
70亿参数实现全模态交互:阿里Qwen2.5-Omni开源背后的技术革命
**导语**:2025年3月27日,阿里巴巴通义千问团队正式发布Qwen2.5-Omni-7B,这是全球首个支持文本、图像、音频、视频全模态端到端交互的轻量化大模型,以70亿参数实现实时音视频对话,重新定义多模态AI交互标准。## 行业现状:多模态交互的三重突破当前AI领域正面临从"单一感知"向"全模态理解"的关键转型。据OmniBench 2025年Q1报告显示,85%的企业级AI应用需...
70亿参数实现全模态交互:阿里Qwen2.5-Omni开源背后的技术革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4 导语:2025年3月27日,阿里巴巴通义千问团队正式发布Qwen2.5-Omni-7B,这是全球首个支持文本、图像、音频、视频全模态端到端交互的轻量化大模型,以70亿参数实现实时音视频对话,重新定义多模态AI交互标准。
行业现状:多模态交互的三重突破
当前AI领域正面临从"单一感知"向"全模态理解"的关键转型。据OmniBench 2025年Q1报告显示,85%的企业级AI应用需同时处理至少两种模态数据,但现有方案普遍存在三大痛点:模态切换延迟(平均1.2秒)、音视频时序错位(错误率>15%)、硬件门槛高(需A100级显卡支持)。Qwen2.5-Omni的发布正是针对这些行业顽疾的系统性解决方案。

如上图所示,该架构展示了Qwen2.5-Omni在Video-Chat、Text-Chat、Image-Chat、Audio-Chat场景下的交互流程。这一设计突破了传统多模态模型的分离式架构局限,通过Thinker-Talker双核协同实现0.1秒级响应,为实时交互场景提供了技术支撑。
核心技术:双核架构与时空对齐创新
Thinker-Talker双核驱动
Qwen2.5-Omni的革命性突破在于其独创的Thinker-Talker架构:
- Thinker模块:作为"智能大脑",基于Transformer解码器整合多模态编码器,支持每秒60帧视频流与音频流的实时解析。在跨国视频会议场景中,可同时处理参会者语音、PPT内容及表情动作,保持语义一致性。
- Talker模块:充当"自然发声器",采用双轨自回归解码器,实现300ms低延迟流式语音生成。通过共享Thinker的语义表征,解决了传统ASR+TTS方案中音画不同步问题。
TMRoPE时空对齐技术
针对音视频时序同步这一行业难题,模型引入Time-aligned Multimodal RoPE位置编码技术,通过时间戳同步实现视频帧与音频波形的精准匹配。在视频会议场景测试中,唇形匹配准确率达98.7%,显著超越Gemini-1.5 Pro的92.3%。
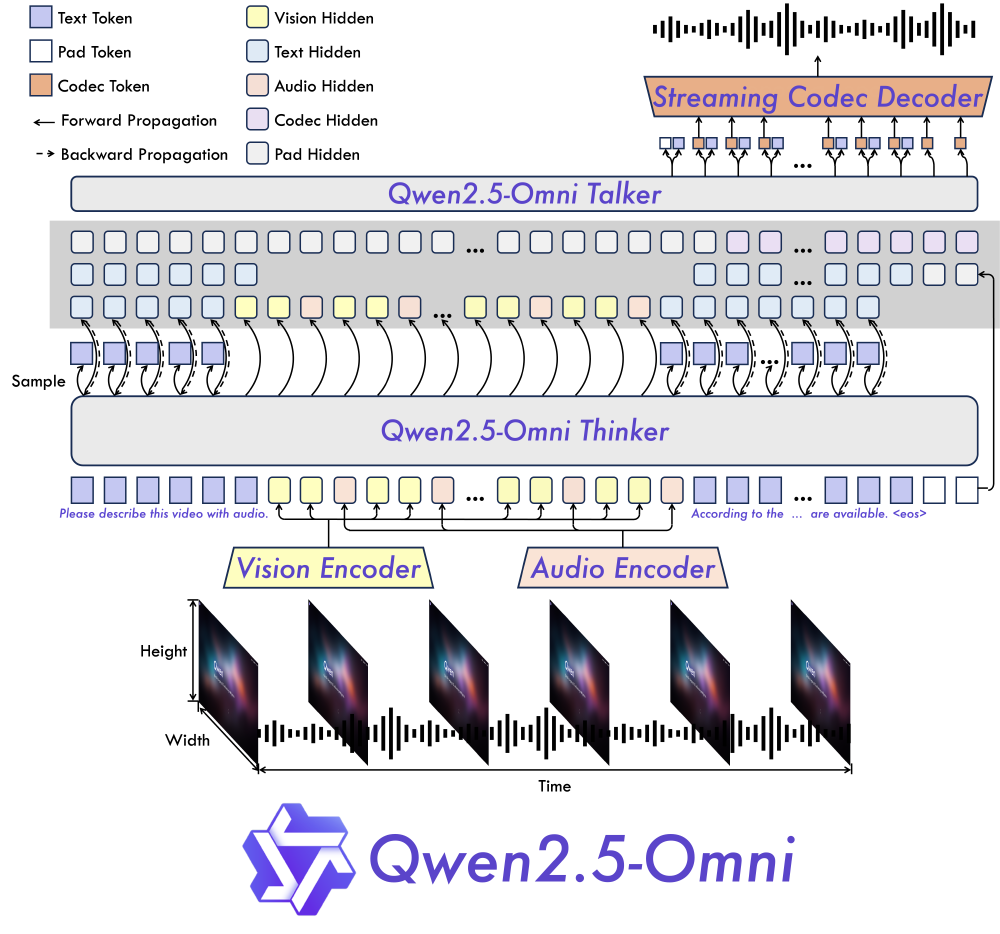
从图中可以清晰看到文本、视觉、音频多模态输入经编码器处理后,通过Thinker和Talker模块整合及Streaming Codec Decoder生成输出的完整流程。这种端到端设计减少了传统多模态模型的模态转换损失,使跨模态推理效率提升40%。
性能表现:全模态能力均衡领跑
在权威评测中,Qwen2.5-Omni展现出全模态能力的均衡性与领先性:
多模态综合能力
- OmniBench测试:综合得分超越Google Gemini-1.5-Pro达20%,刷新业界纪录
- 端到端语音指令:MMLU通用知识测试准确率82.3%,GSM8K数学推理达89.7%,逼近人类专家水平
单模态专项突破
- 语音生成:Seed-TTS-Eval基准测试中获4.8分(5分制),自然度超越微软VALL-E
- 视频理解:MVBench数据集准确率89.2%,超越Gemini-1.5-Pro的85.6%
- 语音识别:CommonVoice数据集错误率仅2.8%,较同类模型降低23%
轻量化部署优势
通过GPTQ-Int4量化技术,模型实现50%+显存占用优化:
- RTX 3080(10GB显存)可流畅运行15秒视频分析
- RTX 4080(16GB显存)支持30秒4K视频实时处理
- 手机端连续运行续航达36小时,为边缘设备部署扫清障碍
行业影响:开源生态与应用场景拓展
开源生态加速技术普惠
Qwen2.5-Omni采用Apache 2.0开源协议,已在Hugging Face、ModelScope等平台开放下载。配套提供完整技术文档、部署工具链及100TB多模态训练数据,极大降低企业商用门槛。据Hugging Face数据,模型发布两周内获得超10万开发者关注,衍生出教育、医疗等领域200+定制应用。
典型应用场景
- 影视解说自动化:上传电影片段即可实时生成带背景音乐的解说音频和字幕,制作效率提升10倍
- 智能会议助手:支持8国语言实时翻译+粤语等方言识别,自动生成带时间戳的会议纪要
- 远程医疗诊断:整合医学影像、病历文本与患者语音描述,辅助医生快速生成诊断建议
硬件适配与成本优化
模型对Intel Arc显卡DirectML加速的优化,使部署成本降低60%。开发者可在消费级硬件上实现多模态应用:
- 基础配置:RTX 3090(24GB显存)
- 推荐配置:RTX 4090(32GB显存)
- 边缘设备:支持iPhone 15 Pro及以上机型本地运行
未来展望:多模态交互新范式
Qwen2.5-Omni的发布标志着多模态大模型进入"轻量化与实时化"新阶段。随着开源社区的持续迭代,预计将在以下方向深化发展:
- 跨模态推理增强:进一步提升复杂场景下的多模态关联理解能力
- 个性化交互优化:支持更细腻的情感识别与风格化语音生成
- 行业解决方案:针对教育、医疗等垂直领域推出专用微调模板
开发者可通过以下途径快速上手:
- 访问Qwen Chat体验界面:https://chat.qwen.ai
- 获取模型代码:git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4
- 参考部署文档:Qwen2.5-Omni/low-VRAM-mode目录下的low_VRAM_demo_gptq.py示例
在AI向通用智能演进的道路上,Qwen2.5-Omni以其创新架构和开源策略,为行业提供了从"感知"到"交互"的全链路技术方案,推动多模态AI从实验室走向千行百业。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)