
大模型相关知识
检索:知识库和用户提问向量化后的相似性检索增强:检索到的最相关的内容作为context和用户提问结合生成的提示词构成增强效果生成:提示词模板作为大模型新的提示词输入输出结果返回用户。
1.RAG
检索:知识库和用户提问向量化后的相似性检索
增强:检索到的最相关的内容作为context和用户提问结合生成的提示词构成增强效果
生成:提示词模板作为大模型新的提示词输入输出结果返回用户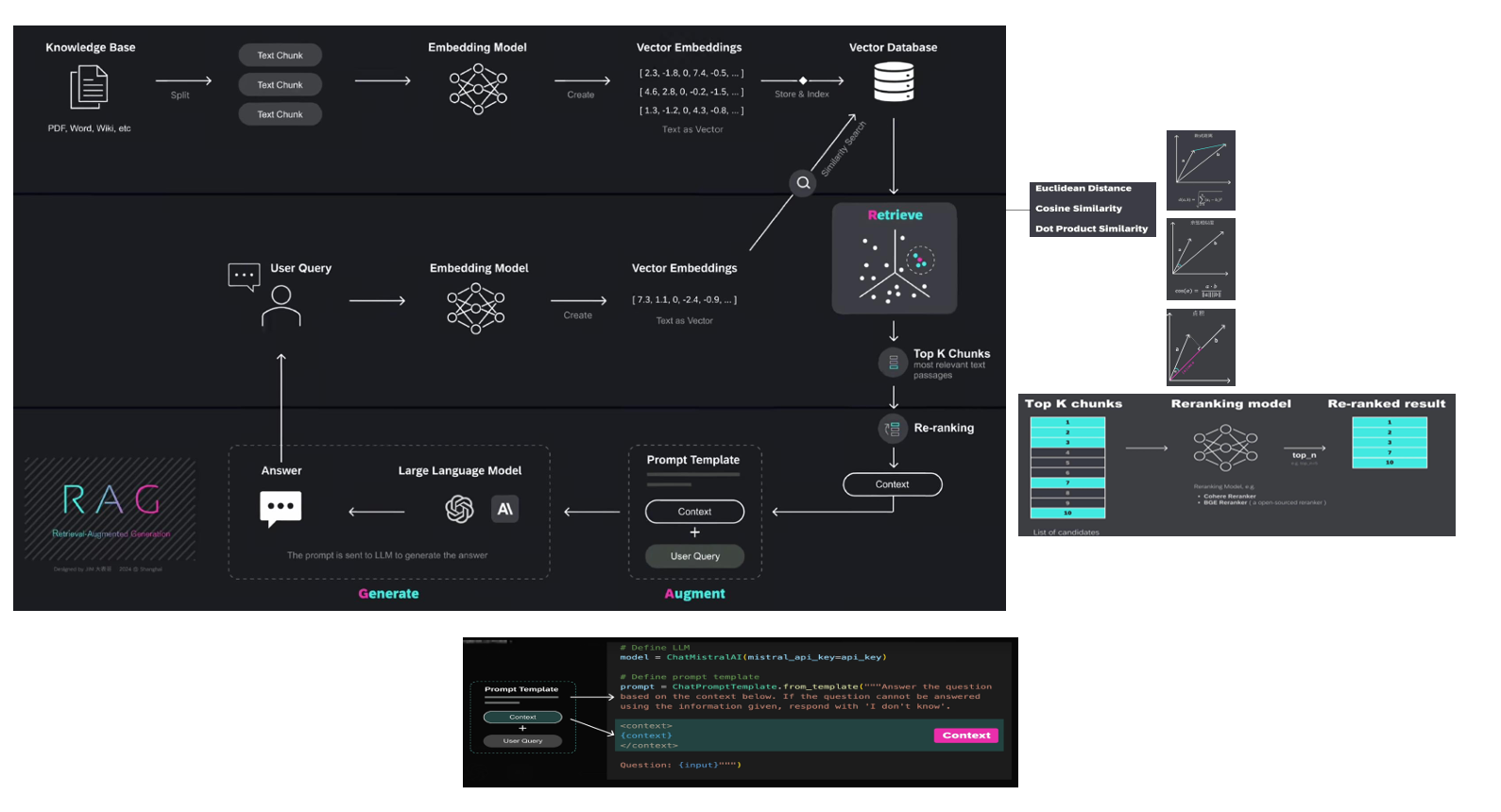
(1)为什么要做RAG
(2)一款强大的 Embedding Model —— BAAI/bge-m3

1 BGE-M3 的 “M3” 代表了它的三个核心特性

2 优势和适用场景

(2)优化环节提高准确率
一般情况:暴力搜索,ANN
1 向量检索 VS 关键词搜索 (各有所长)
- 语义搜索而非关键词精确搜索适用于文本语义搜索场景,能够相对准确的捕捉到用户意图,提高搜索的相关性和准确性
- 但是某些场景下也需要精确匹配:缩写、产品名、特定名称、员工ID、专业词汇等等

2 将两者强强联合:混合搜索 Hybrid Search
并行执行,对双路检索结果进行融合排序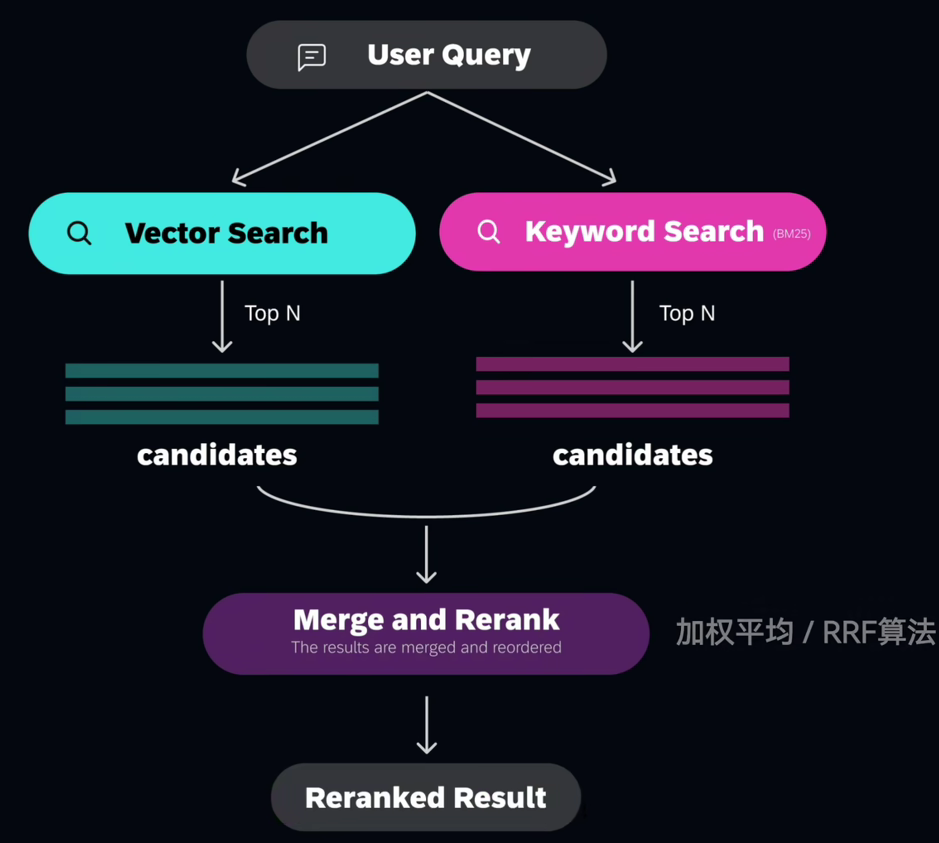
2.向量数据库 Faiss (Facebook Al Similarity Search)

详细学习链接
https://github.com/facebookresearch/faiss
更快的索引
向量搜索算法是“目标”,而FAISS是实现这一目标的“引擎”或“工具”
IndexFlat 索引是一种基于线性搜索的索引,它通过逐个计算与每个向量的相似度来进行搜索。在数据量较大的时候,搜索效率会较低。此时,我们可以使用 IndexIVFFlat 索引来提升搜索效率。它的原理如下:对于所有的向量进行聚类,相当于把所有的数据进行分类。当进行查询时,在最相似的 N 个簇中进行线性搜索。这就减少了需要进行相似度计算的数据量,从而提升搜索效率。
需要注意:这种方法是一种在查询的精度和效率之间平衡的方法。
更少的内存
索引类型为了实现向量搜索,都需要将向量存储到 Faiss 中,当向量的数量较多时就会占用更多的内存。 这也影响了 Faiss 的应用。所以,为了减少内存的占用,我们就需要对存储的向量进行重新编码、压缩,使其占用更少的内存,从而能够容纳更多的向量。量化技术可以使用较低精度的表示来近似向量数据,从而降低内存需求而又不牺牲准确性。 这对于大规模向量相似性搜索应用程序特别有用。
GPU 计算
传统 CPU 计算在处理大规模向量数据时往往效率低下,而 GPU 具有并行计算能力强、吞吐量高、延迟低等优势,可以显著提高向量相似度搜索的速度。在 Faiss 官方提供的基准测试中,使用 GPU 计算的 Faiss 可以将向量相似度搜索的速度提高数十倍甚至数百倍。
示例
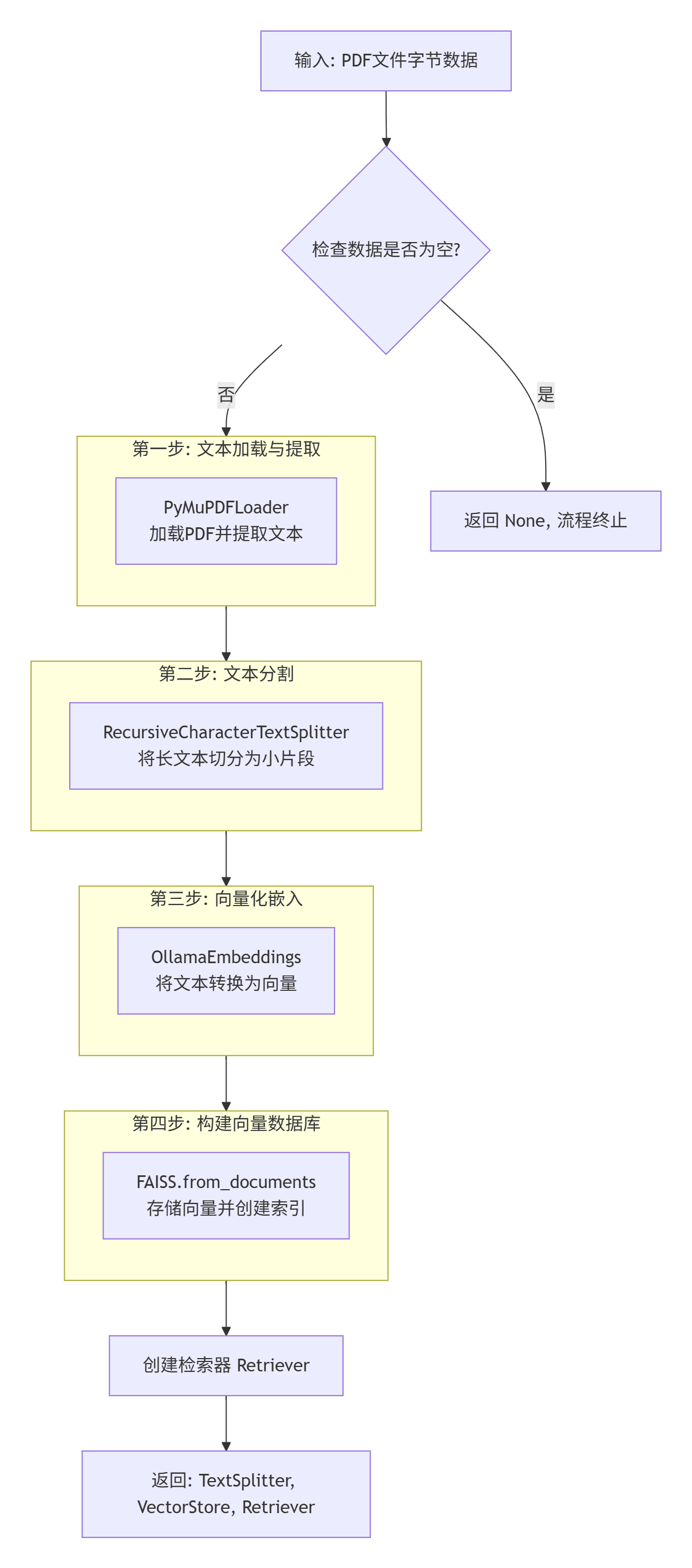
def process_pdf(pdf_bytes):
"""
Args:
pdf_bytes: PDF文件的路径
Returns:
tuple: 文本分割器、向量存储和检索器
"""
if pdf_bytes is None:
return None, None, None
# 加载PDF文件
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
# 创建文本分割器,设置块大小为500,重叠为100
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
# 使用Ollama的deepseek-r1模型创建嵌入
embeddings = OllamaEmbeddings(model="deepseek-r1:1.5b")
# 将Chroma替换为FAISS向量存储
vectorstore = FAISS.from_documents(documents=chunks, embedding=embeddings)
# 从向量存储中创建检索器
retriever = vectorstore.as_retriever()
# 返回文本分割器、向量存储和检索器
return text_splitter, vectorstore, retriever
3.模型微调 Fine-tuning
| 方法类别 | 代表方法 | 核心思想 | 优点 | 适用场景 |
|---|---|---|---|---|
| 全量微调 (Full Fine-tuning) | 经典微调 | 更新预训练模型的所有权重参数 | 潜力挖掘充分,任务表现可能最佳 | 数据量充足(百万级)、计算资源极其丰富、任务与预训练差异大 |
| 参数高效微调 (PEFT) | LoRA | 冻结原模型权重,仅训练注入的低秩矩阵 | 显著节省显存和计算资源,训练快,多任务切换方便 | 最主流和推荐的PEFT方法之一,尤其适合资源受限、快速迭代 |
| Prefix Tuning / P-Tuning | 在输入前添加可学习的“前缀”或“提示”向量,冻结模型主体 | 不改动模型结构,任务切换灵活 | 任务多变但对语义质量要求高的场景 | |
| Adapter | 在模型层间插入小型神经网络模块,仅训练这些模块 | 参数效率高,支持多任务/多语言快速切换 | 需要同时适配多个任务或语言的场景 | |
| QLoRA | LoRA与量化技术结合,将模型权重压缩至4-bit后再应用LoRA | 极致降低显存消耗,单卡即可微调超大模型 | 显存极度紧张,需要在消费级显卡上微调大模型 |
(1)为什么做微调
一言以蔽之:”减少幻觉“
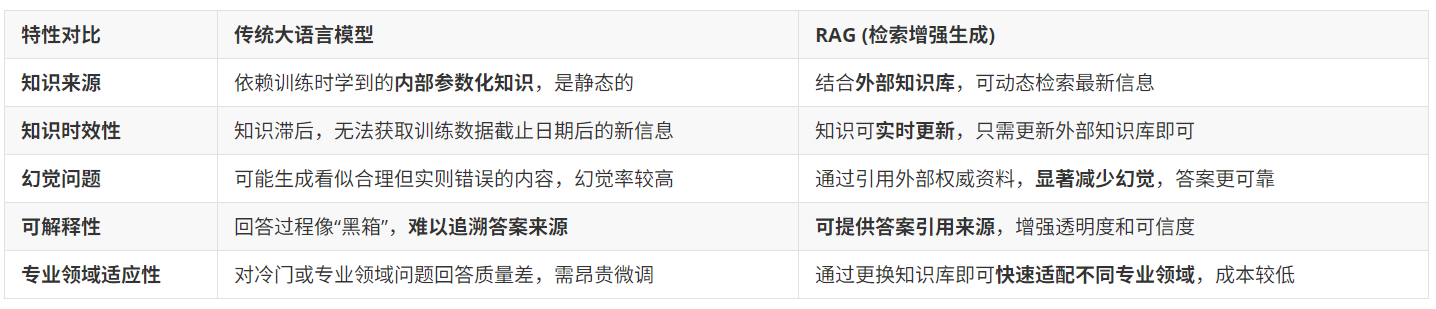
(2)和 RAG 的区别
-
微调:是“修炼内功”。它改变模型本身,让模型学会特定的“语感”和思维方式,擅长处理需要深层理解和推理的复杂问题。
-
RAG:是“查阅手册”。它不改变模型,而是在回答问题前,先从外部知识库中检索最相关的信息作为参考,让模型基于这些准确信息作答。这非常适合处理需要精确事实和最新信息的问题
微调与RAG协同工作:模型专业化+知识实时化
(3)步骤和微调思路
1.选择一个合适的预训练模型;预训练模型通过海量通用数据掌握了语言理解、知识推理等基础能力,而微调则使其适应具体应用场景。
2.准备数据:数据质量往往比数量更重要
3.选择微调方法并配置:
- 框架选择建议
数据规模 < 10万条 → PEFT+Transformers 。 10万-100万条 → DeepSpeed+部分微调。100万条+ → 全量微调+多机分布式
4.进行训练:使用选定的框架(如Hugging Face Transformers + PEFT库)启动训练过程
示例:使用Hugging Face Transformers库对BERT模型进行微调
from transformers import BertForSequenceClassification, Trainer, TrainingArguments
# 加载预训练模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 冻结除最后一层之外的参数
for param in model.parameters():
param.requires_grad = False
# 更新最后一层参数
model.classifier = nn.Linear(model.config.hidden_size, num_classes)
# 准备数据
train_dataloader, val_dataloader = get_data_loaders()
# 定义训练参数
training_args = TrainingArguments(...)
# 创建Trainer并开始微调
trainer = Trainer(model=model, args=training_args, train_dataset=train_dataloader, eval_dataset=val_dataloader)
trainer.train()
(4)微调效果评估:定量指标和+定性分析+对比测试

仅看损失是不够的,我们需要用更贴近下游任务的指标来评估模型生成内容的质量。对于法律AI助手这类文本生成任务,常用的自动化指标包括BLEU和ROUGE。
- BLEU:分数越高,表示模型生成的文本与参考文本在词法和短语匹配上越精确。但BLEU更偏向精确性,有时会忽略语义一致性。
- ROUGE(特别是ROUGE-L):分数越高,表示模型捕获了参考文本中更多的关键信息单元和句子级逻辑。对于法律条文查询这类注重事实准确性和关键信息召回的任务,ROUGE-L通常比BLEU更有参考价值

在训练过程中和结束后,使用一个独立的验证集来评估模型性能,防止过拟合,并根据评估结果调整超参数
(5)注意事项
- 如何选择微调方法:对于大多数开发者和中小企业而言,参数高效微调(PEFT)是更实际的选择。其中,LoRA在效果、效率和易用性上取得了很好的平衡,是许多场景下的首选。如果你的显存资源特别紧张,QLoRA能让你在单张显卡上微调原来无法触及的大模型
- 警惕“灾难性遗忘”:全量微调的一个风险是,模型可能会过度适应新数据,而忘记在预训练时学到的通用知识。PEFT方法由于大部分模型参数被冻结,能更好地缓解这一问题
(6)LoRA 的工作原理:低秩适应的奥秘
LoRA能做到“四两拨千斤”,其核心在于一个巧妙的低秩假设:模型在适应新任务时,其权重矩阵的更新(ΔW)其实具有低秩特性(即可以被分解为两个更小矩阵的乘积)。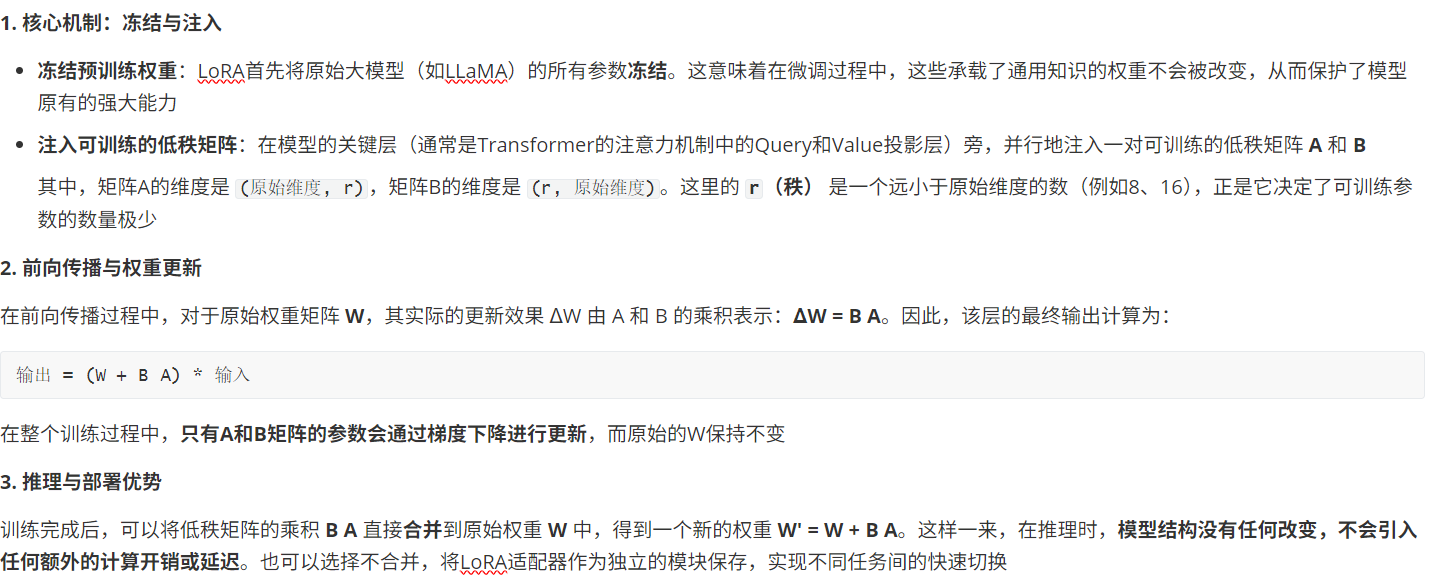
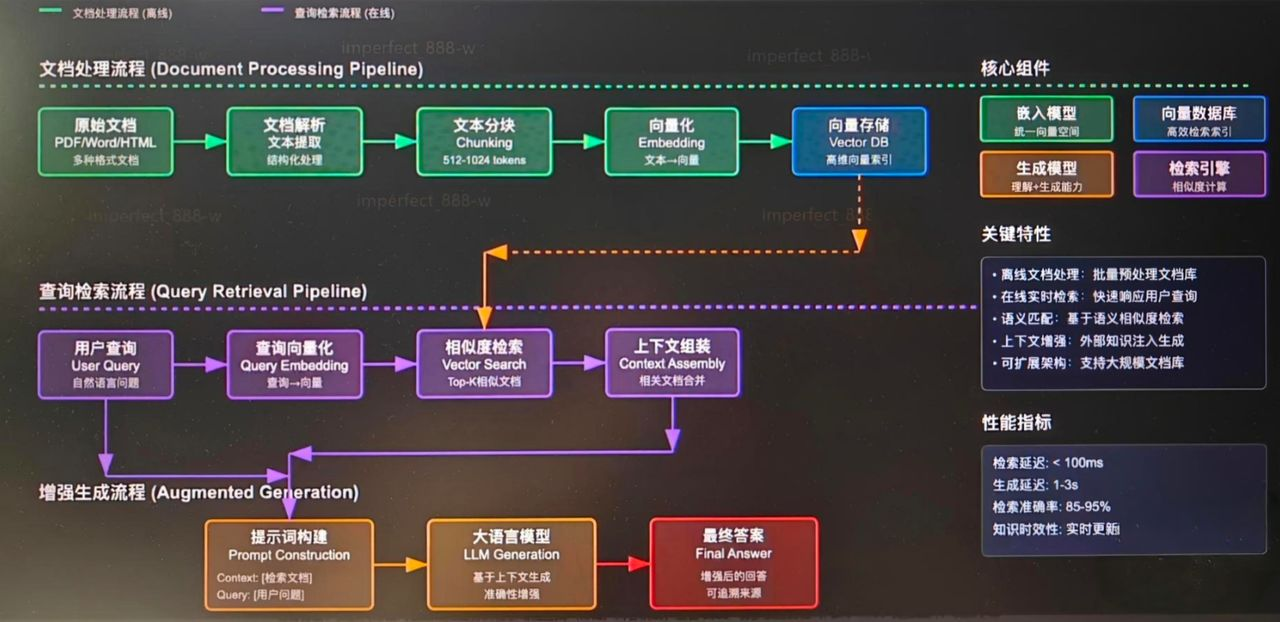
4.Langchain框架 —— LLM 应用开发框架
LangChain 是 LLM 功能开发的「积木工厂」,不是简单框架,而是模型增强器 + 应用组装工具箱
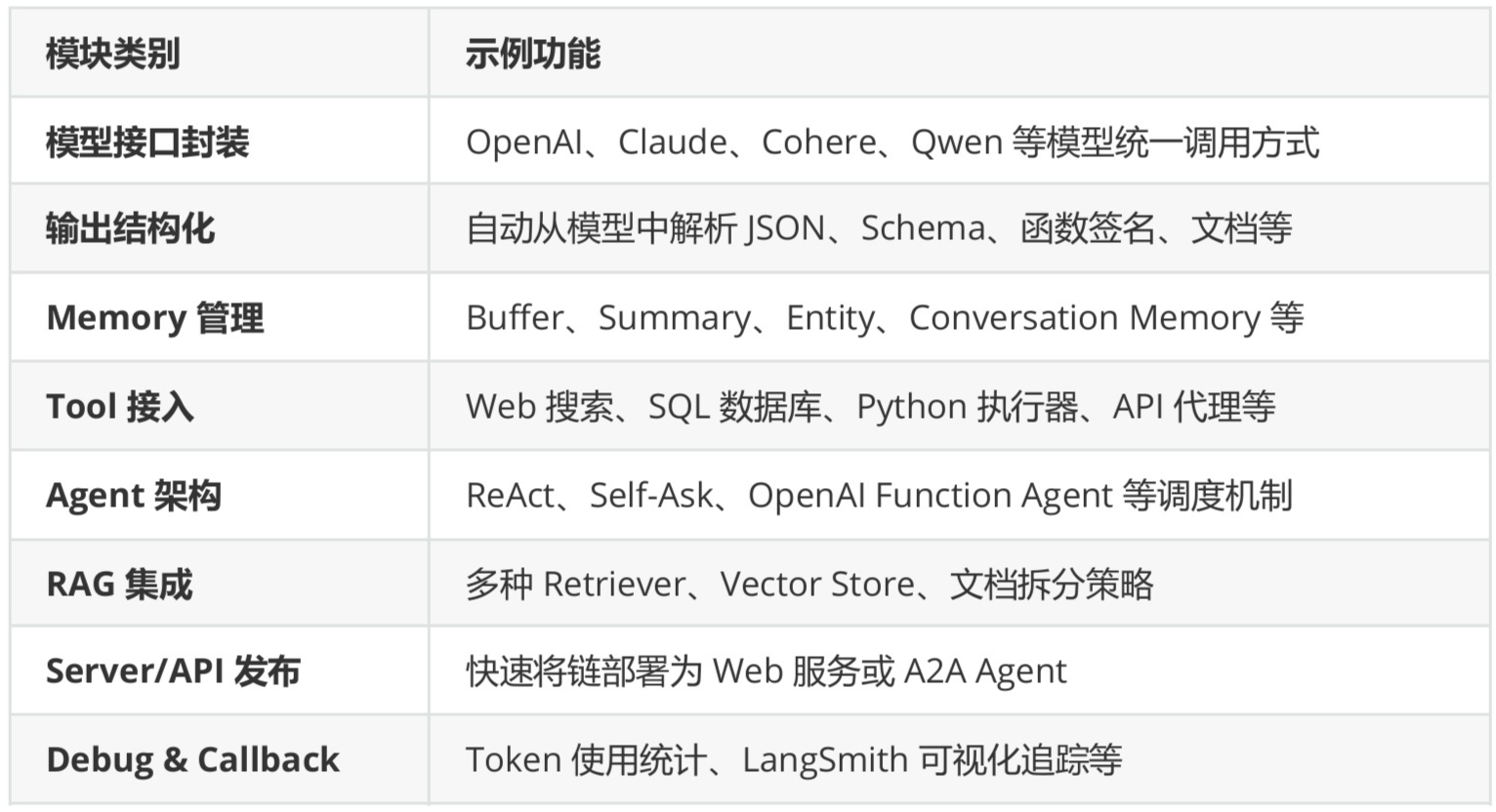
(1)模块及功能
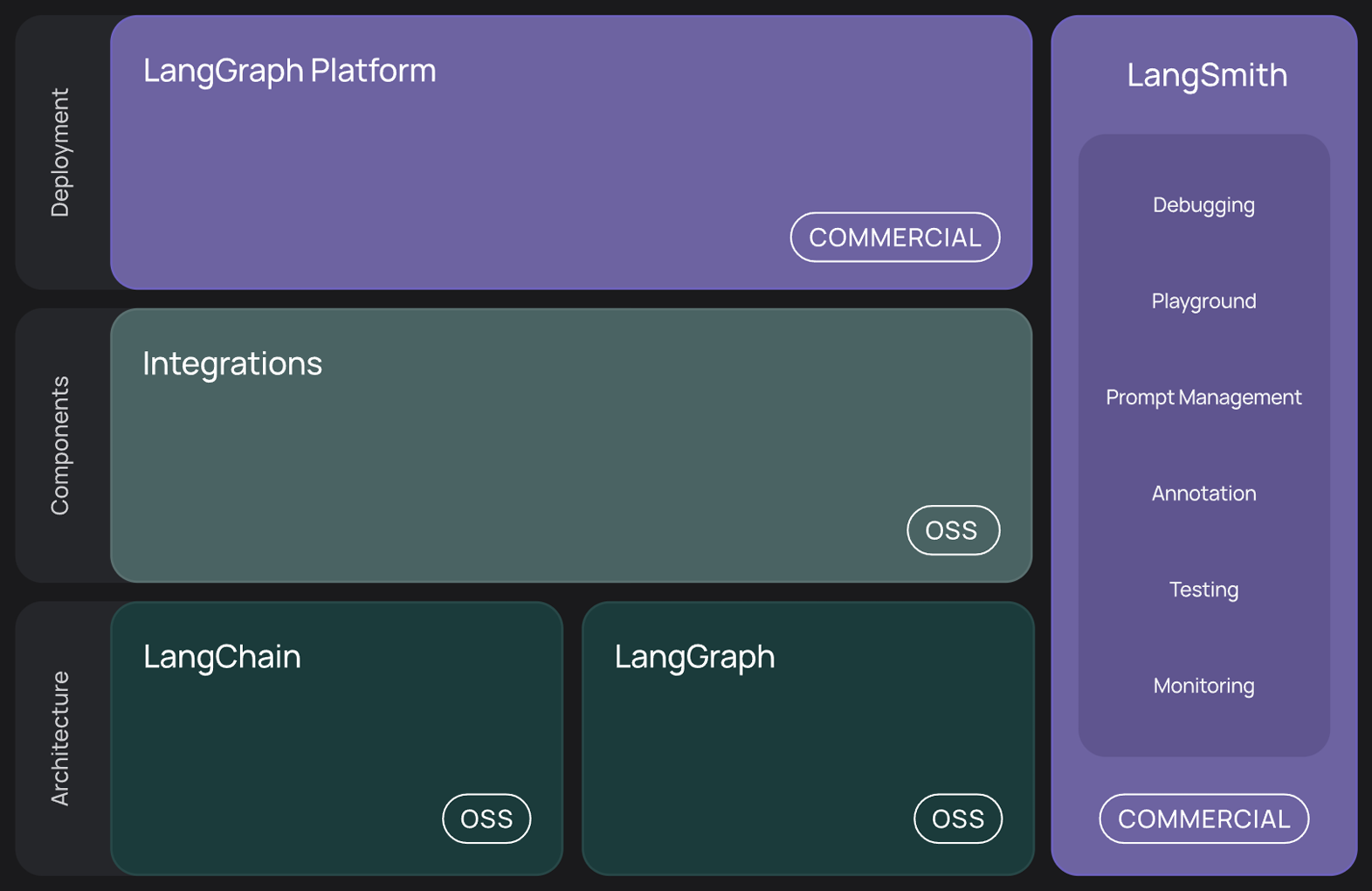
(2)目前的工具生态
(3)基于 Langchain 的法律小助手实现
(1)流程图
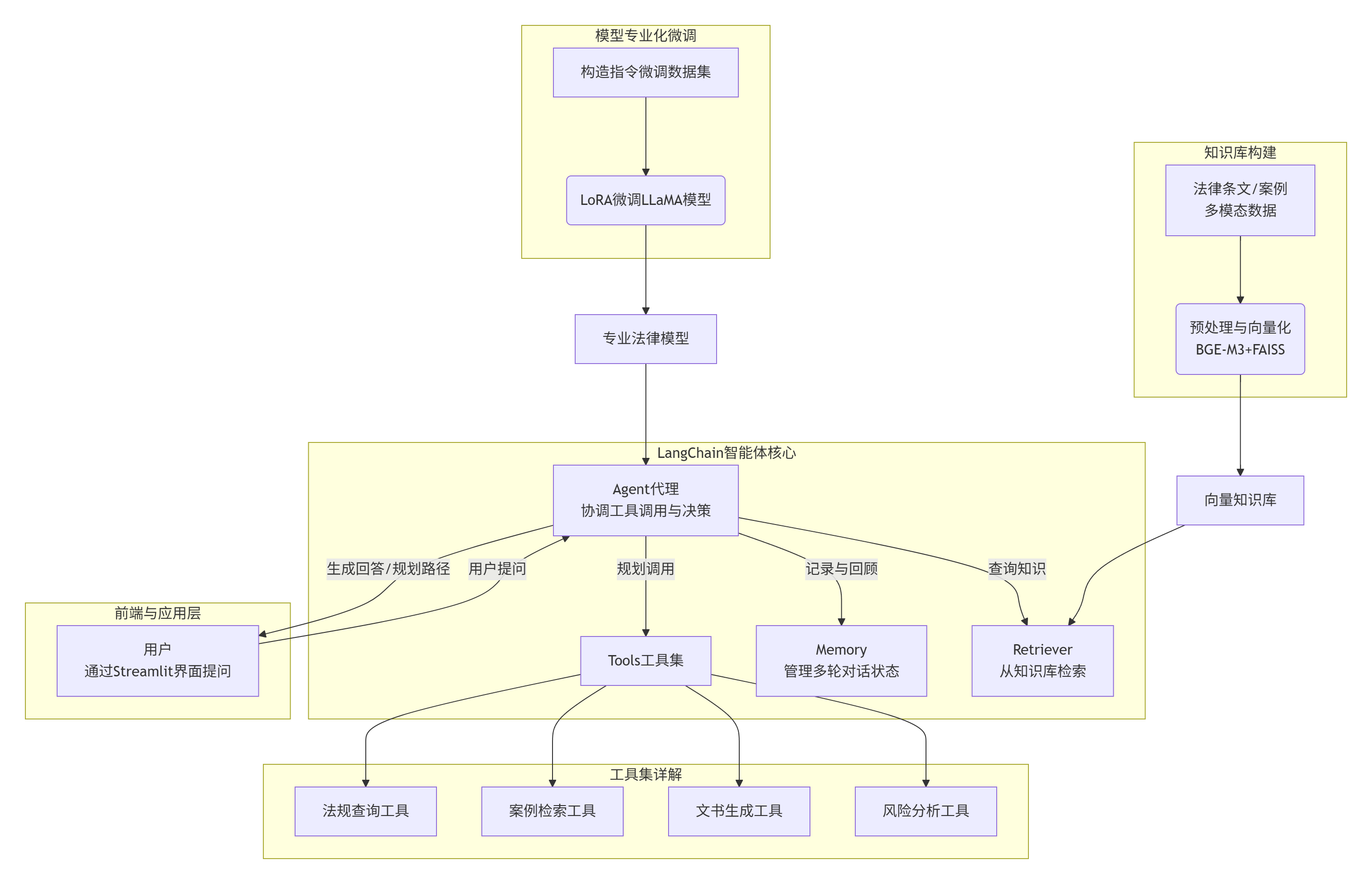
(2)期望功能实现:
- 劳动法条款智能查询:
实现:用户问“试用期最长是多久?”。LangChain会调用RAG流程:首先使用BGE-M3等模型将问题向量化,在FAISS向量数据库中检索最相关的《劳动合同法》条文,然后让微调后的模型生成简洁、准确的答案。
优势:结合了关键词匹配和语义理解,查询结果更精准。 - 案例分析:
实现:用户描述一个案例“员工旷工被直接开除是否合法?”。LangChain会检索类似的历史判决案例,并引导微调模型从案件事实、法律适用、判决结果等维度进行对比分析,给出专业判断。
优势:微调模型对法律语义的深度理解,使其能进行更专业的案例剖析。 - 法律文书生成:
实现:通过Prompt 引导用户输入关键信息(如当事人、事实经过、诉求),然后LangChain将这些信息结构化,并调用微调模型填充到预设的法律文书模板中,自动生成初稿。
优势:模型熟悉法律文书的规范用语和格式,生成的文书专业度高。 - 风险自检:
实现:设计一个多轮对话流程。LangChain会引导用户回答一系列问题(如“公司是否与您签订劳动合同?”“是否足额缴纳社保?”),根据答案检索相关法律风险点,最后由模型生成一份个性化的风险报告和改进建议。
优势:将复杂的法律知识转化为交互式问答,用户体验友好。
(3)数据集准备
# 示例劳动法条文数据 (包含PDF、DOCX等文件读取)
legal_provisions = [
{
"id": "LABOR_LAW_001",
"title": "关于试用期的规定",
"content": "劳动合同期限三个月以上不满一年的,试用期不得超过一个月;劳动合同期限一年以上不满三年的,试用期不得超过二个月;三年以上固定期限和无固定期限的劳动合同,试用期不得超过六个月。",
"type": "法条",
"source": "《劳动合同法》第十九条"
},
{
"id": "LABOR_LAW_002",
"title": "关于经济补偿的规定",
"content": "劳动者月工资高于用人单位所在直辖市、设区的市级人民政府公布的本地区上年度职工月平均工资三倍的,向其支付经济补偿的标准按职工月平均工资三倍的数额支付,向其支付经济补偿的年限最高不超过十二年。",
"type": "法条",
"source": "《劳动合同法》第四十七条"
},
]
# 示例劳动争议案例数据
legal_cases = [
{
"id": "CASE_001",
"title": "张某因试用期超期诉某科技公司案",
"content": "张某与某科技公司签订了一年期限的劳动合同,合同中约定试用期为三个月。工作两个月后,张某被公司以不符合录用条件为由辞退。张某认为试用期约定违法,要求支付赔偿金。法院最终判决:公司约定的试用期超过法定的二个月,属违法约定。公司需向张某支付违法约定试用期的赔偿金。",
"type": "案例",
"keywords": ["试用期", "辞退", "赔偿金"],
"outcome": "劳动者胜诉"
},
{
"id": "CASE_002",
"title": "李某因绩效不达标被辞退案",
"content": "李某在公司年度绩效考评中被评为不合格。公司依据《员工手册》中'绩效不合格视为严重违反规章制度'的规定,单方解除了与李某的劳动合同。李某辩称公司未对绩效评定标准进行公示,且未提供任何培训或调岗机会,属于违法解除。法院判决:公司的解除程序不合法,构成违法解除劳动合同,应支付赔偿金。",
"type": "案例",
"keywords": ["绩效", "辞退", "规章制度", "违法解除"],
"outcome": "劳动者胜诉"
},
]
# 构造用于微调的指令数据集 (示例)
# 格式: <指令> <输入> <输出>
fine_tuning_data = [
{
"instruction": "请根据《劳动合同法》回答以下问题",
"input": "一年的劳动合同,试用期最长是多久?",
"output": "根据《劳动合同法》第十九条规定,劳动合同期限一年以上不满三年的,试用期不得超过二个月。因此,一年的劳动合同,试用期最长不得超过二个月。"
},
{
"instruction": "请分析以下案例",
"input": "公司因员工绩效不合格直接辞退,是否合法?",
"output": "根据相关案例(如李某案),仅以绩效不合格为由直接辞退员工可能构成违法解除劳动合同。合法的程序应包括:1. 证明绩效评定标准已公示且合理;2. 证明员工确属'不胜任工作';3. 对其进行培训或调岗;4. 培训或调岗后仍不胜任,方可解除并需支付经济补偿。否则,劳动者可主张赔偿金。"
},
# ... 更多数据
]
(4)构建向量知识库
使用BGE-M3模型和FAISS构建RAG的知识库。
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.docstore.document import Document
# 1. 配置嵌入模型
model_name = "BAAI/bge-m3"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# 2. 准备文档 - 将示例数据转换为LangChain的Document对象
documents = []
for provision in legal_provisions:
# 将法条数据拼接成一段文本
text = f"{provision['title']}\n{provision['content']}\n来源: {provision['source']}"
# 创建Document对象,metadata中存储元数据
doc = Document(page_content=text, metadata={"type": provision["type"], "id": provision["id"], "source": provision["source"]})
documents.append(doc)
for case in legal_cases:
text = f"{case['title']}\n{case['content']}"
doc = Document(page_content=text, metadata={"type": case["type"], "id": case["id"], "keywords": ", ".join(case["keywords"]), "outcome": case["outcome"]})
documents.append(doc)
# 3. 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(documents)
# 4. 创建向量库
vector_db = FAISS.from_documents(docs, embeddings)
# 保存向量库
vector_db.save_local("labor_law_faiss_index")
(5)LoRA微调LLaMA模型
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from peft import LoraConfig, get_peft_model, TaskType
from datasets import Dataset
import torch
# 1. 加载基础模型和分词器
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置填充令牌
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True, # 使用QLoRA进行4位量化,极大减少显存消耗
device_map="auto",
torch_dtype=torch.bfloat16
)
# 2. 配置LoRA参数
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8, # LoRA的秩
lora_alpha=32, # LoRA的alpha值
lora_dropout=0.05,
target_modules=["q_proj", "v_proj"] # 针对LLaMA模型的关键模块
)
# 3. 应用PEFT模型包装
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数,确认大部分参数被冻结
# 4. 准备训练数据
def format_instruction(sample):
return f"### Instruction:\n{sample['instruction']}\n\n### Input:\n{sample['input']}\n\n### Response:\n{sample['output']}"
formatted_data = [format_instruction(d) for d in fine_tuning_data]
tokenized_data = tokenizer(formatted_data, truncation=True, padding=True, max_length=512)
dataset = Dataset.from_dict({"text": formatted_data})
tokenized_dataset = dataset.map(lambda x: tokenizer(x["text"], truncation=True, padding=True, max_length=512), batched=True)
# 5. 配置训练参数
training_args = TrainingArguments(
output_dir="./lora-legal-llama",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-5,
num_train_epochs=3,
logging_dir="./logs",
logging_steps=10,
save_strategy="epoch",
report_to="none"
)
# 6. 创建Trainer并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset
)
trainer.train()
trainer.model.save_pretrained("./lora-legal-llama-final")
(6)构建LangChain智能体
from langchain.agents import AgentType, initialize_agent, Tool
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.schema import SystemMessage
from langchain.llms import HuggingFacePipeline
from transformers import pipeline
from knowledge_base import vector_db, embeddings
import warnings
warnings.filterwarnings('ignore')
# 1. 加载微调后的模型
# 首先,加载基础模型
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", device_map="auto", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
# 然后,加载PEFT适配器权重
from peft import PeftModel
fine_tuned_model = PeftModel.from_pretrained(base_model, "./lora-legal-llama-final")
# 创建文本生成管道
text_generation_pipe = pipeline(
"text-generation",
model=fine_tuned_model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=text_generation_pipe)
# 2. 创建工具 (Tools) - 图片中的Tool接入模块
# 工具1: 法条检索工具
def legal_provision_retriever(query):
"""根据问题检索相关劳动法条文"""
relevant_docs = vector_db.similarity_search(query, k=3, filter=dict(type="法条"))
return "\n\n".join([f"来源: {doc.metadata['source']}\n内容: {doc.page_content}" for doc in relevant_docs])
# 工具2: 案例检索工具
def legal_case_retriever(query):
"""根据问题检索相关劳动争议案例"""
relevant_docs = vector_db.similarity_search(query, k=2, filter=dict(type="案例"))
return "\n\n".join([f"案例: {doc.metadata.get('title', 'N/A')}\n结果: {doc.metadata.get('outcome', 'N/A')}\n内容: {doc.page_content}" for doc in relevant_docs])
# 工具3: 风险自检工具
def risk_self_assessment(query):
return "请根据以下维度自检:1. 合同是否签订;2. 工资是否足额发放;3. 社保是否缴纳;4. 加班费是否支付;5. 解除程序是否合法。您具体担心哪方面的风险?"
# 将函数封装成LangChain Tool
tools = [
Tool(
name="法律条文查询",
func=legal_provision_retriever,
description="当需要查询具体的法律条文、规定时使用此工具。输入:关于xxx的法律规定是什么?"
),
Tool(
name="类似案例查询",
func=legal_case_retriever,
description="当需要参考历史上的类似判决案例时使用此工具。输入:有没有关于xxx的案例?"
),
Tool(
name="劳动争议风险自检",
func=risk_self_assessment,
description="当用户想评估自己在劳动纠纷中的风险时使用此工具。输入:帮我看看公司这样做有没有风险?"
)
]
# 3. 创建Memory (图片中的Memory管理模块) - 记录对话历史
memory = ConversationSummaryBufferMemory(
llm=llm,
memory_key="chat_history",
return_messages=True,
max_token_limit=1000
)
# 4. 系统提示词 - 引导AI成为法律助手
system_message = SystemMessage(content="你是一名专业的法律AI助手,专注于劳动法领域。请根据工具查询到的法律条文和案例,为用户提供准确、清晰、严谨的回答。对于复杂问题,应引导用户进行风险自检或建议咨询专业律师。")
# 5. 创建自定义Prompt模板 (图片中的输出结构化模块)
prompt_template = """你是一名专业的劳动法律师助理。请严格根据以下工具检索到的信息来回答问题。
聊天历史:
{chat_history}
请使用以下工具按需检索信息:
{tools}
请严格按以下格式回应:
思考:首先,思考用户问题的核心是什么,需要调用哪个工具。
行动:将调用一个工具,工具输入应仅为关键词。
观察:工具返回的结果。
... (这个思考-行动-观察循环可以重复多次)
最终回答:综合所有信息,用中文给用户一个专业、清晰、有条理的回答,并引用法律来源。如果涉及风险,提示用户进行自检。
用户问题:{input}
{agent_scratchpad}"""
prompt = PromptTemplate.from_template(prompt_template)
# 6. 初始化智能体 (图片中的Agent架构模块)
legal_agent = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, # 使用ReAct推理框架
verbose=True,
memory=memory,
agent_kwargs={
"system_message": system_message,
"prompt": prompt
},
handle_parsing_errors=True # 处理解析错误
)
# 测试智能体
result = legal_agent.run("公司跟我签了一年合同,但试用期定了三个月,这合法吗?如果不合法我该怎么办?")
print(result)
5.评估大模型微调&训练的硬件成本
在 dense 模型架构下,如果是做全量微调,每一步计算都会激活所有参数,此时硬件成本的评估逻辑相对直接常见做法是根据 模型参数规模 x 精度位宽 来粗略估算显存需求,例如一个 70B 参数的 dense 模型,若来用 FP16 进行存储,需要大约 140GB 显存才能完整容纳此外梯度存储还要占用140G,而优化器则需要占用4倍的显存,也就是约560G,这里总共约840G,再考虑激活值存储、显存碎片化以及分布式训练的兄余开销,实际需求往往在 1TB 显存左右。
如果换成参数更小的 dense 模型,一般可以按照近似线性比例来估算显存需求。例如,一个13B 参数的模型,参数是70B模型的1/5左右,整体可能200GB显存以内就能完成全量微调。如果精度降低,比如采用 8bit 或4bit 量化存储,显存占用会近似按照位宽缩减。以70B模型为例,FP16下参数是140GB,如果用8bit存储则需要约 70GB,用 4bit 存储则只有约 35GB。
不过,梯度和优化器通常还是以 FP16 形式保存,因此总体显存缩减幅度有限。最后,如果不是做全量微调,而是采用 LORA 等高效微调方法,显存占用会显著降低因为 LORA只需要在部分矩阵中引入低秩适配器,训练时只更新新增的参数,原始大模型参数保持冻结。例如对 70B 模型应用LORA,实际需要更新的参数量可能只有 1%~2%,因此显存需求往往控制在160G左右。
(1)根据不同类型微调计算
| 任务类型 | 硬件需求 | 成本评估 | 典型配置举例(估算) |
|---|---|---|---|
| 增强生成(推理) | GPU显存 | 显存占用 ≈ 模型参数量 × 精度(字节) - FP16/BF16: 2字节/参数 → 70B模型需 ~140GB+显存 - INT4量化: 0.5字节/参数 → 70B模型需 ~35GB+显存 成本与模型大小和并发数强相关。 | 7B模型推理:RTX 4090 (24GB) 可量化运行。 70B模型推理:需A100 (80GB) 或双卡H100。 |
| 全参数微调 | GPU显存(极高) | 极其昂贵。需存储模型参数、优化器状态、梯度、激活值等。 总显存 ≈ 模型参数量 × 16~20字节 微调70B模型可能需要高达 >1.4TB显存,必须使用多卡并行技术。 | 微调7B模型:至少需要A100 40G * 2。 微调70B模型:需H100 (80G) * 8或更多。 |
| PEFT微调(如LoRA/QLoRA) | GPU显存(大幅降低) | 降低成本的救星。QLoRA可在单卡消费级GPU上微调大模型。 - QLoRA(4-bit):微调7B模型仅需 ~12GB显存。 | 微调7B模型:RTX 3090/4090 (24GB) 即可胜任。 微调13B/34B模型:需要A100 (40G/80G)。 |

(2)内存占用和计算效率之间进行权衡(数值范围、表示精度和计算效率
)
| 格式名称 | 每个参数占用的字节数 | 核心特点与用途 |
|---|---|---|
| FP32 | 4 字节 | 高精度、高范围,传统标准,用于科学计算或部分对精度要求极高的训练任务。 |
| FP16 | 2 字节 | 内存占用减半,计算速度快,但数值范围窄,易出现数值溢出导致训练不稳定。常用于推理。 |
| BF16 | 2 字节 | 内存占用与FP16相同,但拥有与FP32相近的宽广数值范围,能有效防止训练中的数值溢出,已成为大模型训练的首选格式。 |
| INT8 | 1 字节 | 通过量化技术将浮点数转换为8位整数,内存占用进一步减半,主要用于极限推理加速。 |
| INT4 | 0.5 字节 | 将数据压缩到极致,每个参数仅用4位(0.5字节)表示,旨在让大模型能在资源极度受限的设备(如手机)上运行。 |
- FP16/BF16(2字节/参数)
- 它们都属于“半精度浮点数”。一个字节(Byte) 由8个比特(bit)组成。FP16和BF16都使用 16个比特 来表示一个数。 计算:16 bit / 8 = 2Byte。因此,每个参数占用2字节的内存。
区别:虽然总位数相同,但FP16和BF16在指数位和小数位的分配上不同。FP16用更多位数表示小数以求精确,但牺牲了表示范围;BF16则模仿FP32的指数位,牺牲了一些小数精度换来了极大的数值范围,从而保证了训练稳定性
- 它们都属于“半精度浮点数”。一个字节(Byte) 由8个比特(bit)组成。FP16和BF16都使用 16个比特 来表示一个数。 计算:16 bit / 8 = 2Byte。因此,每个参数占用2字节的内存。
- INT4量化(0.5字节/参数)
- “量化”是一种有损压缩技术。它的目标不是精确表示原始数值,而是用一个非常紧凑的格式来近似,从而极大减少存储空间和计算开销。
INT4中的“4”指的是4个比特。 计算:4 bit / 8 = 0.5 Byte。因此,每个参数仅占用0.5字节。
过程:量化过程(以一组权重值 [0.3456, -0.8750, 1.2345]为例)通常包括: - 找到最大值:确定这组数中绝对值的最大者(例如 1.2345)。
- 计算缩放因子:将数值范围映射到INT4能表示的有限区间(如-7到 7)。缩放因子 = 最大值 / 目标范围最大值。 舍入取整:将每个原始值除以缩放因子后,四舍五入到最接近的整数。于是,连续的浮点数就被压缩成了一串紧凑的整数 [2, -5, 7] 。
在需要计算时,再通过一个反量化过程,将这些整数乘回缩放因子,得到近似的原始浮点数值。虽然会损失精度,但对于很多深度学习任务而言,这种损失在可接受的范围内。
- “量化”是一种有损压缩技术。它的目标不是精确表示原始数值,而是用一个非常紧凑的格式来近似,从而极大减少存储空间和计算开销。
大模型相关网站
大模型显存计算器、论文、论坛等等 : https://www.llamafactory.cn/gpu-memory-estimation.html
魔塔社区: https://www.modelscope.cn/models
huggingface:https://huggingface.co/
langchain: https://www.langchain.com/

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)