
Tongyi DeepResearch的技术报告探秘
引言
阿里通义实验室悄悄(其实动静不小)发布了一个叫 Tongyi DeepResearch 的 Agent 项目。它没有开发布会,没请明星站台,甚至没发通稿——但它在 GitHub 上架当天,就登顶了“每日趋势榜”。这速度,比人类发现“咖啡因无效”后换第三杯咖啡还快。
圈内讨论随之而来。有人兴奋地复制粘贴,有人皱眉点开论文附录,还有人默默关掉网页——因为文档里出现了“后训练”、“工具调用”、“强化学习”这些词。它们像宇宙射线一样,精准穿透了部分读者的知识防护层。
笔者碰巧一直在折腾类似方向,于是决定临时客串一下“课代表”角色,试着用更轻松的方式拆解三个核心问题:
Q1: DeepResearch 包含什么,怎么使用?
Q2: DeepResearch 模型是如何被训练出来的?
此外,如大家所知,科学研究是一个前赴后继的过程,在近些年的 Agent 相关研究中,也有诸多新的创意,也有很多同行的争议,也有大家默认的共识。本文也会从“共识”,“欠共识”和“新探索”三个方面讨论:
Q3: 我该参考 DeepResearch 的哪些设计?
本文的结构与上面三个问题一一对应。不同背景的读者,可酌情选择重点章节:
👨💻 AI 应用开发者:推荐精读第二章。你会找到模块说明、架构等信息。适合想集成进工作流的朋友。
🧪 AI 研究人员:重点看第三章。这里讨论数据构建、训练策略——以及那些“论文里没写但实验里很关键”的细节。建议搭配咖啡与耐心服用。
👔技术管理者 / 架构师:请移步第四章。这里梳理了目前的欠共识,帮助你判断“值不值得投入”“该抄哪部分”“要不要等下一代”。
项目 GitHub 地址:
HTTPS://GitHub.com/Alibaba-NLP/DeepResearch
开源模型 Tongyi-DeepResearch-30B-A3B:
HTTPS://ModelScope.cn/models/iic/Tongyi-DeepResearch-30B-A3B/
需要声明:
因能力和知识有限,本文中涉及的知识可能有纰漏,欢迎指正(最好带上一杯咖啡☕️)。部分信息,在技术报告[2]和 ArXiv 论文[12]中,表述不完全一致,本文仅加以注明,不做澄清。本文中提到的各项目,其所有权归属各项目作者。我们只是路过解读,不是宇宙产权局。
DeepResearch 包含什么,怎么使用?
Tongyi DeepResearch 项目是 2025 年 9 月 16 日发布的开源 Web Agent 模型,实现 SOTA(最先进)性能,在 Humanity’s Last Exam (HLE) 上得分 32.9、BrowseComp 上 45.3,以及 xbench-DeepSearch 上 75.0,超越 OpenAI 的 Deep Research 等专有模型。
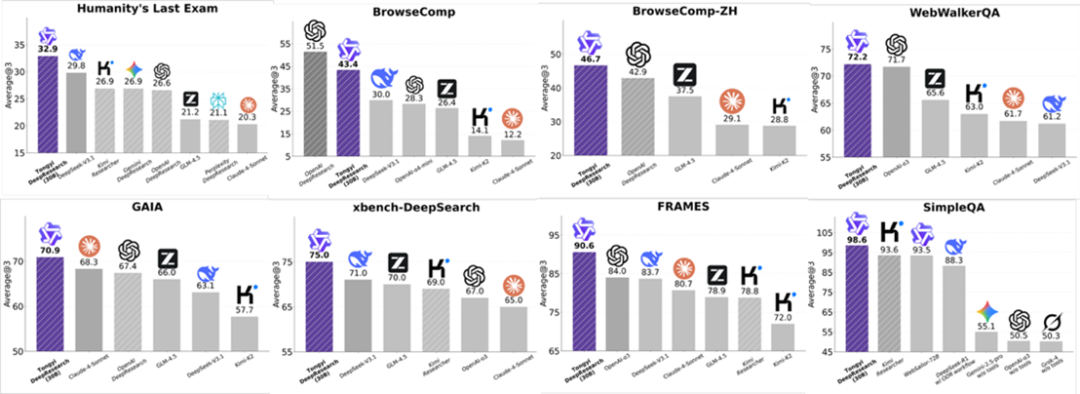
关键的三个词
这个项目的定位,是【开源的】【高性能】【Web Agent】。让我们逐个看这三个关键词。
首先【开源的】,自 2025 年年初以来,闭源的大模型 Grok, Claude, GPT 一骑绝尘,最近 OpenAI 发布的 GPT5 也是屠杀了大量榜单,从南天门一路杀到蓬莱东路。而开源社区阵营则略显低调,自 Llama 迭代减缓之后,由 DeepSeek,Qwen 和 Mistral 等扛起大旗,OpenAI 发布了 GPT-OSS,也并未掀起太多风浪。在商业化应用开发领域,闭源模型表现出了巨大的优势。在这种背景下,高质量的开源项目,特别是 Agent 相关研究,就变得至关重要了。
其次是【高性能】,这属于常规说法。如果炼丹炼出一个“低性能”模型,大家只会默默 RM -f,然后在周报上写“模型训练有点小问题,从新开始吧”。所以,这个星球上,每一个发布的模型都自然是“高性能”的,这就是传说中的幸存者偏差,类似于能返航的飞机一定是没被击中油箱的,能跑回泉水的英雄肯定血量大于 0。
最后是【Web Agent】,其实这个概念本身是有分歧的,与之相关的有 Web-enhanced LLM(搜索增强的模型)或者是 Deep Search(比如 Perplexity AI),或者叫 AI search(百度也推出了此功能)。从产品角度可以很多细分,从技术角度,Web Agent 至少需要具备“主动发起对 web 的请求”这个特性。我把这几类归结如下,换言之,这些是本项目的替代技术。
| Web-enhanced LLM | Deep Search/AI Search | Web Agent | |
| 例子 | 各个AI工具上“联网搜索”功能,比如夸克等 | Jina/Perplexity AI等 | Tongyi DeepResearch/OpenAI Deep Research/Gmini Deep Research/Manus/OWL |
| 技术视角 | 将用户请求交给搜索引擎,返回结果拼进LLM的上下文,由LLM完成总结 | 一套循环流程,反复(或者多次)查询直到问题已可以被回答 | LLM调用工具的方式调用搜索引擎,汇总分析结果 |
这个项目里有什么?
这个项目包含这样几个部分:
- 模型:即 DeepResearch-30B-A3B[1],这是一个 30B 的 MoE 模型,每次激活 3B 参数。这么小的尺寸和激活参数量,保证了推理的效率。特别的,这个尺寸具备在 PC/Mac 上部署的可能,以 MacBook Pro 的 M2 为例,就可以部署 30B 的模型。
- 模型推理代码,由于模型采用了 Qwen3MoeForCausalLM 的架构,跟 Qwen3 模型的部署推理方式完全一致,可以参考 Qwen3 系列的模型部署,比如 Qwen3-30B-A3B-Instruct-2507[4]。可以直接使用 Vllm 和 ollama 使用本地部署,此外,ModelScope 提供了开箱即用的模型服务[3]。
- 实验评测代码,实验代码在项目的 GitHub 中开源[3],采用字节跳动的 Sandbox_fusion 作为代码执行的沙箱和评测环境,可以用来重现报告中声明的实验结果。这个代码包含了一个名为 ReAct 的 AgentUse 模式。
- Agent 推理代码,项目本身并未直接提供 Agent 推理代码。但因为采用了 Qwen3 底座,所以兼容 Qwen-Agent 框架。特别的,在技术报告和论文中提到的 IterResearch 模式(即 heavy 模式),并未在开源代码中提供(截止 2025-09-23)。代码[1]中提供的仍然是 ReAct 模式,这大约是由于银河系的某些量子折叠产生,你懂的。如果感兴趣,可以联系我们开发一个非官方版本的 IterResearch 模式 Agent。另外,百炼提供了一个 Agent 的体验版本[11]。
这四个部分的大致架构如下,图上的实心方块是模型,白底绿色方块是组件或者框架。黑色的方框是核心特点。
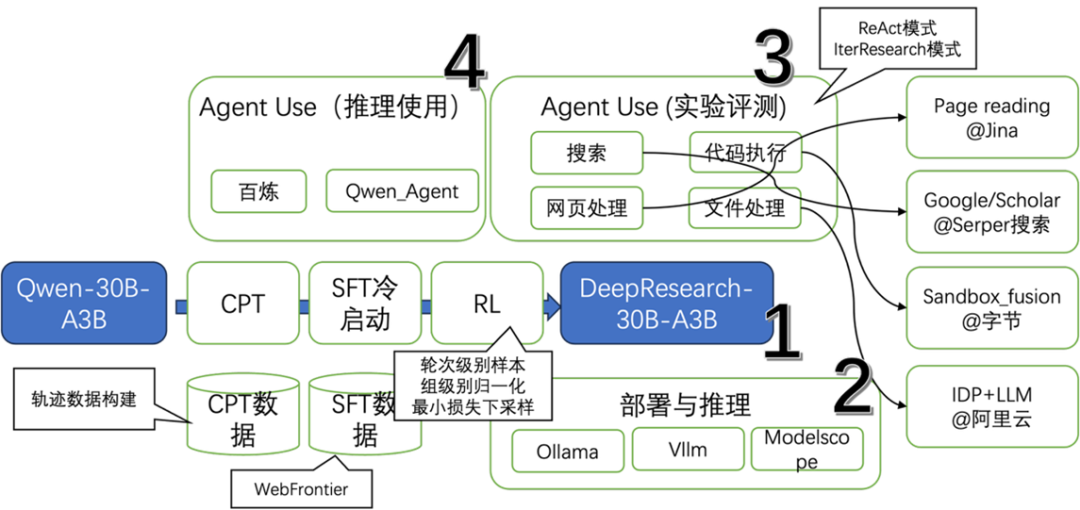
根据用途,这几个模块可以组合使用,大家如果
-想研究模型,选择 1+2+3;
-想研究 Agent,选择 3;
-想体验/开发应用,选择 4;
-想知道为什么宇宙终极问题的答案是 42,发邮件给我/编辑的邮箱,并配上一个 doge 表情。
DeepResearch 模型是如何被生产出来的?
如同大部分推理模型的训练,Tongyi DeepResearch 的模型研发,大致上包含以下三个阶段。冷知识:当一个人类,需要描述一个复杂过程,他/她往往会说:3 个阶段。你知道的,这很难解释为什么他们需要十根手指。
1、增量训练及其数据合成(包含两个 CPT 阶段)
2、监督微调及其数据合成(SFT 阶段,作为冷启动)
3、强化学习阶段(RL 阶段)
这几个阶段的串联如图所示,而其中的最左侧的 Base Model 指的就是基础预训练模型,对于此 Deep Research 项目,使用的是 Qwen3 的 30B 预训练模型:Qwen3-30B-A3B[5]。经过本章节描述的几个阶段,最终得到 DeepResearch 的模型,即 DeepResearch-30B-A3B[3]。在本章节,我们会先讨论这样设计的必要性,然后每个阶段各自介绍其关键设计。

为什么是这样三个阶段?
在详细串一下这些细节之前,我想大致先聊聊一下这个流程设计的共识与欠共识。
首先,从 21 年开始,大家都认可数据制作上花的每一分钱(和时间)都是值得的,大量研究指出高质量的数据对模型训练的效果是至关重要的。特别的,合成数据,已经成为了开源模型中最不开源的部分之一,另一个是 AI 工程师们热衷的咖啡品牌。大家注意到,开源模型提供了可以下载分发的模型,但没有提供其训练数据,所以是模型开源,而训练数据难开源。背后原因很多,笔者回头可以写一个专题讨论此部分,感兴趣的读者可以评论区告诉我。此项目中,作者团队还是很贴心的(虽然也没有提供训练数据)提供了很多的数据合成细节,和一个相关项目的数据[9]。
第二个是关于增量训练的必要性,这是比较接近共识的,但仅限于“增量训练”这个词本身。从做法上看,有的项目组会更多让模型偏向于 instruct 模式,有的则会扩充模型对一些特殊指令的遵循能力,更有甚者会在增量训练中强化 ICL。当然这些差别主要体现在损失函数设计和训练数据上。这个项目中,作者们管他们的增量训练叫做“智能体增量与训练”,这名字在银河系可以排到第三名(很可惜),第二名是“自进化跨域自适应多模态模型”,第一名太长无法显示,因为超过了本模型的上下文长度限制。额外的,为什么是“接近共识”,蚂蚁集团最近发布的 Atom-Searcher 就是一个跳过了 CPT 阶段的方案[15]。
第三个是冷启动+强化学习的必要性,随着 Deepseek 的报告,和大量类似研究的披露,从业者使用一些精心设计的冷启动数据和一个良好设计的 RL 环境,用于最后一个训练阶段,这一点也接近了共识[7] 。此外在 Websailor 的工作中,作者提到在工具场景中,纯 RL 无法使工具调用次数有效提升,而这一提升可以靠冷启动 SFT 阶段完成。[6]
让我们逐个来分析这三个阶段。
增量训练及其数据合成
在我们分析讨论这个阶段之前,我想提出一个问题:
“Agent 的增强训练(CPT)究竟需要增强什么?”
或者说,“Agent 的 CPT 与垂类模型 CPT、以及推理模型 CPT 在对 LLM 的增强上有什么不同?”
这个问题很重要,因为如果我们认为 Agent 的 CPT 就是知识的增强,那么我们应该侧重于补充对于 Agent 所使用的工具的知识;或者,如果我们认为 Agent 的 CPT 就是推理能力的增强,那也许我们应该直接基于一个推理模型,比如 OSS-GPT 作微调(而非增强训练)。
这个问题和“周五的晚高峰的交通状况还能不能更糟糕?”并称为阻碍 AI 发展的核心命题。这当然就是欠共识的一部分,这份报告[2]中的细节也许可以帮我们找到线索。
首先该项目的 CPT 的数据包含两大类:
- 常见的高质量 CPT 数据,比如爬虫数据,知识图谱。可预计的,这里肯定有很多高质量的私有数据,他们价值连城。但这一点与大部分的 CPT 差异性不大,可以认为是对预训练的有效补充和延续。毕竟在 LLM 的每一个训练阶段中,延续上一个阶段,是非常有效的设计。
- 后训练的轨迹数据,这是这个章节最关键的一个点:轨迹合成数据。我们先看一下报告中一张图:
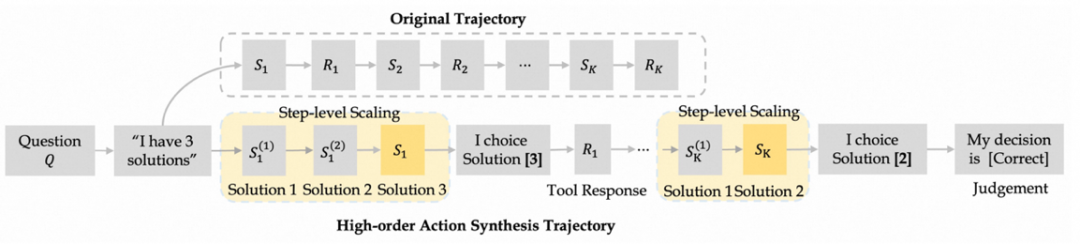
图展示了一种合成轨迹的方式,考虑一个问题 Q,原始数据的轨迹是图上方的 Original Trajectory,从轨迹中用步骤级别展开,图上的“I have 3 solutions”,“I choose Solution[3]”等就是关键的步骤,对这些步骤,扩展为多个可能的分支。比如在”I have 3 solutions”时,分别得到三个候选的 solution,图上显示是串形得到的(也许也可以并行?)然后对于其中任何一个,往后展开(rollout)。熟悉强化学习和 AlphaGo 的朋友们对这个应该很熟悉。对于轨迹,拆分成动作数据,包含单步的规划、推理动作和多步的决策动作。这个拆分维度是很有启发性的,这三个维度可以较为全面的覆盖 Agent 对于 LLM 能力的需求。换言之,可以从这三个角度去评判“LLM 是否胜任 Agent”,也能指导各种 Agent 中 LLM 的升级迭代。
但这类似轨迹构造做法都有个两个小小的问题:构造数据的样本采纳率不高,并且非常低效。
首先,展开过程中,会产生大量无用的尝试,导致 rollout 的样本中,真正可用的高质量数据不多。其次,这个过程很慢,特别是对工具的调用环节,在代码中,作者们准备了一个多线程并行。在知乎上,有一名自称项目作者提到“一条轨迹的价格远比想象中昂贵”,也从侧面反映了采样问题对此类研究的制约。回到合成数据阶段,可以明确知道的是,该项目的作者们做了很多的探索,期待更详细的报告。
在 Tongyi DeepResearch 提出了一个新的 Agent 模式,叫做 IterResearch。和大家熟知的 ReAct 模式相比,IterResearch 有两个关键点:
- 良好维护的核心报告,
- 动态维护的工作空间。
ReAct 中,模型的上下文会快速的被工具调用的结果所占用,比如一个打开网页的工具调用,就能一次性用掉 10k+的上下文。这不仅会严重占用可怜的 LLM 上下文窗口,而且会产生严重的污染问题——模型会忘记之前的问题和分析思路。所以在 IterResearch 中,选择了将工具调用的结果所组成的工作空间动态维护,而把核心的分析思路等放在一个专门的核心报告。这种做法可以理解为是针对多步工具调用中的上下文折叠压缩,这个设计也是此项目在长周期 Agent(long-horizon)的关键设计。很可惜的是,这个 IterResearch 的代码并未随着开源,仓库中只提供了 ReAct 的代码。
部分解读者[10]推测,IterResearch 模式就是论文[12]中提到的 heavy 版本。如果成立,则可以通过论文实验得知此项工作带来的增量是巨大的,比如在 Humanity’s Last Exam 中,IterResearch 比 ReAct 要高 7.9pt,在 BrowserComp 上要高 14pt。
IterResearch 和 ReAct 在训练中,还有诸多的不同,这不仅仅体现在数据上,还体现在数据并行和采样上。项目作者并未透露 DeepResearch-30B-A3B 采用哪种方式训练。我推断有两种可能:
- 还存在一个 DeepResearch-30B-A3B-Heavy 并未放出,而且 DeepResearch-30B-A3B-heavy 采用了 IterResearch 方式训练。本次开源的 DeepResearch-30B-A3B 仅仅用 ReAct 方式训练。
- IterResearch 和 ReAct 在训练框架中实现了兼容,目前开放的 DeepResearch-30B-A3B 也可能可以在 IterResearch 上工作。
最后,让我们回顾一下前面那个问题:“ Agent 的增强训练(CPT)究竟需要增强什么?”从这个项目中的数据合成策略上看,Agent 的 CPT 可以增强单步的规划、推理动作和多步的决策动作。注意这是一个更接近于充分,也许非必要的条件。在没有更明确的共识之前,这是一个很棒的参考答案。
监督微调及对应数据合成
这个阶段主要用作对 RL 的冷启动,在该项目的技术报告中提的不多。笔者推测原因有二:
1. 框架成熟改动不大。
2. 主要数据驱动的。
从设计上讲,这个阶段的存在,是很接近于共识的。从 DeepSeek 的论文中,冷启动存在的意义就已被阐明,无非是还有很多研究者相信,去除冷启动的之后 RL 也能达到类似的效果,比如 DeepSeek-R1-Zero。但在大量代码生成任务和数学任务中,冷启动都证明过其有效性。在 Agent 的训练中,虽不能说这是共识,但也是很自然的做法。
让我们重点聊一聊这个阶段的数据合成。这个阶段的数据,该项目引入了一种新的 web 数据合成方法 WebFrontier,有三个要点:
- 种子数据生成,使用网页数据,文档和电子书作为基础,首先将其清洗并处理成 chunk,利用一个模型对其生成种子 QA 对,这种做法在大部分数据合成中都存在。
- 迭代式复杂度升级,这里包含一个自举的过程,由一个 agent 装备工具(就是本 DeepResearch 中的四个工具:通用搜索,学术搜索,网页浏览,和代码执行),在要求此 Agent 改进问题和答案。显然这个过程是为了增加数据与 DeepResearch 场景的契合度,并且此阶段得到数据的过程并直接评估数据质量,而是尽可能用上工具。
- 质量控制,这个阶段是掐头去尾,即去除过于简单和过于难(可能是不正确的)样本,首先是通过一个不带工具的 Agent 去试图求解,如果问题能被解决就说明太简单了,过滤掉;然后是一个强力模型配置工具组成的 Agent 去试图求解,如果能通过则保留。对于未能求解的再经过一次人工审核,回收部分样本。
WebFrontier 是一个很有趣的数据构建方式,它采用了“种子”-“扩展”-“评估”等经典套路,而且其中扩展阶段使用本项目整体的工具集合。总体设计思路上是对场景(评测数据,工具)深度绑定的,这种类似于过拟合的绑定,带来的潜在问题是跨团队的复现与跨场景的效果下降[13]。
我注意到,在作者团队之前的工作中,从 WebWalker,WebSailor,WebSailor-v2,到 WebShaper 提出了大量数据构建方式,从网页点击,到图谱合成,再到形式化建模。这一系列工作产生的数据,都可能帮助了 DeepResearch 的训练。但在 Arxiv 论文中[12],仅提到了 webFrontier,笔者推测是为了突出技术贡献点,毕竟之前那几个工作也都有各种的论文发表,不需要额外强调。
回到 WebFrontier,从训练角度,这种设计能很好的保证训练数据与模型推理时见到的工具的一致性,但似乎也有些小小的隐患:
工具的拓展性如何得到保证?
在本项目中,工具集合是固定的四个,的确是不需要考虑扩展使用的。但对于产业使用,或者更广泛意义上的 Agentic 应用,大家对于工具的预期并不是固定的集合。特别是随着 MCP 生态的兴起,动态的工具集合似乎是更符合产业现状的。
那么,WebFrontier 对于动态工具集合的有效性就是一个值得思考的问题了,同样,对类似的研究中,我们也许都可以加一个维度去考察模型。
强化学习
强化学习的基础优化算法选择了 GSPO[8],注意到在报告[2]中提到的是 GRPO,在 Arxiv 提到的是 GSPO[12]。这两种在目前都比较成熟,我们重点看看 DeepResearch 的项目中,有哪些改动。
在训练策略上,将每条完整的轨迹自然的分解为多个训练样本,让每一个轮次对应一个样本,而传统的方式是每条轨迹对应一个训练样本(mono-contextual)。假设一个问题有 G 条轨迹,每条轨迹平均有 T 个轮次,那么传统方法只能得到 G 个样本,而该方法可以得到 G * T 个样本。这个做法能提高数据的利用率,但是有一个小的信用分配问题:虽然每个轮次都被视为独立样本,但最终任务的成功或失败是由整条轨迹决定的。如何将最终的奖励(或惩罚)公平、准确地分配给轨迹中的每一个中间轮次,是一个经典难题。
组级别的优势归一化,所有轮次的样本被放在一起进行组级别的优势归一化(group-level advantage normalization)。这意味着,无论一个样本来自研究的早期、中期还是晚期,它们都在同一个标准下被评估和学习。这会有利于模型不会只偏向于学习“开头怎么想”或“结尾怎么答”,而是能均衡地掌握整个研究过程中每一阶段的推理和综合能力。
为了兼顾轨迹长度差异带来的每个 batch 样本总数不固定的问题,加入了一个最小损失下采样,将数据库下采样为数据并行规模的整数倍。
另外,IterResearch 的工作模式,使得状态仅包含“上一轮的报告”和“最近的工具响应”。如果“报告”的综合能力不足,未能完全捕捉之前所有轮次的关键信息,那么模型在当前轮次的决策就会基于一个有损的、不完整的历史摘要。换言之,这个方式对报告的质量有着非常严重的依赖,如果报告生成模块本身有幻觉或者遗漏问题,对整体的影响可能是致命的。
最后,项目作者团队在 Infra 上,还有个很棒的设计,即双环境策略。它包含一个模拟环境,和一个真实环境。在模型演化中,先在模拟环境中作快速迭代,再应用到真实环境中,可以参考 websailer-v2 和 Environment Scaling[15]。
参考 DeepResearch 的哪些设计?
前文已经提到了诸多共识与欠共识,我们在此章节作更多讨论。技术上的共识往往都表示技术的成熟,或者说一个研究阶段的终结。比如 GPT3.5 和 Llama 促成行业达成了一个关键共识,基于 transformer 的预训练模型是通用的生成器。这个是共识,与之对应的是之前的欠共识,即大量预训练 vs 小规模专用模型的讨论,以及各种 CNN 架构的设计争议。这些欠共识随着共识的出现,而渐渐淡出了主流讨论圈。注意是淡去,而不是消失了。毕竟逆袭的故事在学术界也多次发生,Hinton 对神经网络的坚持就是最励志的故事之一。
在 DeepResearch 以及 Agent 的模型训练中,有哪些是欠共识,哪些已经接近共识了呢?
RQ1: 我是否需要 Deep Research Agent?
如前文提到,Deep Research Agent 这种技术,主要是自主问题求解。如果你已经在用,或者在调研如下的场景,那你可以考虑 Deep Research Agent:
- AI 搜索:典型是百度的智能搜索,Perplexity AI,夸克搜索,Google 的 AI summary 等。这类场景是 Deep Research Agent 的潜在场景。但此技术方案相比于现有的“LLM 总结搜索引擎结果”,在效率上有明显短板。他实在太慢了,一次查询往往需要数分钟。
- 分析和报告生成:典型是 OpenAI 和 Gemini 的 Deep Research。这种场景是很合适的,但需要注意模型的幻觉和数据源的可信问题。
RQ2: 我是否需要 Agent 专用模型?或者通用大模型就够了?
当下这个问题仍处于欠共识状态。
这个问题的答案,对应了两种截然不同的技术路线,一个是专门训练模型以满足 agent 的需要,另一个是扩充技术模型的基础设施以满足 Agent 的需要,比如 OWL。
首先在评测上,前者是 SOTA,以 Humanity’s Last Exam 为例,通用模型比如 DeepSeek- R1 的 24 分就比 Tongyi DeepResearch 的 28.8 低了不少。但实际使用中,还有更多的争议。
专用模型的优势在于 1. 专门训练掌握工具调用 2. 长程推理,自主决策超过了通用对话模型本身。而通用模型的支持者会认为这两个点都可以由通用模型覆盖。
RQ3: 我需要花很多时间准备数据吗?
这个问题虽有争议,但相对可观的从业者都赞同数据质量的必要性。对于 Agent 的模型而言,什么是高质量数据呢?下面几个线索是存在的
- 数据标注的质量,一个粗浅的区分方式是:a)人工标注 b)模型标注 C)欠标注。对于人工标注数据,大家可信度很高,但实操中,人工数据质量并非无懈可击,由于错误相信人工标注数据导致的问题也常常发生。模型标注数据在合成中已经大量使用了,精心构建的数据链路,多模型的混合标注方案也是能够保证一定的质量的。对于欠标注数据,部分研究者认为质量过低,但笔者注意到,在预训练以及 CPT 中,欠标注的数据的混入是值的探索的。
- 轨迹多样性,相比于问答数据,轨迹数据是非常昂贵的数据,其获取和精细标注的成本都很高,一方面由于轨迹很长,另一方面涉及到了多次的工具调用。昂贵带来的一个问题就是稀少,更进一步导致的问题是多样性差,因此在 Tongyi DeepResearch 项目中重点探索了对于轨迹数据的构建。
RQ4: 我是否需要 CPT?
前文提过一个问题“Agent 的增强训练(CPT)究竟需要增强什么?”,我们当时的结论是目前并未明确。此外从成本角度考量,CPT 消耗的算力,数据成本,人力成本都不容小看。那能否跳过 CPT 阶段呢?
从当前的同类研究上看,CPT 并非是必选的。跳过 CPT 方案,而侧重于 SFT 和 RL 也是可行的路线,见[15]。
RQ5: 我是否需要 SFT/RL?
如果想更加低成本的尝试,或者定制自己的 Deep Research Agent,一个最直接的方式,就是连 SFT/RL 都忘掉,接入一个你能买到的最贵的最大的模型,然后花点时间好好设计你的 Prompt。当然有很多框架都能更好的维护其中的工具调用和上下文,比如 OpenManus,OWL。
RQ6: 我能否参考这个方案训练其他 Agent?
虽然 DeepResearch 是一个很有趣的 Agent,大家在研究和开发中,还需要各种各样的 Agent,比如 Terminal 的 Agent,GitHub 的 PR Agent 之类。那 DeepResearch 的方案能否帮上这些研究呢?
这个问题远没有共识,一些线索是:
- 在合成数据+多阶段训练方式的有效性,在大量场景中都得到了证实,也许可以参考这种总体流程。
- 数据合成方法,特别是 WebFrontier 这种数据合成方式,却跟工具很有关,其有效性未被证明可以迁移到其他的工具和对应 Agent 中。如果你想训练一个 Excel Agent,你是不会用网页数据作为构造源头的。
- 封闭的工具集合看起来是有利于模型训练的,在 DeepResearch 研究中固定几种工具换来了稳定的数据构建链路和效果,一个自然的推理是,这种做法也许会降低 Agent 训练的难度。如果你的 Agent 的工具种类复杂,不妨先固定一些,训练模型。
- 长程推理,看起来越来越有希望的到解决,但目前未必那么成熟,如果你的场景里非得让 Agent 推理 20 步,也许你该想想简化这个问题。
最后
Tongyi DeepResearch 是一个很棒,并且有很好参考意义的项目,不仅提供了强而有力的模型,并且为上述诸多非共识提供了一些解决的线索。阅读其文章的感觉,就像你大热天 38-39 度,上了一天的班回到家,打开冰箱看到一瓶冰镇啤酒,还有一盒卤牛肉:Delicious!很期待学术界和产业界有越来越多这样优秀的工作分享。如果对这个项目及其延展部分还有感兴趣的,欢迎评论互动,也欢迎给我写邮件,<luozhiling@zju.edu.cn> 讨论。
路仍然很长,我们都还在路上。
参考文献
[1] Tongyi-DeepResearch-30B-A3B 的 modelscope 模型地址:
HTTPS://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B/summary
[2] Qwen3-30B-A3B-Instruct-2507 的 modelscope 模型地址:
HTTPS://modelscope.cn/models/Qwen/Qwen3-30B-A3B-Instruct-2507
[3] Tongyi DeepResearch GitHub 地址:
HTTPS://GitHub.com/Alibaba-NLP/DeepResearch
[4] Tongyi DeepResearch 技术报告:
HTTPS://tongyi-agent.GitHub.io/blog/introducing-tongyi-deep-research/
[5] Qwen3-30B-A3B 的模型地址
HTTPS://www.modelscope.cn/models/Qwen/Qwen3-30B-A3B
[6] WebSailor: Navigating Super‑human Reasoning for Web Agent
HTTPS://arxiv.org/pdf/2507.02592
[7] WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
HTTPS://arxiv.org/pdf/2509.06501
[8] Group sequence policy optimization
HTTPS://arxiv.org/pdf/2507.18071
[9] WebShaper 数据
HTTPS://modelscope.cn/datasets/iic/WebShaper
[10] 深度解析通义 DeepResearch:阿里开源的 300 亿参数深度研究智能体
HTTPS://blog.csdn.net/m0_37733448/article/details/151958917
[11] 百炼的 Tongyi DeepResearch 体验地址
HTTPS://bailian.console.aliyun.com/?spm=a2ty02.31808181.d_app-market.1.6c4974a1tFmoFc&tab=app#/app/app-market/deep-search/
[12] Tongyi DeepResearch 论文
HTTPS://arxiv.org/pdf/2509.13309
[13] 关于过拟合的讨论
HTTPS://zhuanlan.zhihu.com/p/1951785880655209261
[14] 疑似项目作者的在知乎上的讨论
HTTPS://www.zhihu.com/question/1951587761955009058/answer/1952425910868357997
[15] Towards General Agentic Intelligence via Environment Scaling
HTTPS://arxiv.org/pdf/2509.13311

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 1
1- 0



 已为社区贡献959条内容
已为社区贡献959条内容

所有评论(0)