
大模型微调实战指南:从零开始手把手教你微调大模型,收藏这篇就够了
本文手把手带你从零微调大模型。大模型微调复杂且技术难度高,本文仅带你走一遍微调过程,不涉过多技术细节,希望助你了解微调流程 。
今天分享技术文章。你或许听过很多大模型知识,却未亲自用或微调过大模型。
本文手把手带你从零微调大模型。大模型微调复杂且技术难度高,本文仅带你走一遍微调过程,不涉过多技术细节,希望助你了解微调流程 。
一、微调简介
微调大模型需高电脑配置,如 GPU 环境,即在预训练基础上对大模型小训练。
无需担心,本文用阿里魔塔社区集成环境,无需自备电脑配置环境,有浏览器即可完成。
本次微调零一万物的 Yi 开源大语言模型,微调其他大模型过程和原理类似。话不多说,直接开始。
二、微调正文
1. 账号和环境准备
首先你需要注册和登录魔搭的账号:https://modelscope.cn/home
注册完成后,登录这个模型网址:
https://www.modelscope.cn/models/01ai/Yi-1.5-6B
然后按照下面的箭头操作。
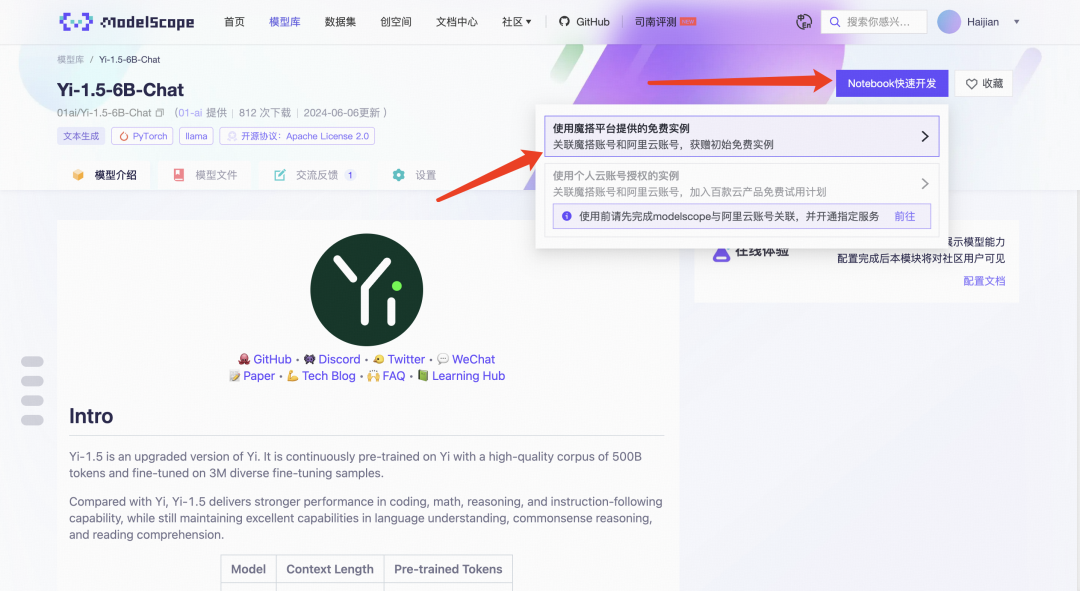
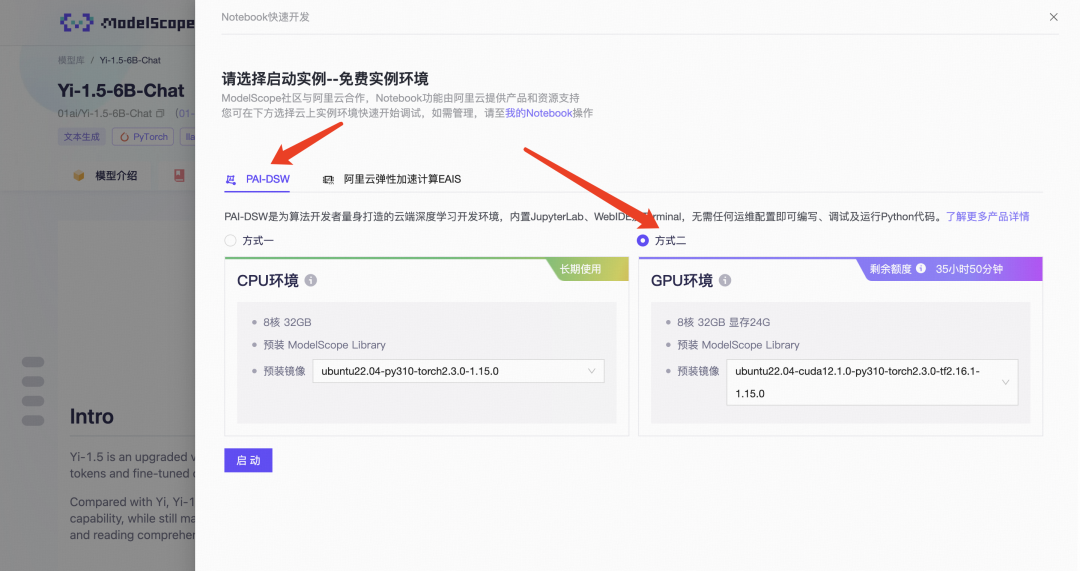
选择完方式二:GPU环境后,点击“启动”。
启动约 2 分钟,GPU 环境启动好后点击"查看NoteBook"进入。魔塔社区有 JupyterLab 功能,进入后找 Notebook 标签新建 Notebook(也可在 terminal 执行)。
如下箭头所示,点击即可创建一个新的 Notebook 页面。
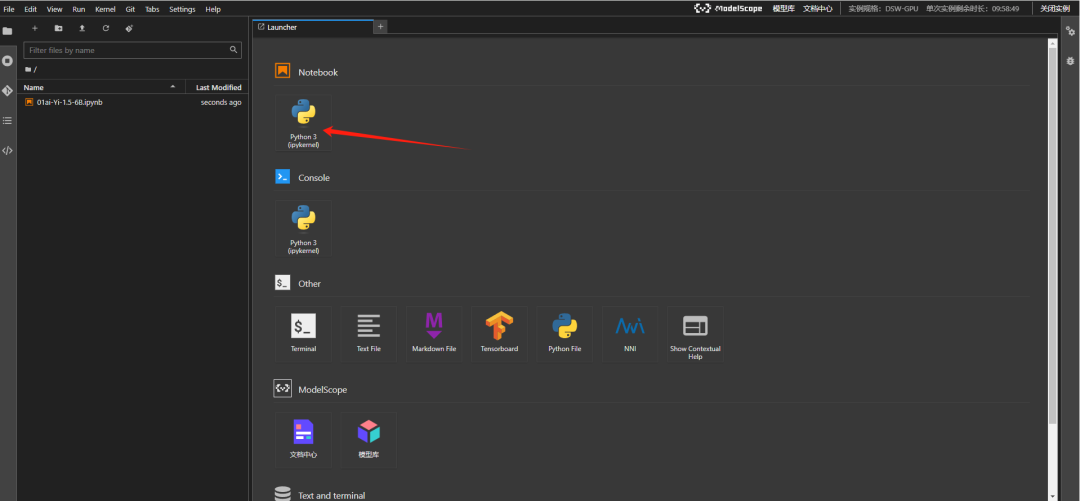
增添一个代码块,并且执行以下命令(点击左侧的运行按钮运行该代码块,下同,这一步是安装依赖库)。
!pip3 install --upgrade pip
!pip3 install bitsandbytes>=0.39.0
拉取 LLaMA-Factory,过程大约需要几分钟
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
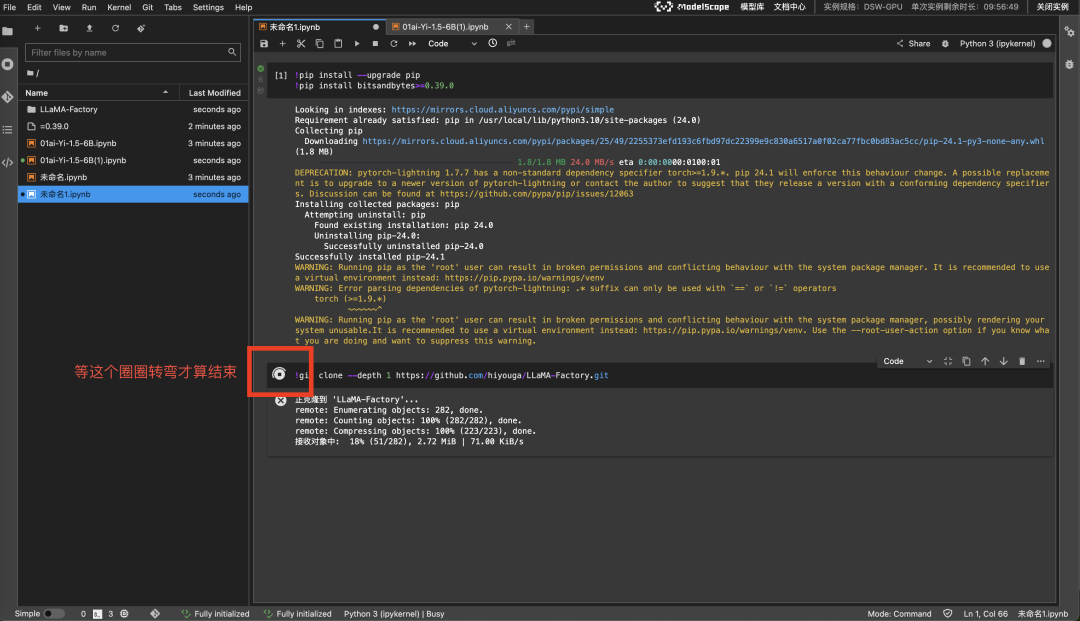
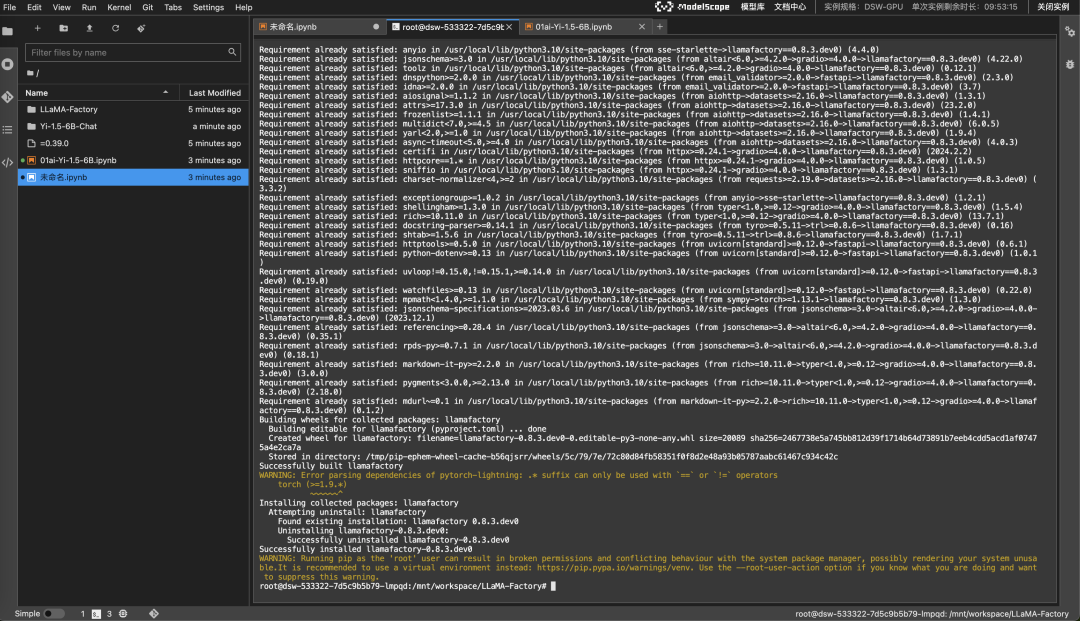
接下来去 Launcher > Terminal 执行(按图片箭头指示)。安装依赖软件,耗时较长。
# ⚠️下面两行命令在刚启动的Terminal中执行⚠️
cd LLaMA-Factory
pip3 install -e ".[torch,metrics]"
等以上所有步骤完成后,再进行下面的操作。
2. 下载模型
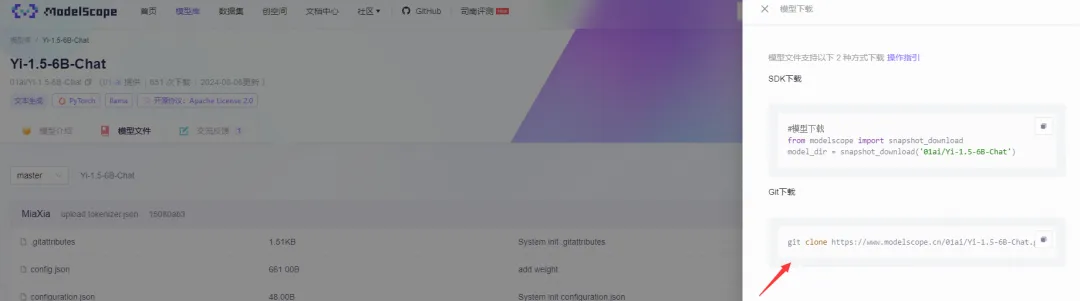
零一万物的Yi开源大语言模型权重可在HuggingFace和ModelScope找到,我选从ModelScope下载。模型下载需时,选最小的Yi-1.5-6B-chat模型实验。
模型的说明在这里:
https://www.modelscope.cn/models/01ai/Yi-1.5-6B-Chat/summary
Yi-1.5-6B-chat模型大小大约12G,下载大约需要10分钟(取决于网速)。
接下来,你通过下面的命令就可以在 notebook 里执行下载(在 terminal也一样,如果需要在terminal执行需要去掉前面的!)。
!git clone https://www.modelscope.cn/01ai/Yi-1.5-6B-Chat.git
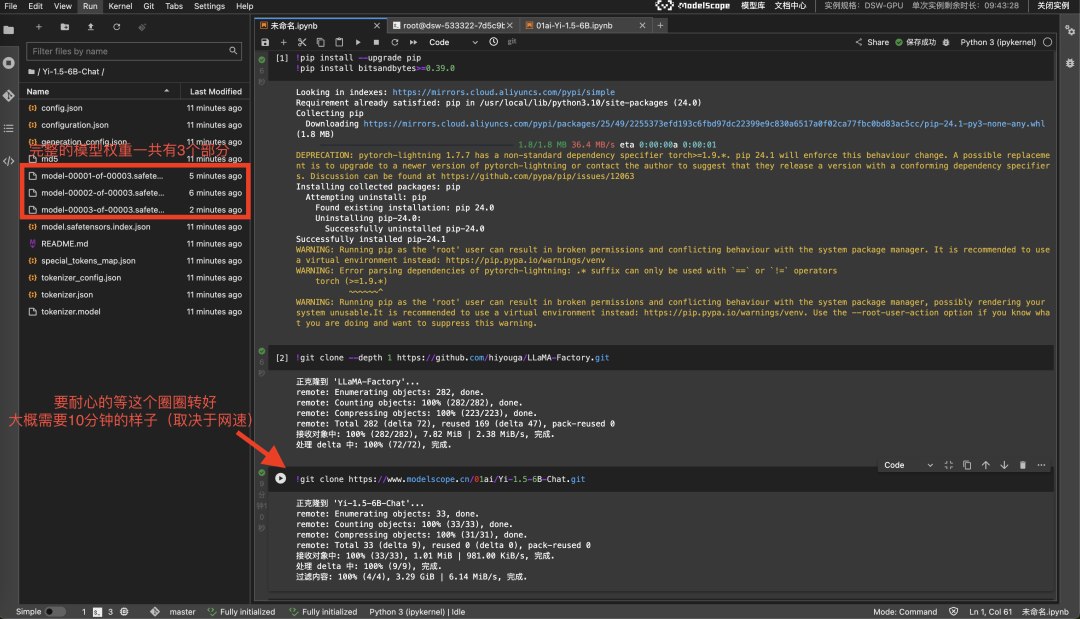
这一步,耐心等待下载完成即可。
3. 微调Yi模型实战
等以上所有步骤完成后,准备工作就做好了,现在可以开始准备微调了。
这里选择llama_factory。LLaMA Factory是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术。
4. 开始微调
a. 创建微调训练相关的配置文件
在左侧的文件列表,Llama-Factory的文件夹里,打开examples\train_qlora(注意不是 train_lora)下提供的llama3_lora_sft_awq.yaml,复制一份并重命名为yi_lora_sft_bitsandbytes.yaml。
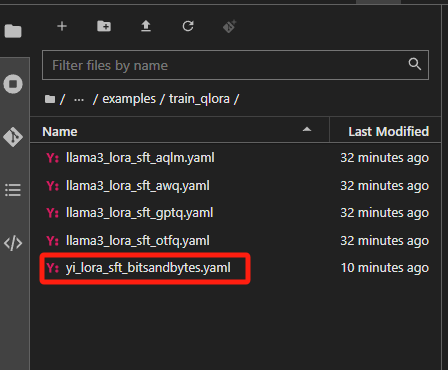
这个文件里面写着和微调相关的关键参数。
打开这个文件,将第一行model_name_or_path更改为你下载模型的位置。
### model
model_name_or_path: <你下载的模型位置,不要带括号,比如我写了../Yi-1.5-6B-Chat>
同样修改其他行的内容,可以逐行对比一下,有不一致或缺少的就添加一下。

从上面的配置文件中可以看到,本次微调的数据集是 identity。

微调数据集为“自我认知”,问“你好你是谁”,模型会答我叫name由author开发。若将数据集改成自己名字,就能微调自己的大模型,可把identity.json里的{{name}}字段换成自己名字来实现。
保存刚才对于 yi_lora_sft_bitsandbytes.yaml 文件的更改,回到终端terminal。
在 LLaMA-Factory 目录下,输入以下命令启动微调脚本(大概需要10分钟)
llamafactory-cli train examples/train_qlora/yi_lora_sft_bitsandbytes.yaml
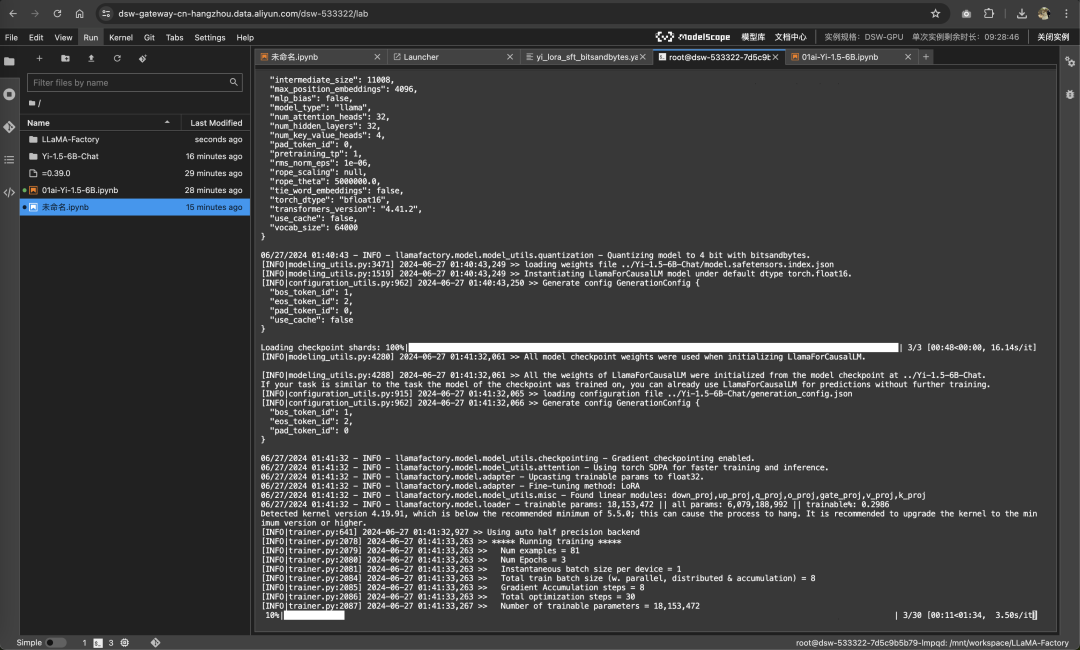
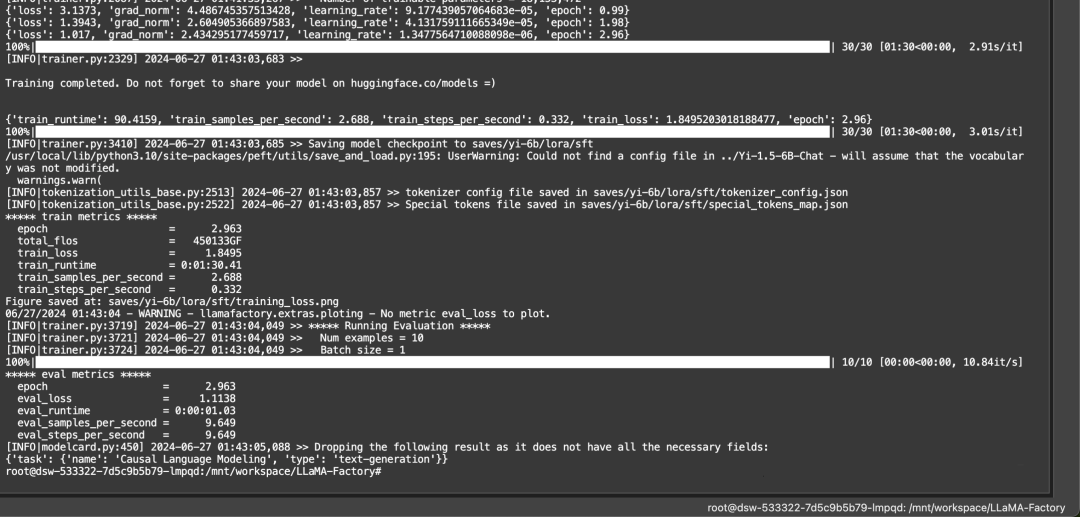
看到进度条就是开始微调了。
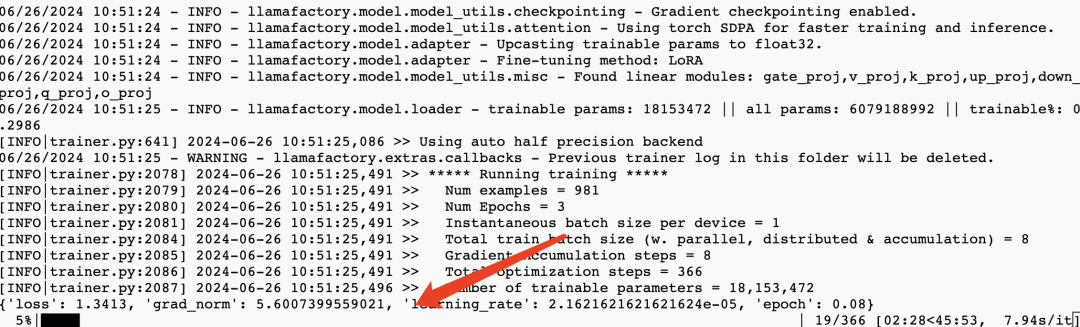
运行过程大概10分钟,看到下面这个界面时,微调过程就结束了。
5. 推理测试
微调后的模型有何不同?在此加载微调模型推理,测试微调前后变化。
参考Llama-Factory文件夹中,examples\inference下提供的llama3_lora_sft.yaml,复制一份,并重命名为 yi_lora_sft.yaml
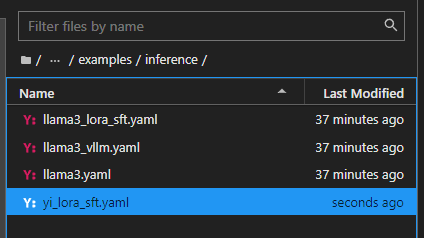
将内容更改为,并且保存_(一定记得保存)_。

回到刚刚结束微调的终端Terminal,运行下面的推理命令(同样在Llama-Factory目录下运行)。
llamafactory-cli chat examples/inference/yi_lora_sft.yaml
稍等模型加载后即可聊天。模型自我身份认知已成功更改,符合数据集规定且保持通用对话能力。与未微调前有何差别?重复步骤,复制llama3.yaml重命名为yi.yaml,改内容后保存(务必)。
model_name_or_path: ../Yi-1.5-6B-Chat
template: chatml
回到终端Terminal,运行下面的推理命令:
llamafactory-cli chat examples/inference/yi.yaml
可以提问和刚才同样的问题,看到模型的原始回答。

基于本实验完成简单微调,走了一遍模型微调过程,挺简单吧?
如何学习大模型AI ?
新岗位生产效率优于被取代岗位,社会整体生产效率提升。
但对个人而言:“最先掌握AI的人比晚掌握的人有竞争优势”。
这话在计算机、互联网、移动互联网开局时同理。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)