
Mcore Bridge:迈向Megatron训练"零门槛"时代
在大语言模型训练领域,Megatron以其卓越的训练效率和先进的并行技术而备受瞩目。然而,其高性能背后的技术复杂性——依赖环境难安装、权重格式需转换、参数配置复杂,让众多研究者和工程师望而却步。
为破解这一困境,魔搭社区先后推出了Megatron-SWIFT和Mcore-Bridge两大利器:支持通过命令行一键启动、基于safetensors模型权重直接训练、无需手动权重转换,让Megatron训练开箱即用,逐步达到与Transformers相当的易用性水平。

六个月前,魔搭社区推出Megatron-SWIFT,将Megatron训练引擎与ms-swift简单易用的开发范式相结合,达到了高性能和易用性之间的平衡:
- 并行技术:通过引入张量并行(TP)、流水线并行(PP)、专家并行(EP)、上下文并行(CP)及虚拟流水线并行(VPP)等前沿并行策略,Megatron-SWIFT在混合专家(MoE)模型训练中实现了相较于Transformers + DeepSpeed 后端10倍的加速比,显著降低了训练时间成本与资源消耗。
- 全模态模型覆盖:支持250+纯文本大模型,包括Qwen3-Moe、Deepseek-R1、GLM4.5、Qwen3-Next等前沿模型,此外支持100+多模态大模型模型,包括Qwen3-VL、Qwen3-Omni、InternVL3.5、Ovis2.5、GLM4.5-V、Kimi-VL等热门模型。
- 丰富的训练范式:支持全参数、LoRA训练方式;支持继续预训练(CPT)、指令微调(SFT)、偏好对齐(DPO/KTO)、奖励模型(RM)等训练阶段。
- 命令行启动模式:延续了ms-swift简洁、快速上手的设计理念,研究者仅需聚焦数据与算法而无需关注工程细节,大幅降低了Megatron训练的上手难度。
如今,Mcore-Bridge的发布,进一步降低了Megatron训练的使用门槛,让Megatron训练带来的性能加速,成为“免费的午餐”。
- 原生safetensors格式支持:彻底移除权重格式转换的繁琐环节,支持直接加载与保存safetensors格式模型,实现训练流程的无缝集成。
- LoRA 增量权重的双向转换:Megatron-SWIFT训练产出的LoRA权重可完美接入PEFT生态,支持vLLM多LoRA 动态切换部署等场景。
- 强化学习(RL)权重同步支持:兼容GRPO/GKD等算法的 Megatron->vLLM 权重同步。通过将权重导出接口设计为生成器模式,每次仅返回单层完整权重,精准控制RL训练中同步权重带来的额外显存消耗。
- 支持超大规模模型:支持TP/PP/EP/ETP/VPP等并行策略,提供多机转换超大规模模型的能力。
- 模型架构覆盖与精度保障:支持Dense、MoE、Vision-Language、Omni等Megatron-SWIFT覆盖的所有模型架构;训练完成的模型可无缝对接Transformers、vLLM、SGLang等推理生态。此外,每个模型均经过严格精度验证,确保转换前后的模型前向传播数值对齐。
01Megatron显著加速Moe模型训练
Megatron在混合专家(MoE)模型的训练中具有显著性能优势,通过引入先进并行技术以及GEMM算子优化,Megatron-SWIFT相较于transformers + DeepSpeed技术栈实现了10倍训练加速。
以下分别测试了Megatron和Deepspeed训练后端在Dense和Moe模型下的训练速度。
Dense模型(Qwen2.5-14B, 单机8×A800, 8K上下文):
| Megatron | Deepspeed-ZeRO2 | Deepspeed-ZeRO3 | |
| 训练速度 | 9.04s/it | 10.32s/it | 10.56s/it |
| 显存占用 | 8*64GB | 8*80GB | 8*58GB |
MoE模型(Qwen3-30B-A3B, 双机16×A800, 8K上下文):
| Megatron | DeepSpeed-ZeRO2 | DeepSpeed-ZeRO3 | |
| 训练速度 | 9.6s/it | - | 91.2s/it |
| 显存使用 | 16 * 60GiB | OOM | 16 * 80GiB |
02Mcore-Bridge初体验
接下来,我们以实战的方式,体验Mcore-Bridge带来的灵活和方便。更多Mcore-Bridge的介绍,可以参考文档:https://swift.readthedocs.io/zh-cn/latest/Megatron-SWIFT/Mcore-Bridge.html
训练体验
首先,你需要准备训练环境,推荐使用魔搭社区提供的ms-swift镜像:
modelscope-registry.cn-hangzhou.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda12.8.1-py311-torch2.8.0-vllm0.11.0-modelscope1.31.0-swift3.9.3
modelscope-registry.cn-beijing.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda12.8.1-py311-torch2.8.0-vllm0.11.0-modelscope1.31.0-swift3.9.3
注意:目前Mcore-Bridge功能在ms-swift main分支中,需额外从源码安装ms-swift(>=3.10)。
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .若是手动安装相关依赖,请参考官方文档:https://swift.readthedocs.io/zh-cn/latest/Megatron-SWIFT/%E5%BF%AB%E9%80%9F%E5%BC%80%E5%A7%8B.html
以Qwen3-30B-A3B-Instruct-2507的自我认知LoRA微调为例,演示如何通过单一命令完成训练:
核心参数介绍:
--load_safetensors true:直接加载safetensors格式权重。--save_safetensors true:保存为safetensors格式权重。--merge_lora false:仅保存LoRA增量权重。(可设为true导出完整合并权重)
# 2 * 41GiB
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 \
megatron sft \
--model Qwen/Qwen3-30B-A3B-Instruct-2507 \
--load_safetensors true \
--save_safetensors true \
--merge_lora false \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--load_from_cache_file true \
--train_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--split_dataset_ratio 0.01 \
--moe_permute_fusion true \
--expert_model_parallel_size 2 \
--moe_grouped_gemm true \
--moe_shared_expert_overlap true \
--moe_aux_loss_coeff 1e-6 \
--micro_batch_size 8 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 1 \
--max_epochs 1 \
--finetune true \
--cross_entropy_loss_fusion true \
--lr 1e-4 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-5 \
--save megatron_output/Qwen3-30B-A3B-Instruct-2507 \
--eval_interval 200 \
--save_interval 200 \
--max_length 2048 \
--num_workers 8 \
--dataset_num_proc 8 \
--no_save_optim true \
--no_save_rng true \
--sequence_parallel true \
--moe_expert_capacity_factor 2 \
--attention_backend flash \
--model_author swift \
--model_name swift-robot训练完成后,可直接使用ms-swift进行推理测试:
CUDA_VISIBLE_DEVICES=0,1 \
swift infer \
--adapters megatron_output/Qwen3-30B-A3B-Instruct-2507/vx-xxx/checkpoint-xxx \
--stream true

Pythonic API调用Mcore-Bridge
Mcore-bridge提供了编程式API,方便在自定义训练流程中集成:
# test.py
import torch
from swift.llm import get_model_tokenizer
from swift.megatron import MegatronArguments, convert_hf_config, get_megatron_model_meta
from megatron.training.initialize import initialize_megatron
model_id = 'Qwen/Qwen3-30B-A3B-Instruct-2507'
_, processor = get_model_tokenizer(model_id, load_model=False, download_model=True)
model_info = processor.model_info
megatron_model_meta = get_megatron_model_meta(model_info.model_type)
config_kwargs = convert_hf_config(model_info.config)
megatron_args = MegatronArguments(
model=model_id,
tensor_model_parallel_size=2,
pipeline_model_parallel_size=2,
expert_model_parallel_size=2,
sequence_parallel=True,
torch_dtype=torch.bfloat16,
**config_kwargs,
)
extra_args = megatron_args.parse_to_megatron()
initialize_megatron(args_defaults=extra_args)
# 创建模型
mg_model = megatron_model_meta.model_provider()
# 加载权重
bridge = megatron_model_meta.bridge_cls()
bridge.load_weights(mg_model, model_info.model_dir)
# 导出权重
for name, parameters in bridge.export_weights([mg_model]):
pass
# 保存权重
bridge.save_weights([mg_model], 'output/Qwen3-30B-A3B-Instruct-2507-new')
运行方式如下,以上代码也非常方便使用VSCode进行断点调试。
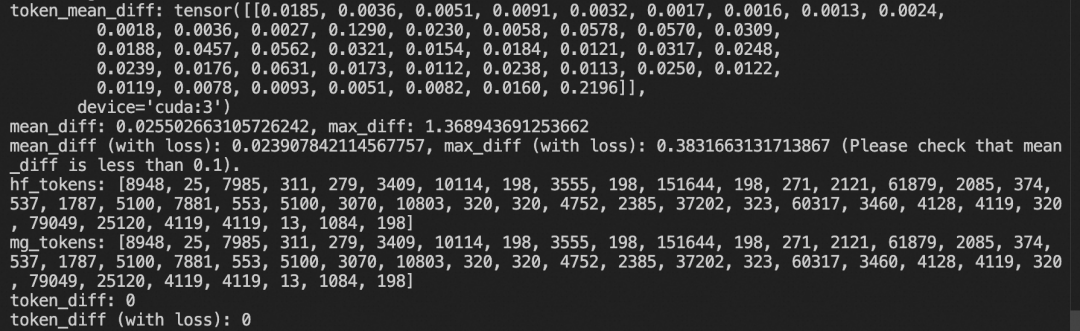
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 test.pyMcore-Bridge内置了精度对齐的测试工具,以评估模型在Megatron与Transformers实现之间的精度误差,这对新模型接入至关重要。
使用方法:
只需在权重转换时添加--test_convert_precision true参数:
CUDA_VISIBLE_DEVICES=0,1,2,3 \
NPROC_PER_NODE=4 \
megatron export \
--model Qwen/Qwen3-30B-A3B-Instruct-2507 \
--save Qwen3-30B-A3B-Instruct-2507-mcore \
--to_mcore true \
--tensor_model_parallel_size 2 \
--expert_model_parallel_size 2 \
--pipeline_model_parallel_size 2 \
--test_convert_precision true
04总结
Mcore-Bridge的引入,结合Megatron-SWIFT,共同构建了Megatron训练高性能和易用性统一的解决方案。
- 性能飞跃:Megatron-SWIFT在混合专家(MoE)模型训练中实现了相较于Transformers+DeepSpeed后端10倍加速比,显著降低训练成本。
- 无额外成本:Mcore-Bridge的引入,彻底移除了权重转换的繁琐过程,支持原生safetensors格式,让Megatron训练带来的性能提升成为"免费的午餐"。
- 开箱即用:延续ms-swift简单易用的设计理念,通过命令行启动、开箱即用的镜像、完善的文档支持,让Megatron训练不再有任何技术门槛,使广大开发者都能无感体验并行技术与大模型训练的完美结合。
随着大模型架构的持续发展和创新,该工具链也将持续演进,为研究社区与工业界提供更强大的基础设施支撑。
ms-swift项目地址:
https://github.com/modelscope/ms-swift
Megatron-SWIFT训练交流群


ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献969条内容
已为社区贡献969条内容

所有评论(0)