
一文彻底搞定从0到1手把手教你部署Qwen3大模型
本文提供了在Autodl平台部署Qwen3-8B大模型的详细教程。首先需租用4090GPU服务器,配置Python3.12和CUDA12.4环境。教程包含五个步骤:1)安装Python基础环境;2)通过modelscope下载模型文件;3)安装Transformers和accelerate框架;4)下载项目Demo文件;5)运行Python脚本调用大模型。重点介绍了如何通过终端命令安装依赖库、下载
·
都是自己的操作截图,手把手教学,零基础也20分钟可以部署Qwen3大模型!!!
如果对您有帮助请点个赞,谢谢。
本次使用 Autodl 服务器,租用一张 4090 GPU,配置基础镜像 CUDA 12.4,部署 Qwen3 8B 模型
环境搭建选择本地或者服务器均可,新手尝试可使用 Autodl 平台服务器,相较于阿里云,腾讯云费用较低,缺点是端口开放有限制。
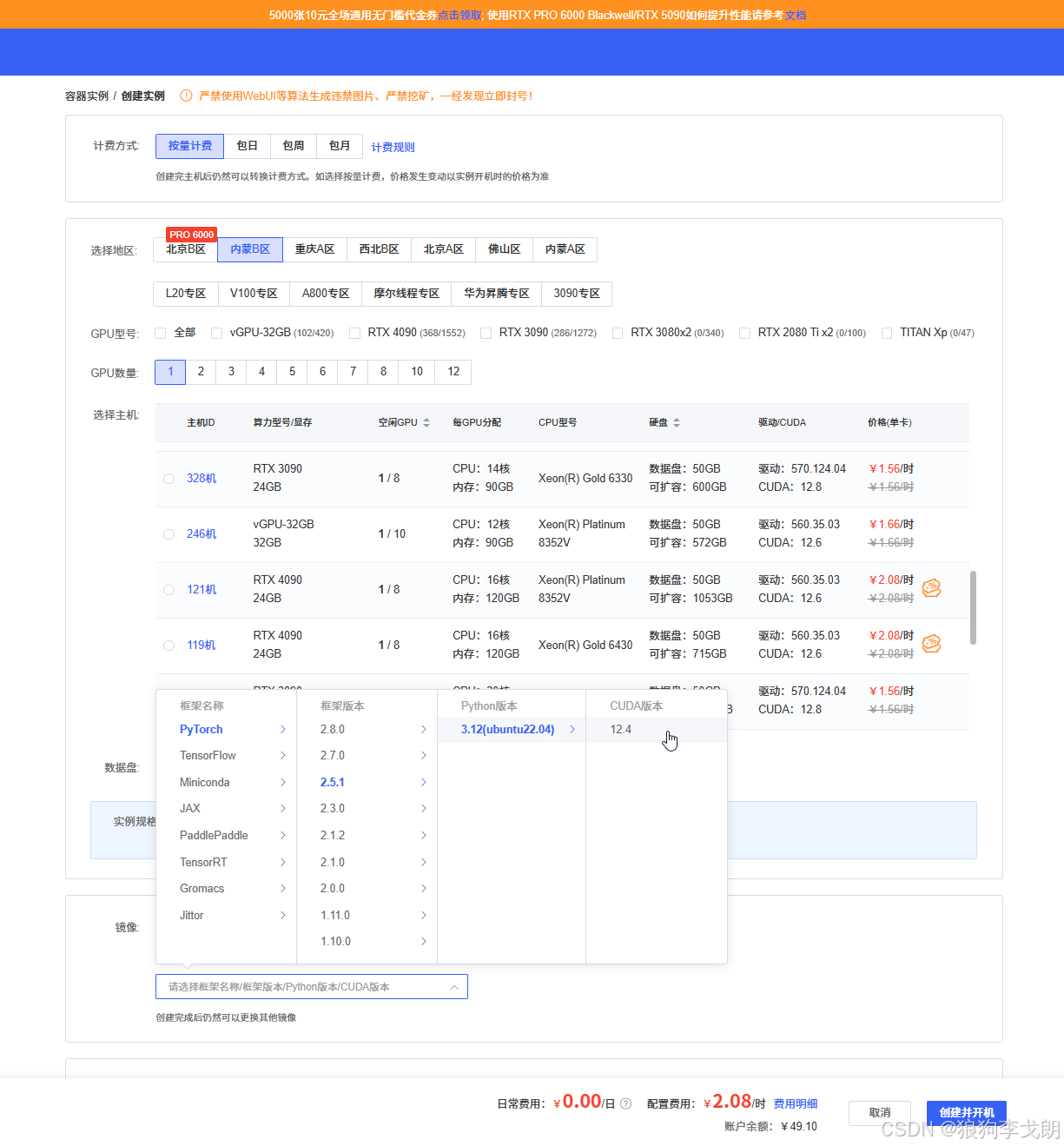
一、Python基础环境
尽量选择版本较新的 Cuda 环境,例如这里使用 PyTorch -> 2.5.1 ->3.12Python ->12.4CUDA ,(4090暂不支持更高版本的CUDA)
二、下载模型文件
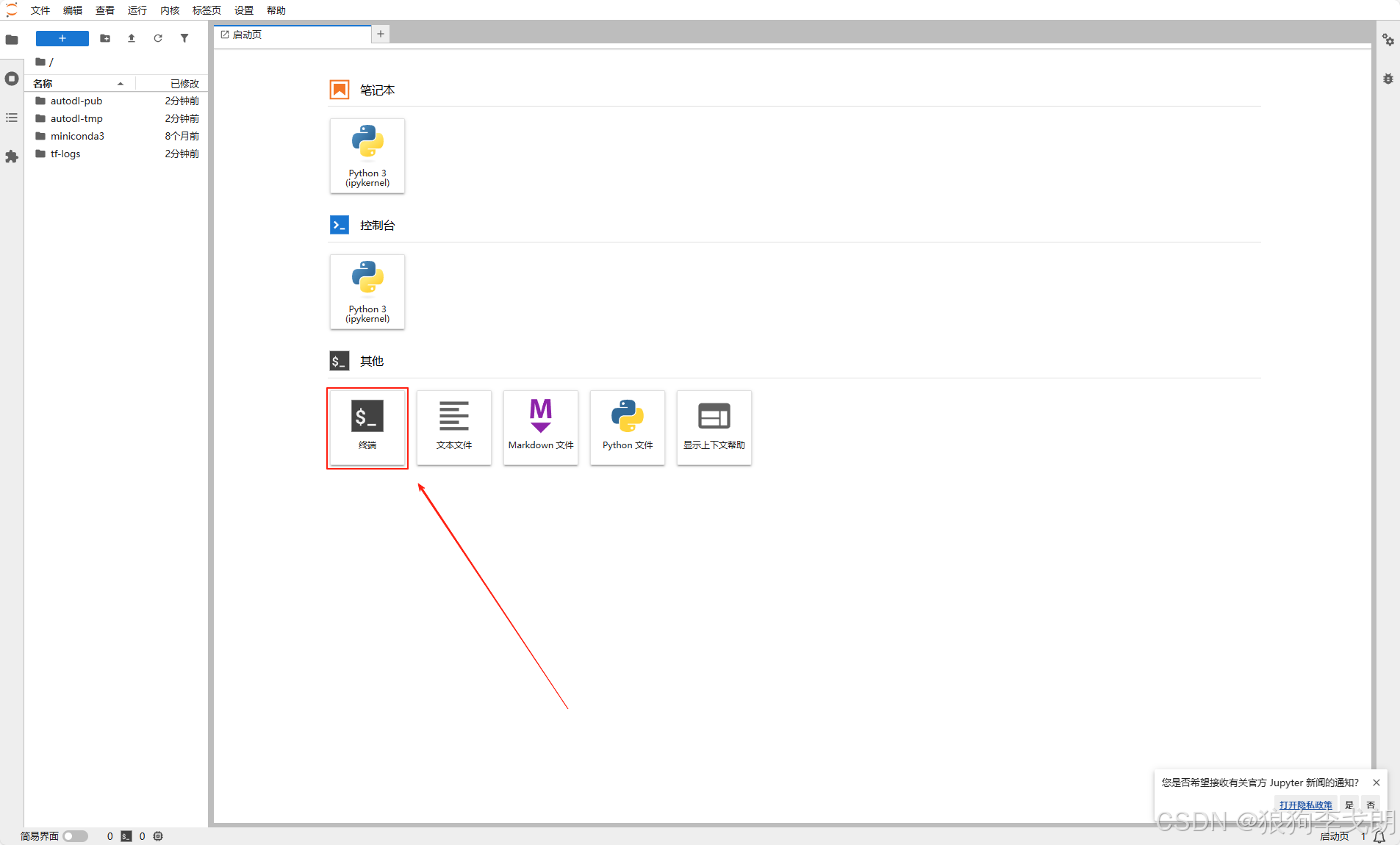
1.点击"JupyterLab"进入控制台界面,点击新建“终端”

2.下载 modelscope 模块
pip install modelscope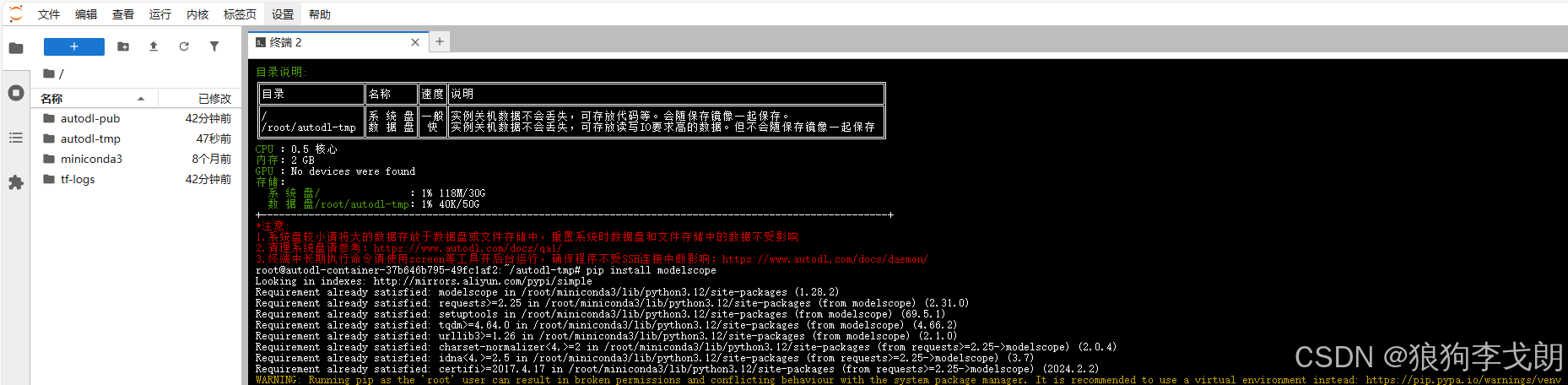
3.下载Qwen3 模型文件
modelscope download --model Qwen/Qwen3-8B --local_dir ./autodl-tmp/Qwen/Qwen3-8B 
三、下载Transformers和accelerrate
1.下载Transformers框架
pip install transformers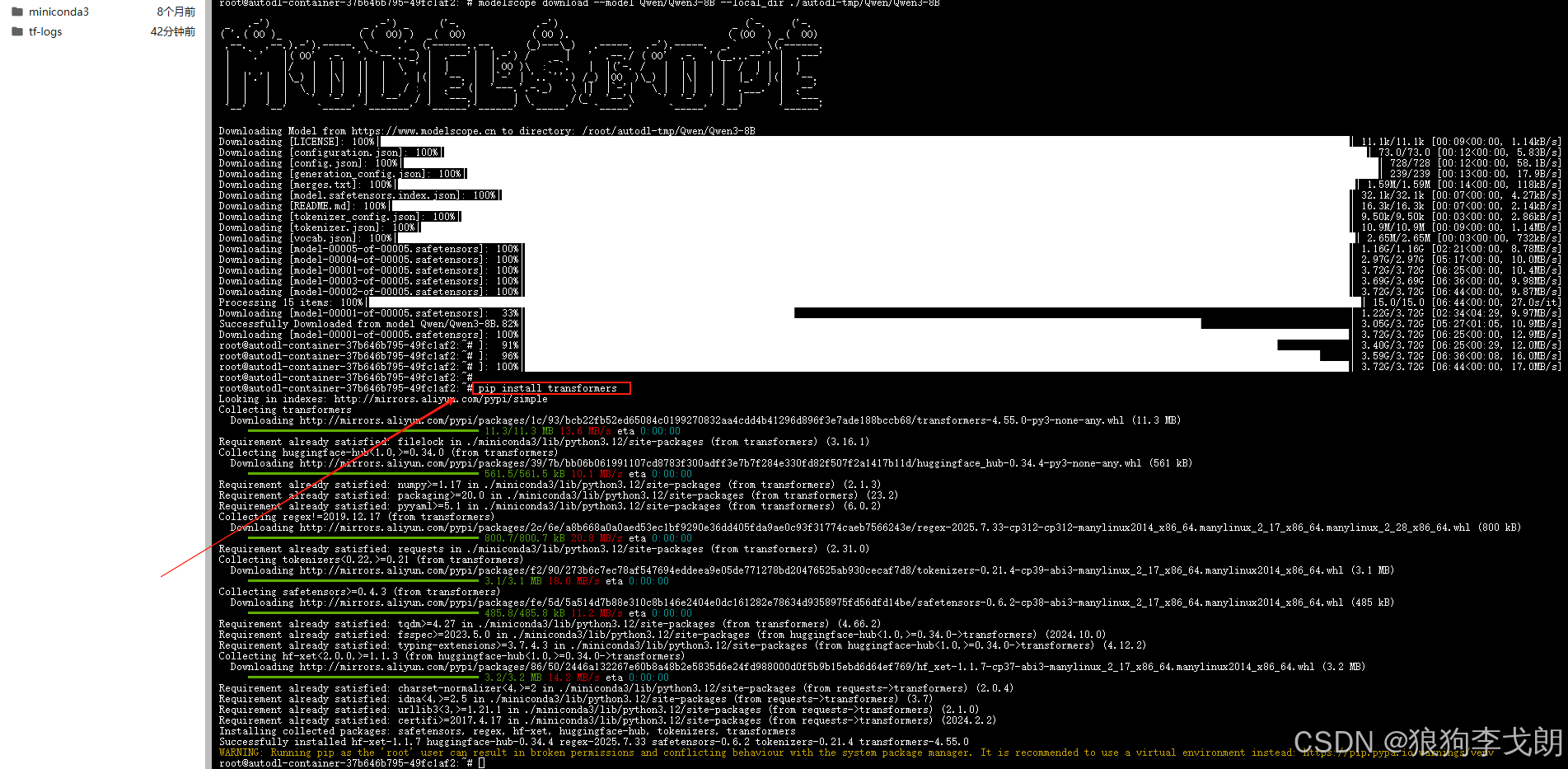
2.下载accelerrate模块
pip install accelerate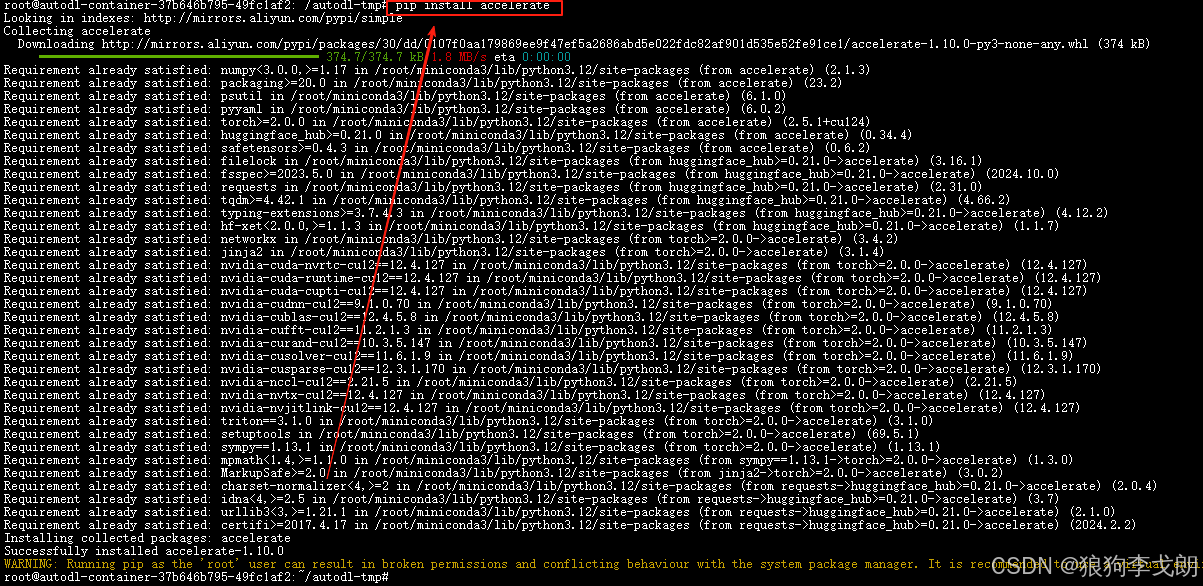
四、下载项目Demo
1.开启学术加速
source /etc/network_turbo![]()
2.下载Git文件
cd autodl-tmp![]()
git clone https://github.com/QwenLM/Qwen3.git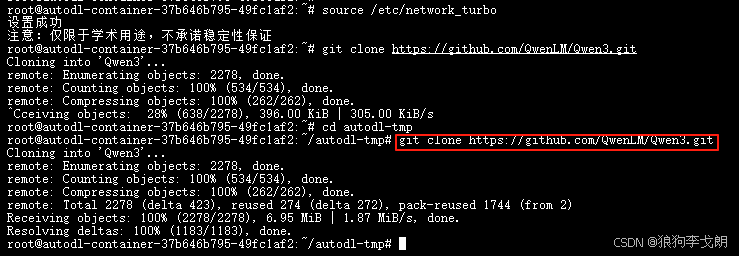
3.关闭学术加速
unset http_proxy && unset https_proxy五、使用大模型
1.进入Qwen3 demo目录(刚刚Git下载的文件)
cd Qwen32.新建Python脚本
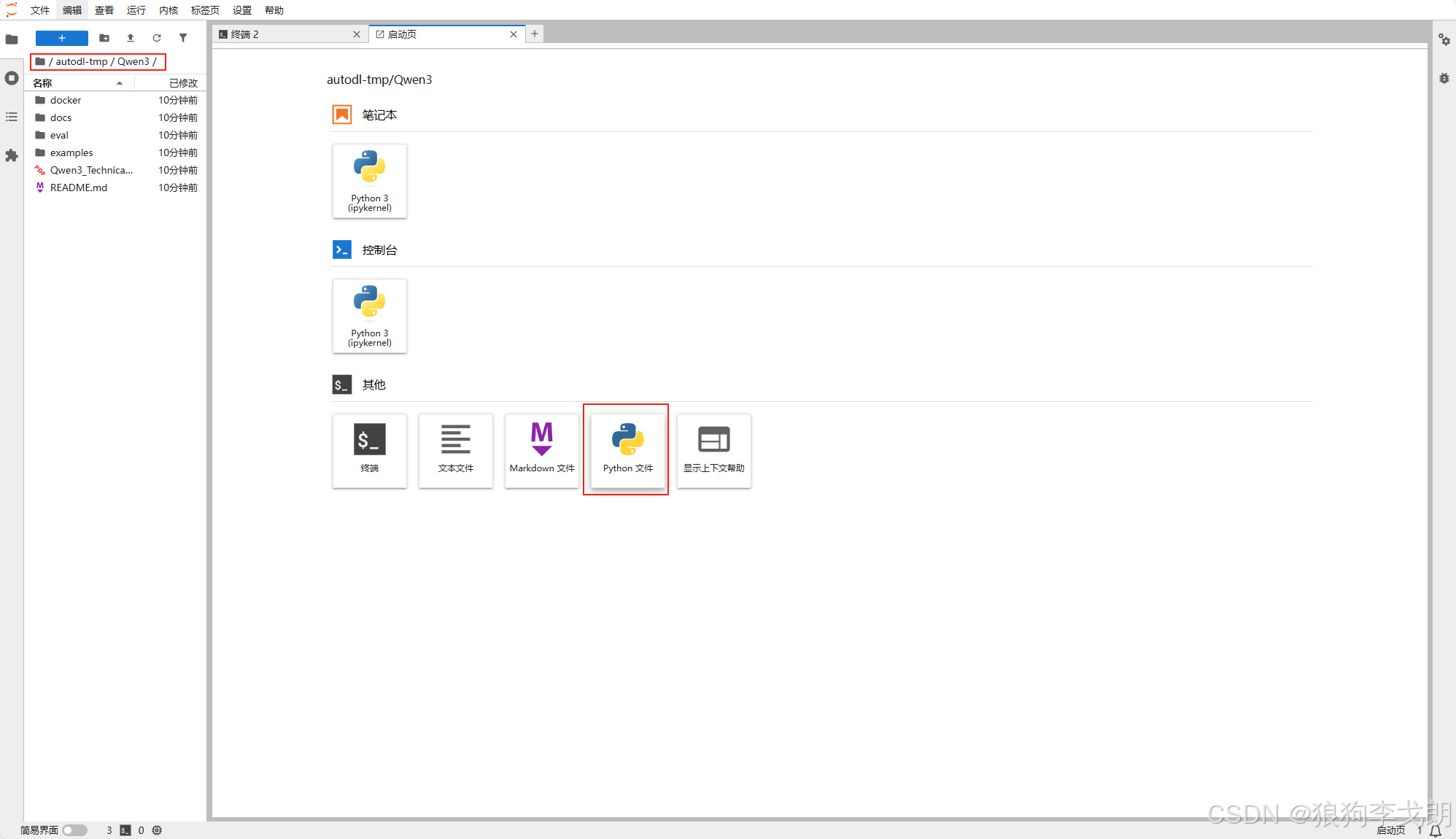
3.复制下面代码到Python脚本
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "/root/autodl-tmp/Qwen/Qwen3-8B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "介绍一下怎么在Autodl平台租用4090显卡部署Qwen3 -8B大模型"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)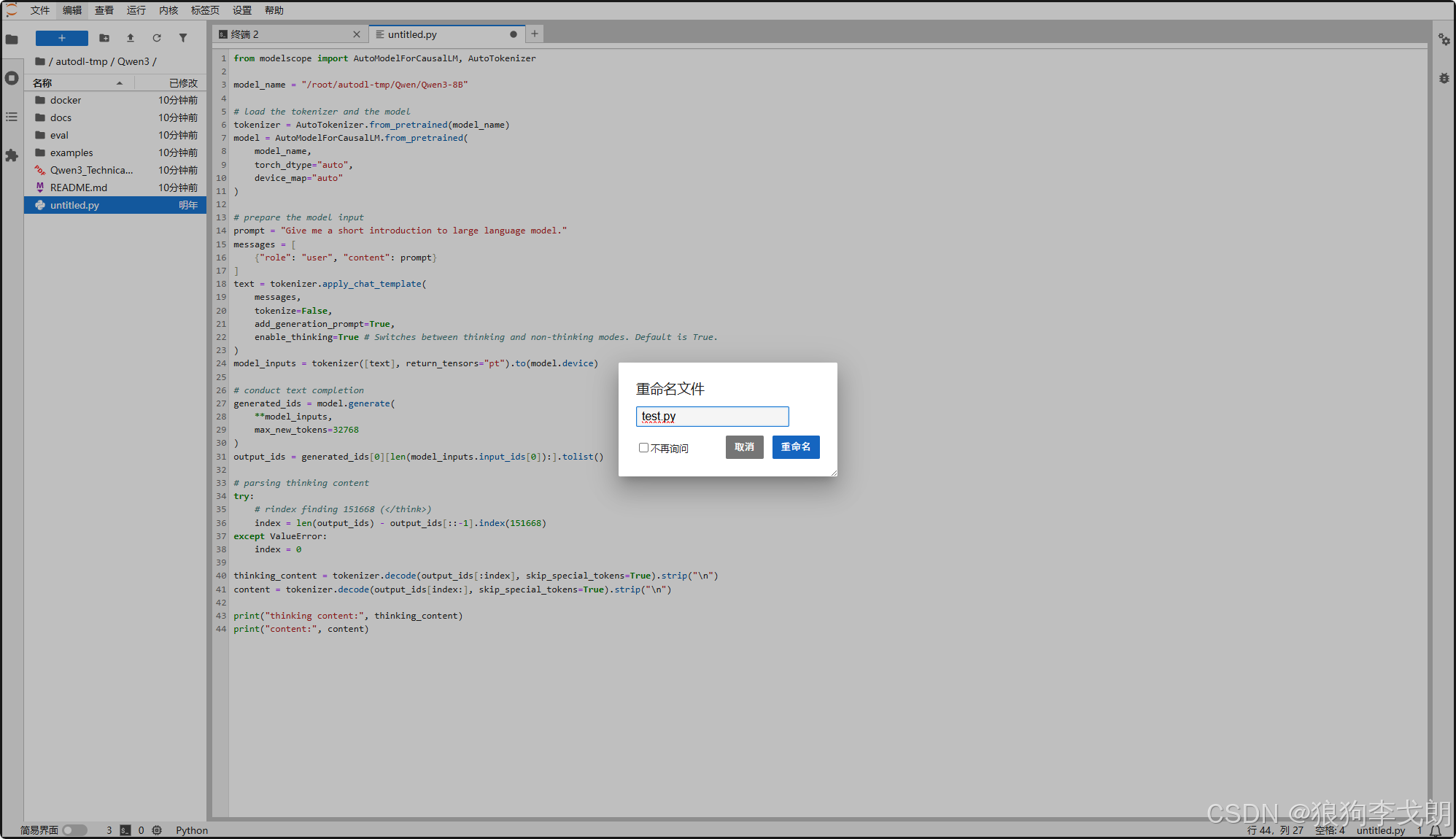
4.运行代码
python test.py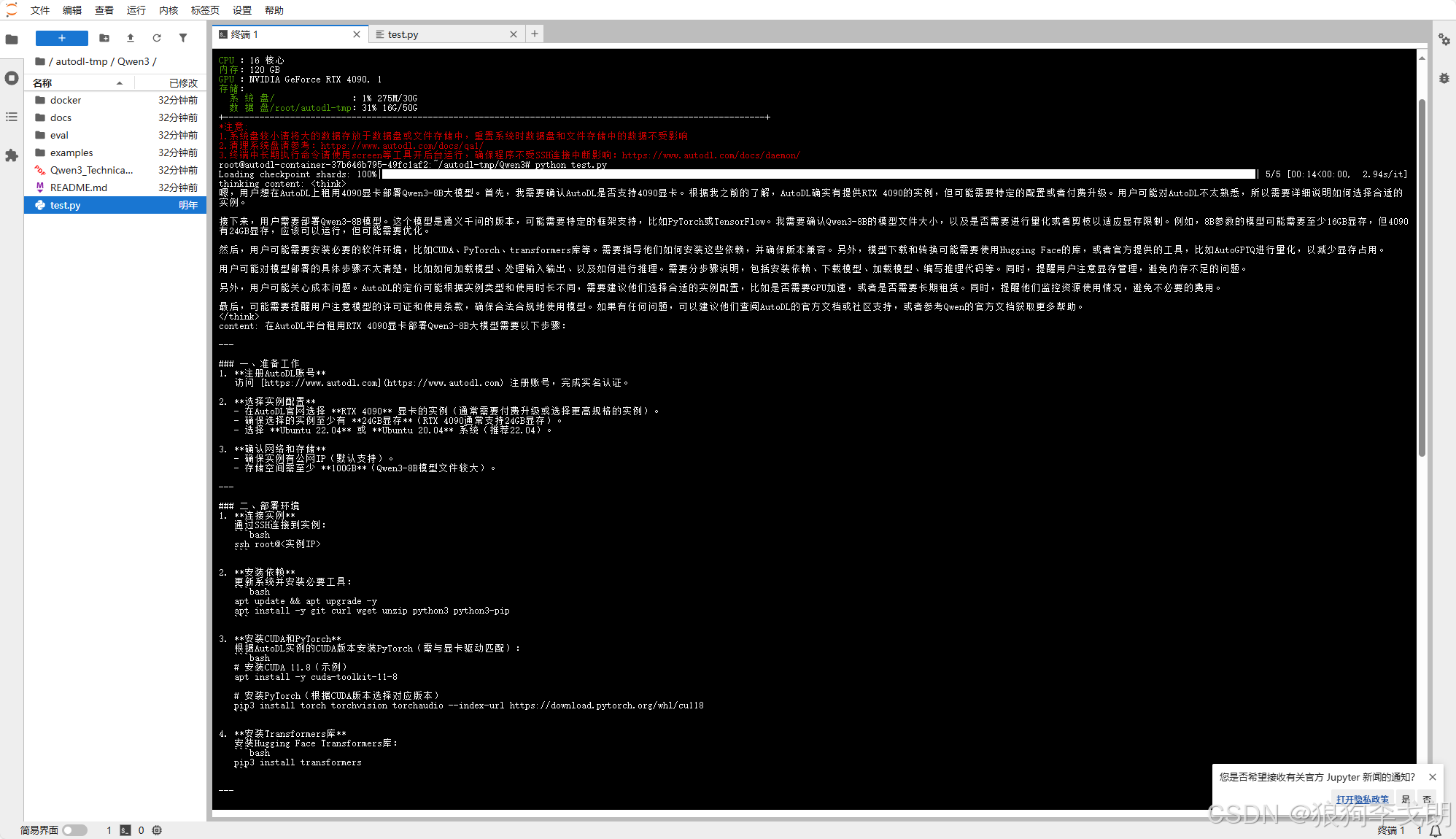
恭喜你成功部署了自己的大模型!!!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)