
快手Keye2.0开源:将DSA注意力引入多模态,开启强化推理新范式
引言
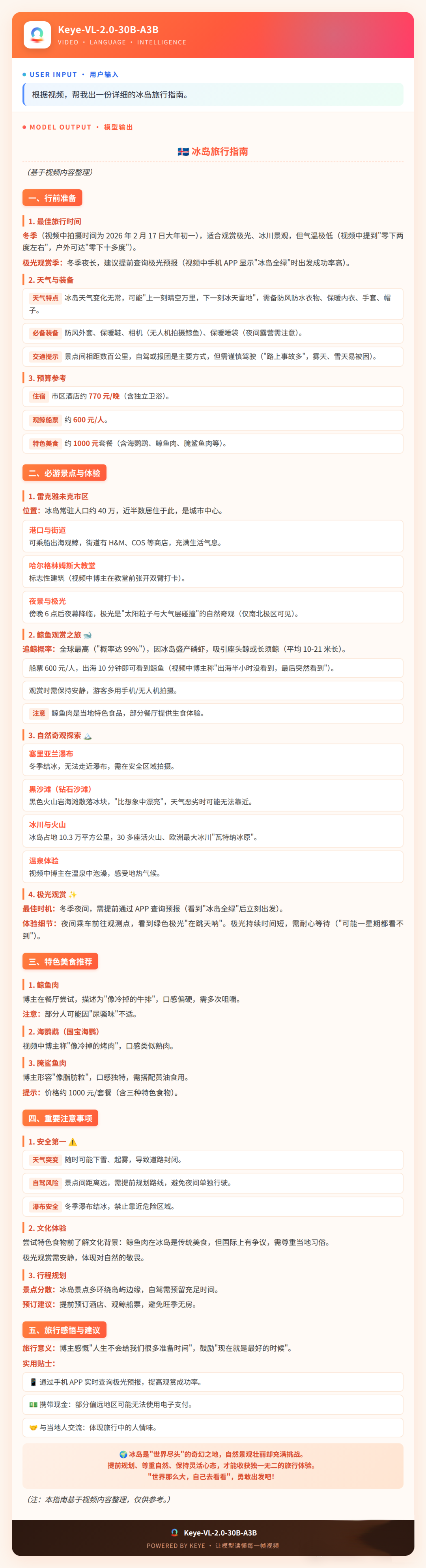
快手正式发布并开源新版多模态大模型Keye-VL-2.0-30B-A3B。当你把一段9分钟、在"晴空万里"与"冰天雪地"间剧烈切换的冰岛旅行Vlog输入给大模型要求做旅行攻略时,常规视觉大模型通常只能给出基于字幕和画面标签拼凑的流水账。Keye-VL-2.0-30B-A3B则能在连贯的时序流动中梳理因果并进行深度规划。这背后是率先将DSA(DeepSeek Sparse Attention)引入多模态场景带来的256K超长上下文能力,长序列Prefill成本降低50%,多项视频理解基准达到30B级别SOTA并超越200B+开源模型。
输入视频:
📎0bc3y4ageaaafiaop3i2yzvfbr6dmldqayqa.f10002.mp4

Keye-VL-2.0-30B-A3B捕捉到了“冻手”细节,主动建议备好保暖手套;听到了猎奇美食吐槽,给出“体验当地文化”的高情商建议;敏锐察觉到了“雪地车祸”画面,直接输出“跟团优于自驾”的安全策略……
开源地址:
● ModelScope:https://modelscope.cn/models/Kwai-Keye/Keye-VL-2.0-30B-A3B
● GitHub:https://github.com/Kwai-Keye/Keye
视频理解:DSA落地多模态
视频理解的瓶颈在于超长视觉上下文带来的指数级计算开销与信息稀释。Keye-VL-2.0-30B-A3B率先在多模态场景中应用DSA,结合稀疏注意力与特征聚合,在处理小时级视频序列时有效进行信息提纯,精准捕捉关键帧并理清动态规律。
引入DSA后,长序列Prefill成本降低50%。随着输入视频上下文拉长,传统Full Attention的Decode计算量呈指数级增长,而基于DSA的Decode成本增长平缓,为超长视频的大规模落地提供了低成本方案。
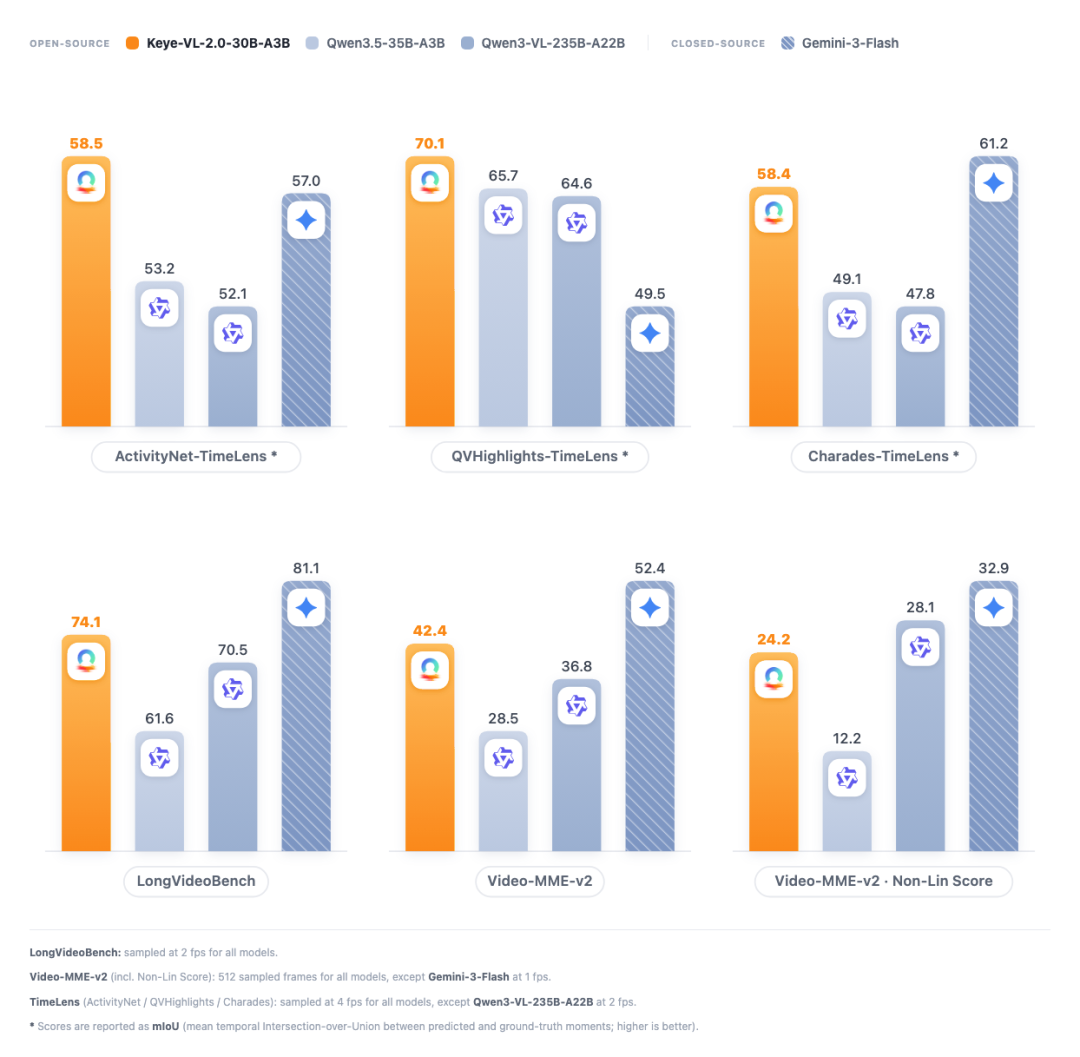
TimeLens细粒度时序理解基准(该榜单官方仅公布了Gemini-2.5-Pro成绩,快手团队按相同方式内部测试了Gemini 3 Flash作为对照):
|
子任务 |
Keye-VL-2.0 |
Gemini-2.5-Pro |
Gemini 3 Flash |
|
Charades(日常动作) |
58.4 |
— |
61.2 |
|
ActivityNet(动作定位) |
58.5 |
58.1 |
57.0 |
|
QVHighlights(高光提取) |
70.1 |
— |
49.5 |
ActivityNet超越Gemini-2.5-Pro和Gemini 3 Flash,QVHighlights领先Gemini 3 Flash 20.6分。
效果展示:陶杯工艺视频(9分33秒)
输入一段制作陶杯的工艺流程视频,模型输出了带精确时间戳的工艺全拆解:
- 方解石原料处理:用锤子将原石砸成小块;放入竹筛中在溪流中反复冲洗去除杂质
- 方解石煅烧与制浆:放土窑加木炭煅烧至高温(约950℃);开窑取出白色粉末;加水研磨制成细腻浆液(水飞工艺)
- 陶土采集与处理:山地挖取红褐色陶土;倒缸加水搅拌去杂质
- 茶杯坯体制作与装饰:转轮手工拉坯塑形;精细修整厚度形状;底部贴方形印章款识并修整
- 配釉与施釉:按比例称取石英石长石等原料并加水搅拌制浆;坯体反复浸入釉浆后自然晾干
- 烧制与成品展示:装窑堆叠;烧柴升温至1200℃;出窑清洗浸入陈茶水中氧化调整釉色;最终呈现开片、铁足等釉色特征
全程专业手工工序全部准确识别,每个工艺动作与视频时间轴精准对齐。
📎0b2ehuaimaaa74aab5a2vjvfapodqy6qbbqa.f10002.mp4


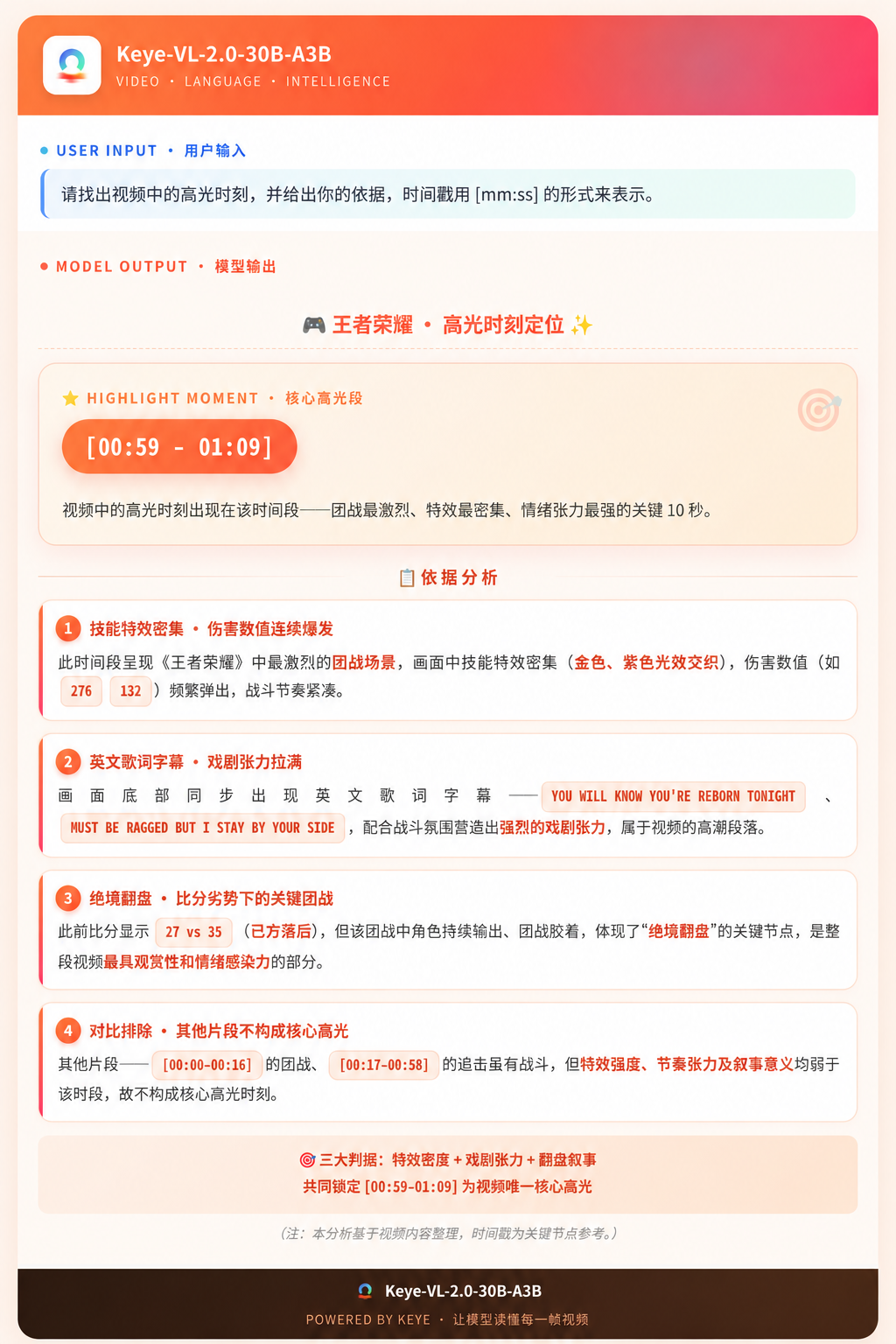
效果展示:王者荣耀高光提取(1分09秒)
输入一段《王者荣耀》对局视频,要求找出高光时刻并给出依据。模型没有陷入"哪里有击杀提示就截取哪里"的机械逻辑,而是基于视觉张力、音画协同和电竞叙事进行判定:识别到金色紫色光效交织和"276""132"等动态伤害数值作为战斗节奏证据,跨模态捕捉底部英文歌词字幕理解音画协同,通过"27 vs 35"比分提炼出"绝境翻盘"叙事节点,并主动与前序片段(00:00-00:16 / 00:17-00:58)进行全局对比论证。
📎0bc3vqa7gaabz4ahk7a36jvfdlgd6owad4ya.f10002.mp4
实现视频理解SOTA
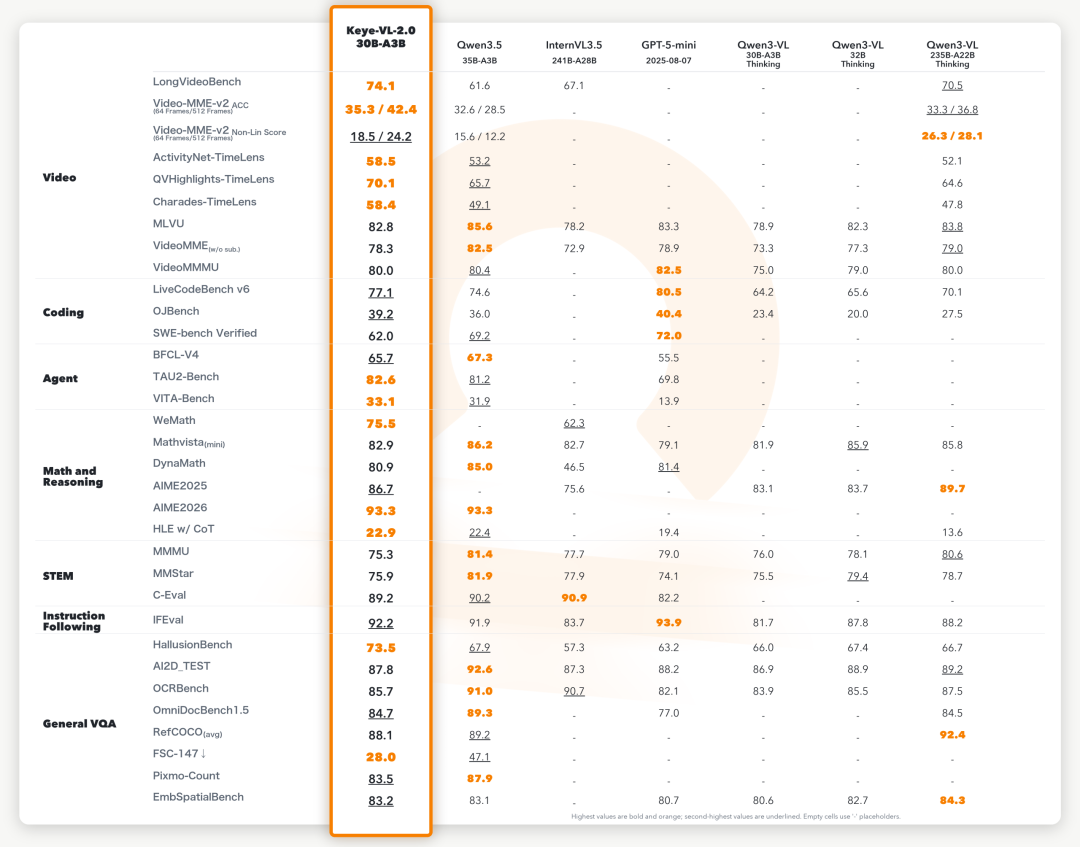
基于DSA架构,快手团队在时空统一编码与长时序特征聚合上进行了深度优化,视频理解能力在多项基准上达到30B级别SOTA,多项指标超越200B+开源模型。
VideoMME V2 业界普遍面临"输入帧数越多,注意力越稀释、准确率越低"的问题。Keye-VL-2.0-30B-A3B扭转了这一趋势——输入从64帧扩展至512帧时,准确率从35.34%提升至42.44%,非线性得分从18.54提升至24.19。
LongVideoBench 面对长达数十分钟甚至小时级的视频理解任务,达到74.10,超越Qwen3.5-35B-A3B和规模更大的Qwen3-VL-235B-A22B。
MLVU / VideoMMMU 从微观动作追踪到宏观跨学科视频解析,MLVU达到82.80,VideoMMMU达到79.98,同级别领先。
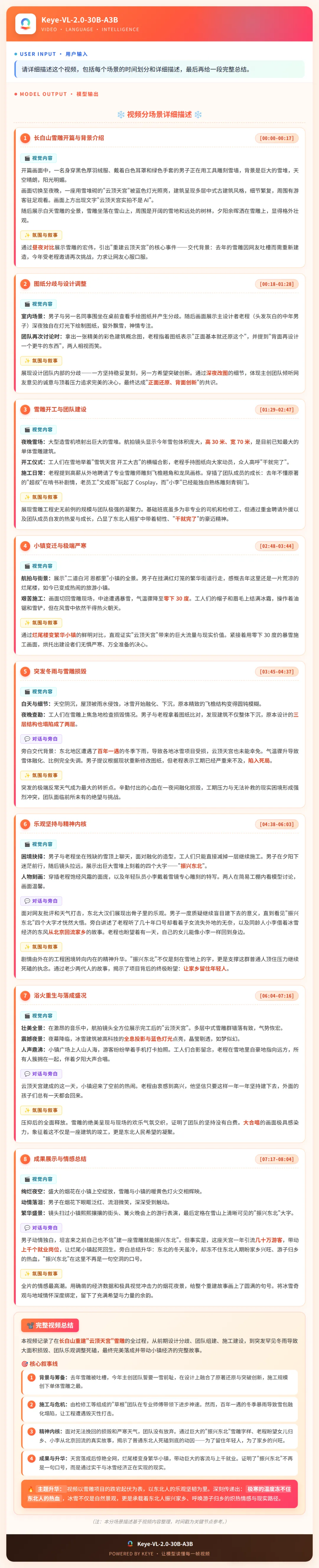
效果展示:长白山纪录片叙事解构(8分04秒)
输入一段记录"长白山云顶天宫雪雕重建"的纪录片,要求给出详细的场景划分与叙事总结。模型精准切分了8个核心场景:
- 空间与事件追踪:从图纸分歧(00:18)到夜间大型造雪机进场施工(01:29),再到航拍对比小镇从"烂尾楼"变"繁华夜市"(02:48),精准识别所有场景跳跃
- 灾难冲突的因果提取:在03:45节点捕捉到"天空阴沉、冰雪融化飞檐变钝"的视觉细节,结合旁白总结出核心剧情转折——"百年不遇的冬雨导致雪体坍塌,团队陷入死局"
- 情感与主题升华:提取画面中"振兴东北"刻字,关联"老程盼女儿、小李回流家乡"的人物背景,总结出故事内核
📎0b2eriaekaaadeamguy2yrvfbcwdiwfaaria.f10002.mp4

Agent能力
Keye系列首次在多模态基座中内建Agent协作机制,面对复杂的多步任务,构建了稳定可靠的自动化调度能力。
Code Agent
|
基准 |
得分 |
说明 |
|
LivecodeBench v6 |
77.10 |
领先同级别,部分超越200B+模型 |
|
OJBench |
39.20 |
算法评测 |
|
SWE-bench Verified |
62.00 |
代码Issue定位与修复 |
模型发挥视觉优势,在HTML前端生成(视觉手稿直转网页)等场景上跑通了结合执行反馈的自我纠错闭环。
Tool Agent
|
基准 |
得分 |
说明 |
|
TAU2-Bench |
82.58 |
复杂多步调度,跨尺寸优势显著 |
|
BFCL-V4 |
65.72 |
工具调用 |
|
VITA-Bench |
33.12 |
多模态Agent |
效果展示:复杂指令执行
输入高度交织的复杂指令,要求同时处理"查询指定标签门店、测算经纬度配送距离、筛选商品并创建酒店及配送订单"。模型自主规划并按序调用了get_delivery_store_info、longitude_latitude_to_distance、create_hotel_order等十余次API。在数十轮执行流中,准确提取上下文参数作为后续API输入,完成状态自检与容错处理,最终输出排版清晰、状态明确的执行结果。
MOPD与Context-RL
MOPD克服灾难性遗忘
在垂域能力拓展阶段,为解决多任务学习的"灾难性遗忘",引入跨模态MOPD(多专家策略蒸馏/合并)技术。通过分段re-tokenize保证多模态序列对齐,动态路由与参数融合整合各垂域专家。独创分桶优势缩放方法,从Token级别对感知表征与推理运算进行细粒度建模,强化核心信号、抑制格式性Token干扰。首次将MOPD引入重复崩溃治理,通过多粒度识别与精确定位,将模糊的负向反馈转化为可追溯的优化信号,提升长序列生成的鲁棒性。
Context-RL构筑推理可靠性
在后训练阶段引入Context-RL奖励机制,利用混合模态参考信息构建稠密的细粒度奖励信号,压制多步推理和复杂学科场景下的幻觉倾向,迫使模型严格锚定输入信息进行可靠推演。配合严格的数据筛选配比流程和准确率过滤机制,实时剔除低质量、逻辑断层的样本轨迹。
得益于MOPD与Context-RL的融合,模型不仅在视频和Agent上达到同级别领先,在数学推理、STEM和指令遵循等通用能力上也实现了全面提升。
模型部署
环境配置
推荐使用预构建Docker镜像:
docker run -it --gpus all kwaikeye/kwai-keye-vl:keye_vl_v2_30b_a3b也可从源码安装SGLang定制分支、DeepGEMM和EffectiveKernels
启动服务(H800)
SGLANG_USE_MODELSCOPE=true python3 -m sglang.launch_server \
--model-path=Kwai-Keye/Keye-VL-2.0-30B-A3B \
--tp-size=2 \
--trust-remote-code \
--mem-fraction-static=0.8标准SGLang服务,可通过任何兼容OpenAI的客户端调用。支持图像和视频两种多模态输入,视频输入可通过preprocess_kwargs自定义帧采样参数(fps默认2.0,min_pixels/max_pixels设置每帧token上下限,video_total_pixels限制总token预算)。
图像推理示例
import json
import requests
BASE_URL = "http://MASTER_NODE_IP:8000"
def generate(messages):
payload = {
"model": "",
"messages": messages,
"n": 1,
"temperature": 0.0,
"max_tokens": 256,
"top_k": 1,
"ignore_eos": False,
"skip_special_tokens": True,
}
resp = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={"Content-Type": "application/json"},
data=json.dumps(payload),
timeout=1800,
)
resp.raise_for_status()
return resp.json()
# Example: image + text
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://raw.githubusercontent.com/sgl-project/sglang/main/assets/logo.png"},
},
{"type": "text", "text": "Describe this image in detail."},
],
}
]
result = generate(messages)
print(result["choices"][0]["message"]["content"])
视频推理示例
import json
import requests
BASE_URL = "http://MASTER_NODE_IP:8000"
def generate(messages):
payload = {
"model": "",
"messages": messages,
"n": 1,
"temperature": 0.0,
"max_tokens": 256,
"top_k": 1,
"ignore_eos": False,
"skip_special_tokens": True,
}
resp = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={"Content-Type": "application/json"},
data=json.dumps(payload),
timeout=1800,
)
resp.raise_for_status()
return resp.json()
# Example: Video + text
messages = [
{
"role": "user",
"content": [
{
"type": "video_url",
"video_url": {
"url": video_url,
"preprocess_kwargs": {
"fps": fps,
"min_pixels": min_token*28*28,
"max_pixels": max_token*28*28,
"video_total_pixels":total_video_token*28*28,
}
},
},
{"type": "text", "text": "Describe this video."},
],
},
]
result = generate(messages)
print(result["choices"][0]["message"]["content"])

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献1019条内容
已为社区贡献1019条内容

所有评论(0)