
PDF解析迎来技术革新!阿里新产品实现复杂文档端到端结构化处理
前言
9月24日云栖大会现场,由阿里巴巴爱橙科技数据技术及产品团队自主研发的PDF解析神器正式亮相并同步开源模型。这款基于Logics-Parsing模型构建的AI工具直指当前PDF解析领域的技术痛点,显著提升复杂文档的结构化处理能力。
PDF 文档作为各行业信息存储与传播的主要载体,通常包含丰富的多模态内容,如文本、图像、表格、数学公式等。不论是为了支持大语言模型(LLM)的训练、构建结构化知识库或是实现智能问答系统(如 RAG),都需要将 PDF 文档中的非结构化内容高效、准确地转换为结构化、机器可读的数据。因此,高质量的PDF 解析能力是支撑下游人工智能应用的关键基础。
然而,现有的 PDF 解析技术在处理复杂文档时仍存在显著缺陷。特别是在高信息密度、多栏布局、图文混排、嵌套表格等复杂场景下,传统方法普遍存在阅读顺序错误、表格结构还原不完整、公式识别错误等问题,严重影响了知识提取的准确性与可用性。
基于上述问题,数据技术及产品团队提出了Logics-Parsing——一个强大的开源文档解析模型。该模型基于Qwen2.5-VL架构,通过在监督微调中融入化学式、手写汉字等多样化数据类型,进一步提升了模型在文档解析领域的通用性。此外,该模型引入精心设计的奖励机制,以优化复杂布局分析和阅读顺序推断。
Logics-Parsing可以轻松理解复杂排版,在保留自然的阅读顺序的同时,精准提取文字、表格、公式、手写字、化学分子式等内容,将PDF或图片转化为qwen-html或mathpix-markdow格式,解决文档解析作为AI应用落地的"最后一公里"难题。团队在自建评测集上验证了Logics-Parsing模型在多种文档分析场景下的SOTA性能,该评测集专为评估模型在STEM学科文档和复杂排版的文档上的解析能力而设计,后续也会开源。
项目主页:
https://logics.alibaba-inc.com/parsing/
Demo地址:
https://www.modelscope.cn/studios/Alibaba-DT/Logics-Parsing/summary
Github:
https://github.com/alibaba/Logics-Parsing
核心亮点
轻松实现端到端处理
- 端到端模型架构无需多阶段流水线处理,从文档图像一步到位生成结构化输出
- 全局优化,在处理具有挑战性的布局的文档时表现优秀
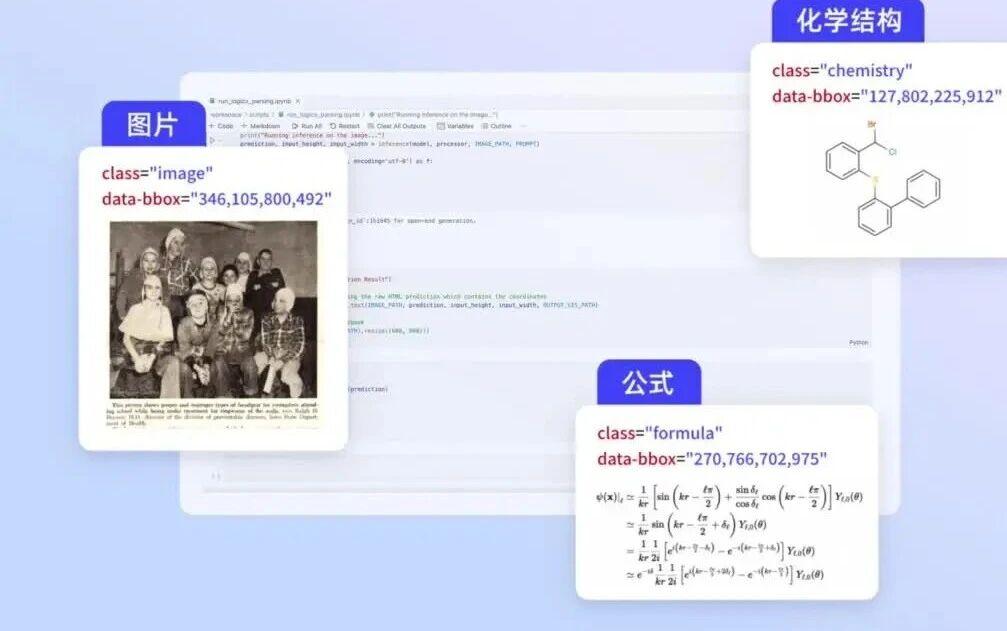
先进的内容元素识别能力
- 准确识别和结构化复杂内容,包括精确的科学公式、手写字等
- 智能识别化学结构,并可将其表示为标准的 SMILES 格式

丰富的结构化输出
- 生成 Qwen HTML 来表示文档,保留其逻辑结构和阅读顺序
- 每个内容块(如段落、表格、图片、公式)都会被标记上其类别、边界框坐标和OCR 内容
- 自动识别并过滤掉页眉、页脚等无关元素,仅关注核心内容
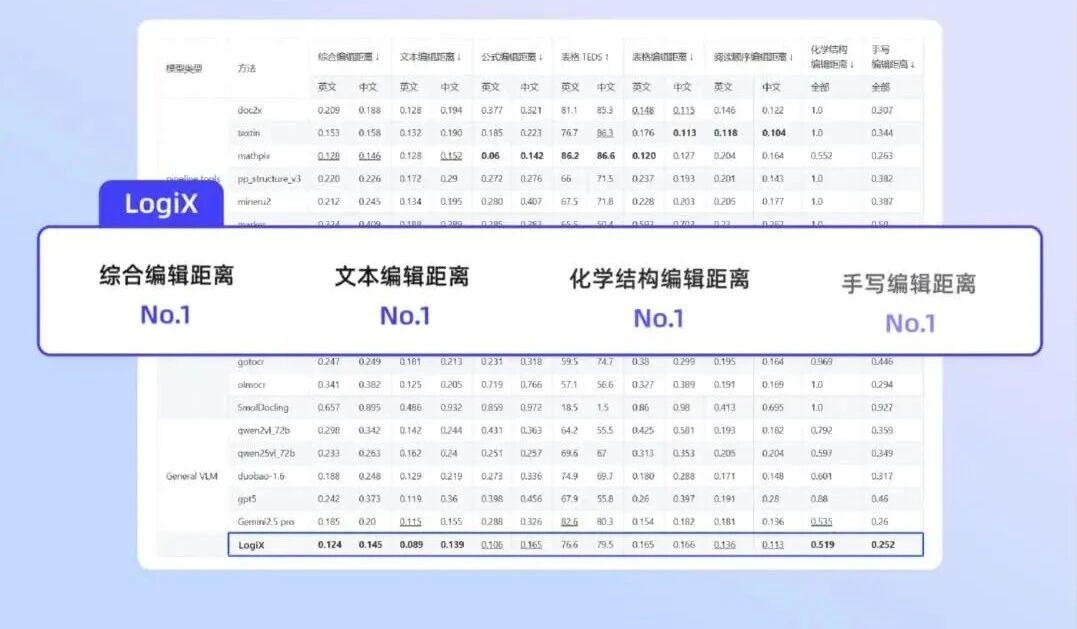
业界领先的性能表现 (SOTA)
- 该产品在团队自建的PDF解析综合评测集上取得了业界最佳(SOTA) 的结果
- 该评测集专为评估模型在 STEM 学科文档和复杂排版的文档上的解析能力而设计
实战案例
- 数学公式复现:
实现复杂数学符号的语义级识别,精确复现上下标、运算符等元素的空间结构关系,确保复杂公式的语义完整性和格式还原度。


- 化学分子式还原:
精准解析原子连接拓扑与化学键类型,完整还原环状结构、官能团等特征的空间排布关系,支持转换输出为SMILES表达式。

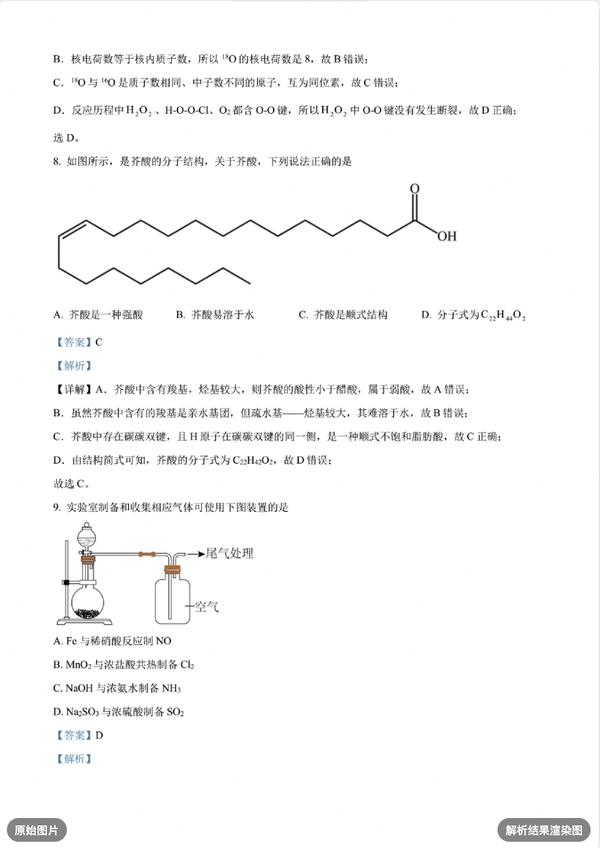
- 复杂表格解析:
保留合并单元格,保持行列对应关系,输出结构化表格数据,避免字符粘连及错行等问题,可直接用于数据分析与可视化处理。
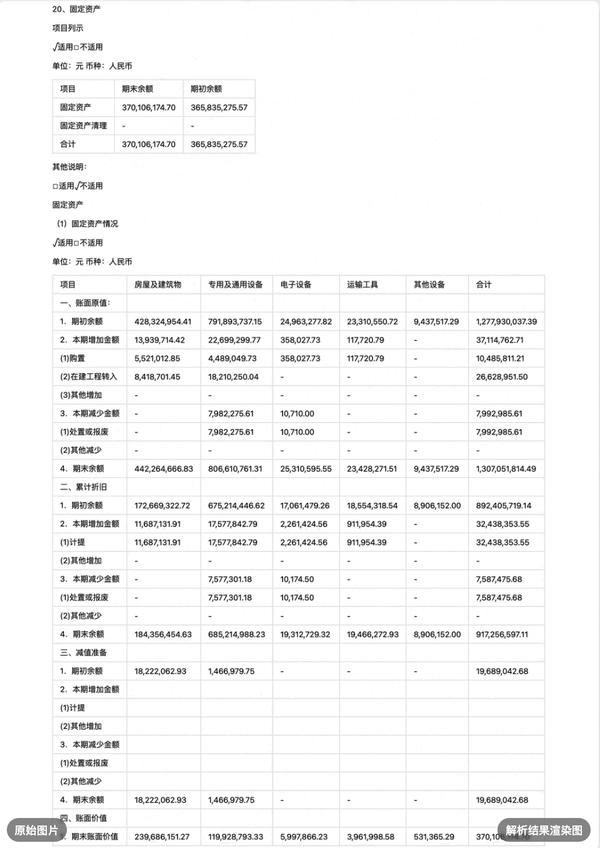
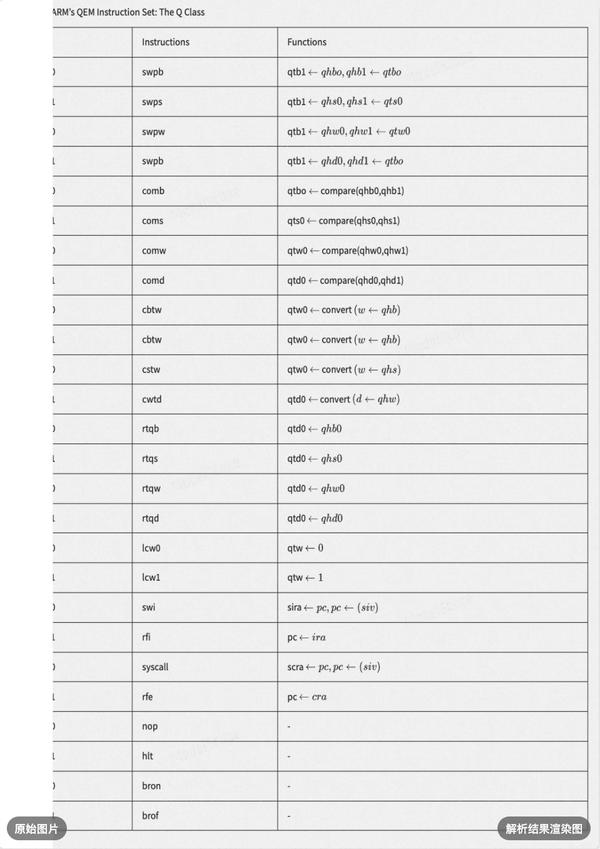
- 手写文字识别:
有效识别连笔字和个性化书写变体,支持印刷体与手写体混合识别,保留原始段落结构,适用于试卷批改、课堂笔记等典型场景。


ModelScope上在线体验
目前,该产品已上线ModelScope魔搭社区,面向所有用户开放体验。
产品地址🔗:
https://www.modelscope.cn/studios/Alibaba-DT/Logics-Parsing/summary
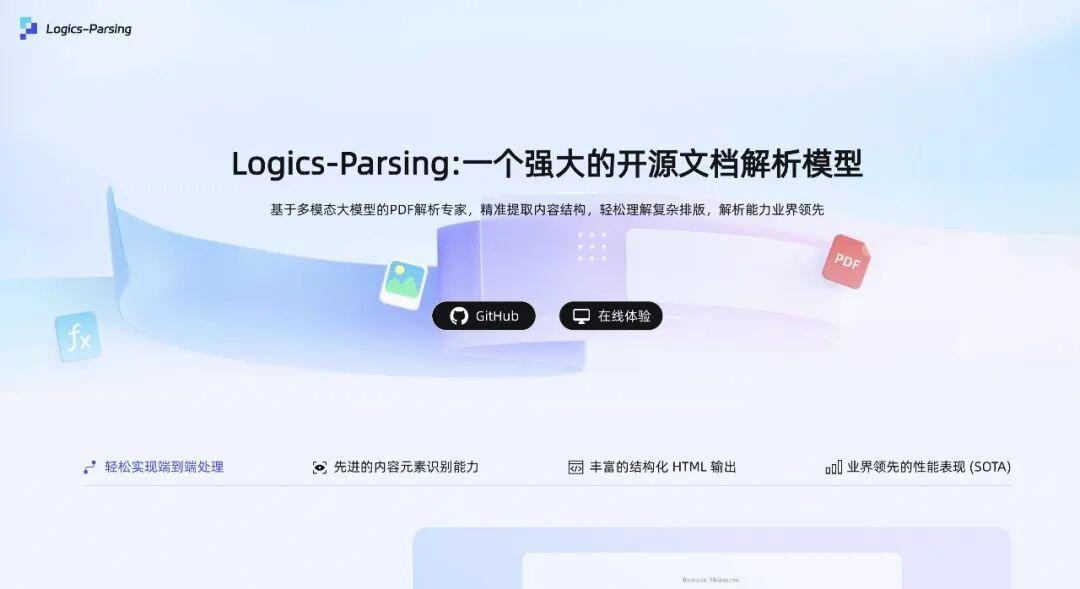
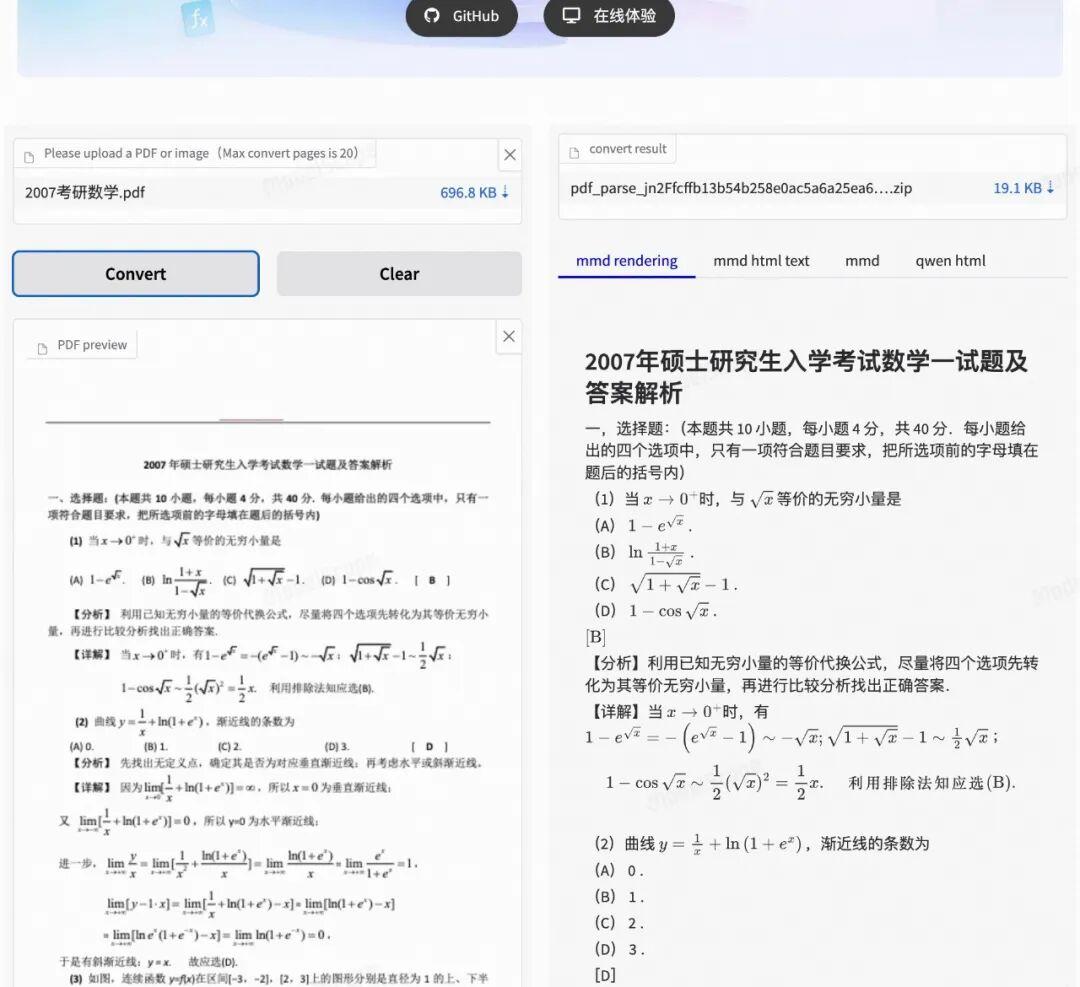
初次使用时,用户可直接进入产品首页点击“在线体验”按钮,系统已内置英文数学论文、化学试卷等多份不同类型pdf、png格式的样例模版作为参考,选择【Examples】中的任意样例后点击“Convert”即可开始解析,整个过程无需注册或上传文件,帮助用户快速熟悉流程,验证解析效果。
解析结果采用双栏可视化界面,左侧呈现原始文档,右侧实时显示渲染结果,并展示进度及耗时,方便校验内容,确保解析质量。输出格式支持qwen-html或mathpix-markdow解析格式,满足不同开发场景需求。
Github查看
用户现可前往GitHub获取Logics-Parsing模型及推理代码,如需了解更多细节,请参阅团队发布的技术报告。开源项目持续更新维护,欢迎开发者社区共同参与技术迭代。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献959条内容
已为社区贡献959条内容

所有评论(0)