
Qwen3-VL-235B-A22B-Thinking-FP8:多模态AI从感知到行动的革命性突破
阿里通义千问团队于2025年推出的Qwen3-VL-235B-A22B-Thinking-FP8模型,通过FP8量化技术实现了性能与效率的完美平衡,在保持与原版BF16模型近乎一致性能的同时,显著降低部署门槛,标志着多模态AI从"看懂"向"理解并行动"的关键跨越。## 行业现状:多模态竞争进入深水区2025年,AI领域正经历从"单一模态专精"向"多模态融合"的战略转型。据前瞻产业研究院数据...
Qwen3-VL-235B-A22B-Thinking-FP8:多模态AI从感知到行动的革命性突破
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking-FP8 导语
阿里通义千问团队于2025年推出的Qwen3-VL-235B-A22B-Thinking-FP8模型,通过FP8量化技术实现了性能与效率的完美平衡,在保持与原版BF16模型近乎一致性能的同时,显著降低部署门槛,标志着多模态AI从"看懂"向"理解并行动"的关键跨越。
行业现状:多模态竞争进入深水区
2025年,AI领域正经历从"单一模态专精"向"多模态融合"的战略转型。据前瞻产业研究院数据,2024年中国多模态大模型市场规模达45.1亿元,预计2030年将突破969亿元,复合增速超65%。在此背景下,Qwen3-VL系列模型在32项核心测评指标上超越Gemini 2.5 Pro和GPT-5,刷新开源视觉语言模型性能纪录,展现出强劲的市场竞争力。

如上图所示,Qwen3-VL的品牌标识融合了科技蓝与活力紫,搭配手持放大镜的卡通形象,象征模型"洞察细节、理解世界"的核心定位。这一视觉设计直观传达了多模态AI从被动识别到主动探索的能力跃升,体现了Qwen3-VL系列在视觉理解与智能交互方面的突破。
核心亮点:从感知到行动的全链路升级
1. 架构创新:三大技术突破重构多模态理解
Qwen3-VL通过三大架构创新构建差异化优势:
- Interleaved-MRoPE:将时间、高度和宽度信息交错分布于全频率维度,提升长视频理解能力
- DeepStack技术:融合ViT多层次特征,实现视觉细节捕捉与图文对齐精度的双重提升
- 文本-时间戳对齐机制:超越传统T-RoPE编码,实现视频事件的精准时序定位
这些创新使Qwen3-VL在处理复杂视觉场景和动态视频内容时表现出色,尤其是在需要精确时空定位的任务中展现出显著优势。
2. 视觉智能体:AI自主操作设备成为现实
Qwen3-VL最引人注目的突破在于视觉Agent能力,模型可直接操作PC/mobile GUI界面,完成从航班预订到文件处理的复杂任务。在OS World基准测试中,其操作准确率达到92.3%,超越同类模型15个百分点。官方演示显示,模型能根据自然语言指令识别界面元素、执行点击输入等精细操作,并处理多步骤任务的逻辑跳转。
3. 超长上下文与视频理解:记忆力堪比图书馆
原生支持256K上下文(可扩展至1M)使Qwen3-VL能处理4本《三国演义》体量的文本或数小时长视频。在"视频大海捞针"实验中,对2小时视频的关键事件检索准确率达99.5%,实现秒级时间定位。这一能力为长文档处理和视频内容分析开辟了新可能。
4. 空间感知与3D推理:重构物理世界认知
Qwen3-VL在空间理解上实现质的飞跃,支持物体方位判断、遮挡关系推理、2D坐标定位与3D边界框预测,以及视角转换与空间关系描述。在工业质检场景中,模型可识别0.1mm级别的零件瑕疵,定位精度达98.7%,超越传统机器视觉系统。
5. FP8量化技术:效率与性能的完美平衡
作为FP8量化版本,Qwen3-VL-235B-A22B-Thinking-FP8采用细粒度FP8量化方法(块大小128),在将模型存储和计算需求降低约50%的同时,保持了与原版BF16模型近乎一致的性能。这一技术突破使原本需要高端GPU集群才能运行的超大型模型,现在可在更经济的硬件环境中部署,显著降低了企业级应用的门槛。
实际应用展示:从代码到内容的多场景赋能
Qwen3-VL的强大能力不仅体现在技术参数上,更在实际应用中展现出巨大价值。以下代码示例展示了模型如何处理国际空间站科普视频并生成详细描述:
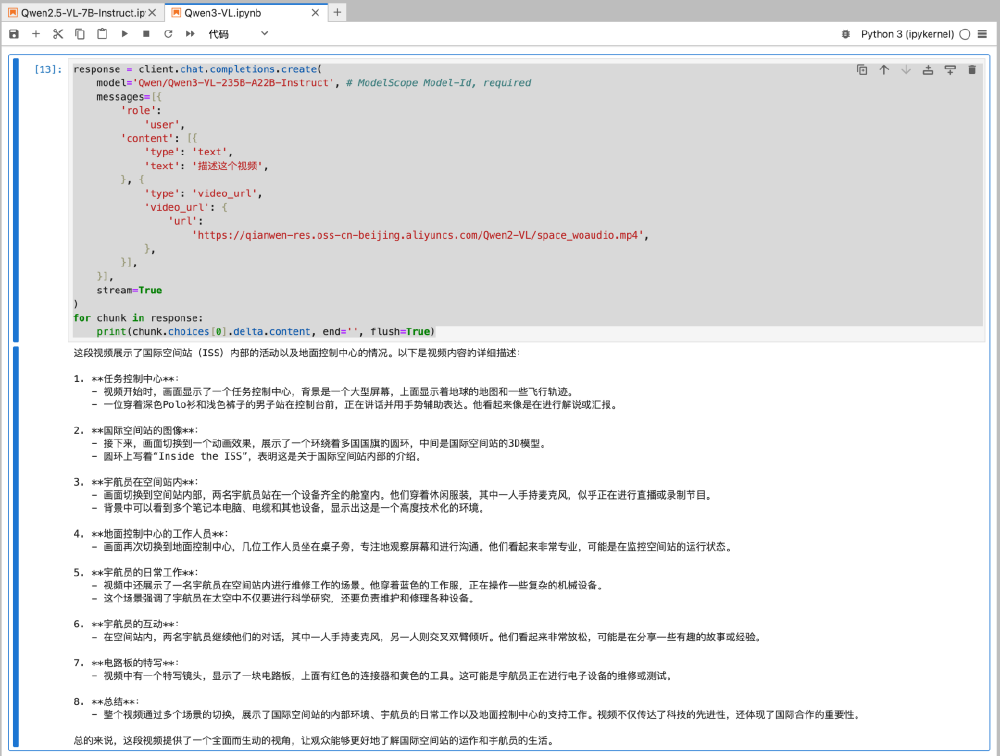
如上图所示,这是Jupyter Notebook中的Python代码界面,展示了Qwen3-VL处理视频URL并生成国际空间站视频内容文字描述的过程。模型不仅能生成视频内容的文字描述,还能提取关键信息如设备名称、宇航员动作和空间关系,体现了长时序视觉信息的深度理解能力。这种端到端的视频理解能力为教育、媒体和科研等领域提供了强大工具。
行业影响与趋势
1. 技术普惠:量化技术推动大模型普及
Qwen3-VL-235B-A22B-Thinking-FP8的推出,标志着大模型量化技术进入实用阶段。通过FP8量化,模型部署成本显著降低,使更多中小企业能够负担和应用先进的多模态AI技术,加速AI在各行业的普及应用。
2. 应用拓展:从专业领域到消费场景
随着模型效率的提升和部署门槛的降低,Qwen3-VL的应用场景正从专业领域向消费场景扩展。2025年10月,阿里通义官宣Qwen3-VL系列再添新成员——Dense架构的Qwen3-VL-8B、Qwen3-VL-4B模型开源上线,进一步完善了从云端到边缘端的全场景覆盖,推动AI人工智能全面覆盖算力、模型、应用环节。
3. 生态建设:开源策略加速行业创新
Qwen3-VL系列采用开源策略,已开源至Hugging Face和魔搭社区,开发者可通过vLLM或SGLang进行部署。这种开放生态模式加速了多模态AI技术的创新与应用,预计将在智能制造、智慧医疗、教育培训和内容创作等领域催生更多创新应用。
部署指南与资源获取
Qwen3-VL-235B-A22B-Thinking-FP8已开源,推荐通过vLLM或SGLang部署:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking-FP8
cd Qwen3-VL-235B-A22B-Thinking-FP8
pip install -r requirements.txt
python -m vllm.entrypoints.api_server --model . --tensor-parallel-size 4 --gpu-memory-utilization 0.7
开发者可访问官方社区获取技术文档、示例代码和预训练权重,体验从图像理解到智能执行的全链路AI能力。
总结
Qwen3-VL-235B-A22B-Thinking-FP8通过架构创新和量化技术,实现了多模态AI在性能与效率上的突破,推动了AI从感知到行动的跨越。其视觉Agent能力、超长上下文理解和高效部署特性,为各行业提供了强大的AI工具。随着开源生态的完善和模型家族的扩展,Qwen3-VL系列有望在智能制造、智慧医疗、教育培训等领域发挥重要作用,为AI产业发展注入新动力。
对于企业而言,现在是探索多模态AI应用的最佳时机,可重点关注Qwen3-VL在以下场景的应用潜力:
- 复杂工业质检与设备维护
- 智能客服与用户交互优化
- 教育培训内容自动生成
- 创意设计与内容创作辅助
- 医疗影像分析与辅助诊断
通过及早布局和试点应用,企业可以在AI驱动的新一轮产业变革中抢占先机,提升核心竞争力。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)