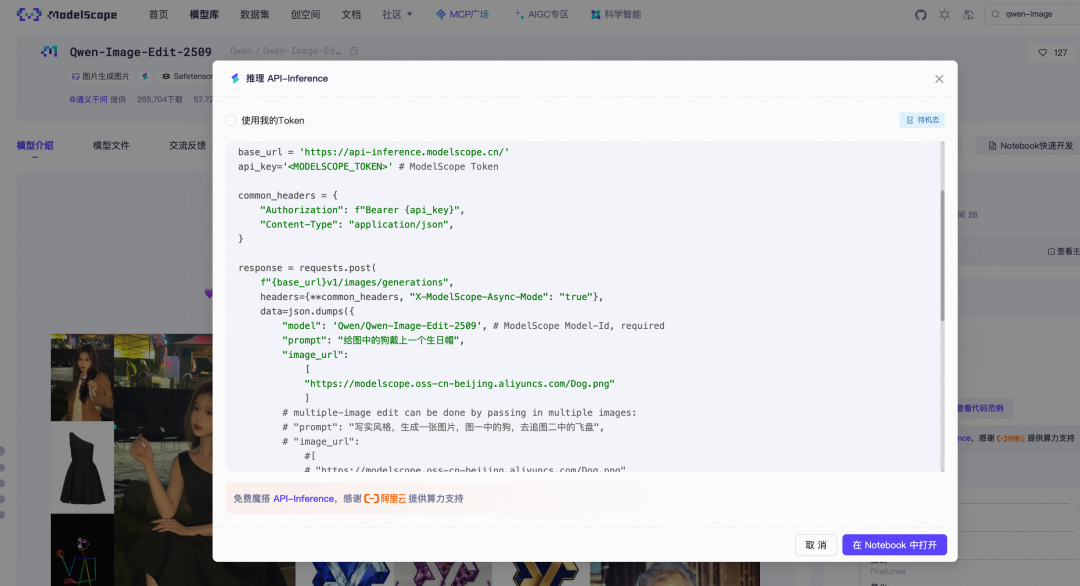
Qwen-Image 文生图调用示例
import requests
import time
import json
from PIL import Image
from io import BytesIO
base_url = 'https://api-inference.modelscope.cn/'
api_key = "<MODELSCOPE_SDK_TOKEN>" # 请替换为您的 ModelScope Access Token
common_headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
# 提交图像生成任务
response = requests.post(
f"{base_url}v1/images/generations",
headers={**common_headers, "X-ModelScope-Async-Mode": "true"},
data=json.dumps({
"model": "Qwen/Qwen-Image",
"prompt": "一只可爱的金色小猫在阳光下玩耍,毛发细节清晰,背景是温馨的家居环境,超清,4K,电影级构图",
}, ensure_ascii=False).encode('utf-8')
)
response.raise_for_status()
task_id = response.json()["task_id"]
# 轮询任务状态
while True:
result = requests.get(
f"{base_url}v1/tasks/{task_id}",
headers={**common_headers, "X-ModelScope-Task-Type": "image_generation"},
)
result.raise_for_status()
data = result.json()
if data["task_status"] == "SUCCEED":
image = Image.open(BytesIO(requests.get(data["output_images"][0]).content))
image.save("qwen_image_result.jpg")
print("图像生成成功!")
break
elif data["task_status"] == "FAILED":
print("图像生成失败")
break
time.sleep(5)
Qwen-Image-Edit-2509 图像编辑示例
import requests
import time
import json
from PIL import Image
from io import BytesIO
base_url = 'https://api-inference.modelscope.cn/'
api_key='<MODELSCOPE_TOKEN>'# ModelScope Token
common_headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(
f"{base_url}v1/images/generations",
headers={**common_headers, "X-ModelScope-Async-Mode": "true"},
data=json.dumps({
"model": 'Qwen/Qwen-Image-Edit-2509', # ModelScope Model-Id, required
"prompt": "给图中的狗戴上一个生日帽",
"image_url":
[
"https://modelscope.oss-cn-beijing.aliyuncs.com/Dog.png"
]
# multiple-image edit can be done by passing in multiple images:
# "prompt": "写实风格,生成一张图片,图一中的狗,去追图二中的飞盘",
# "image_url":
#[
# "https://modelscope.oss-cn-beijing.aliyuncs.com/Dog.png",
# "https://modelscope.oss-cn-beijing.aliyuncs.com/Frisbee.png"
#]
}, ensure_ascii=False).encode('utf-8')
)
response.raise_for_status()
task_id = response.json()["task_id"]
whileTrue:
result = requests.get(
f"{base_url}v1/tasks/{task_id}",
headers={**common_headers, "X-ModelScope-Task-Type": "image_generation"},
)
result.raise_for_status()
data = result.json()
if data["task_status"] == "SUCCEED":
image = Image.open(BytesIO(requests.get(data["output_images"][0]).content))
image.save("result_image.jpg")
break
elif data["task_status"] == "FAILED":
print("Image Generation Failed.")
break
time.sleep(5)通过 API 探索Qwen-Image 丰富的LoRA生态
除了Qwen-Image系列基础模型以外,其衍生的LoRA同样可以通过同样的API接口使用,只需要将基础模型的名字,改成LoRA模型对应的model id即可。依托ModelScope AIGC专区服务的基础设施,平台会自动加载LoRA模型所需的基础模型来实现图片的生成:
# 修改上述示例中的response部分即可
response = requests.post(
f"{base_url}v1/images/generations",
headers={**common_headers, "X-ModelScope-Async-Mode": "true"},
data=json.dumps({
"model": "MoYouuu/MYHuman-QWen", # LoRA ModelId on ModelScope
"prompt": "生成九宫格表情包,包含吐舌头、微笑、托腮、眨眼、大笑、比V手势等多种表情,保持人物身份一致,纯白背景,专业摄影棚光线"
}, ensure_ascii=False).encode('utf-8')
)这个能力使得开发者在ModelScope平台上训练的数千个LoRA模型,使得不同风格和场景的图像生成,都都能通过API实现开放:
https://modelscope.cn/aigc/models?filter=QWEN_IMAGE_20_B&page=1
API 参数说明
Qwen-Image 文生图(包括衍生LoRA)API 参数
| 参数名 | 参数说明 | 是否必须 | 参数类型 | 示例 | 取值范围 |
| model | 模型 ID | 是 | string | Qwen/Qwen-Image | Qwen-Image 系列模型 ID |
| prompt | 正向提示词,支持中英文 | 是 | string | 一只可爱的金色小猫 | 长度小于 2000 字符 |
| negative_prompt | 负向提示词 | 否 | string | 模糊,低质量,变形 | 长度小于 2000 字符 |
| size | 生成图像分辨率 | 否 | string | 1024x1024 | 支持多种宽高比,详见下表 |
| seed | 随机种子 | 否 | int | 42 | [0, 2³¹-1] |
| steps | 采样步数 | 否 | int | 50 | [1, 100] |
| guidance | 提示词引导系数 | 否 | float | 4.0 | [1.5, 20] |
Qwen-Image-Edit-2509 图像编辑(包括衍生LoRA)API 参数
| 参数名 | 参数说明 | 是否必须 | 参数类型 | 示例 | 取值范围 |
| model | 模型 ID | 是 | string | Qwen/Qwen-Image-Edit-2509 | Qwen-Image-Edit 系列模型 ID |
| images | 输入图像列表(base64) | 是 | array | [[base64], [base64]] | 多图像编辑,1-3 张 |
| prompt | 编辑指令 | 是 | string | 改变服装为旗袍 | 长度小于 2000 字符 |
| negative_prompt | 负向提示词 | 否 | string | 模糊,低质量 | 长度小于 2000 字符 |
| steps | 采样步数 | 否 | int | 40 | [1, 100] |
| guidance | 提示词引导系数 | 否 | float | 4.0 | [1.5, 20] |
| seed | 随机种子 | 否 | int | 42 | [0, 2³¹-1] |
更多
在过去3个月的时间里,我们目睹了Qwen-Image系列模型从发布,到迅速成长为AIGC领域头部的开源模型。社区生态的LoRA层出不穷,数量迅速从数百增加到数千,乃至逼近万的量级。从我们的AIGC专区训练微调产生的诸多模型,除了在ModelScope社区,也已经在包括Hugging Face在内的不同社区和平台上屡屡出圈。
我们期待通过社区的支持以及围绕ModelScope API-Inference接口开放的能力,能够进一步推进整个视觉生成领域开源社区生态的进一步丰富。一方面ModelScope会持续保障下一代的基础模型第一时间的接入,此外在API支持方面,包括多LoRA链式加载在内的诸多高阶能力以及更灵活的参数配置,我们也计划后续在API层面做更好的支持和透出,敬请期待!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献986条内容
已为社区贡献986条内容

所有评论(0)