
SkyJM-Gen 重磅开源:让文生图裁判模型"自己写打分细则",效果登顶专用裁判模型
SkyJM-Gen (RubricRM-Gen)是一款面向文生图(Text-to-Image)的生成式裁判模型,基于 Qwen3.5训练。模型在推理过程中会先针对每条 prompt 动态生成一份评分 Rubric(评估维度 + 权重 + 分级标准),再据此为两张候选图像逐维打分、加权聚合得出偏好。
在两个公开基准 MMRB2 / GenAI-Bench 和私有基准 GenAI-Bench-Verified 上,SkyJM-Gen-9B 全面领先所有同期开源专用奖励模型(HPSv2、PickScore、HPSv3、UnifiedReward、UnifiedReward-Think、UnifiedReward-Flex),与顶级闭源 MLLM 评审(如 Gemini 3.1 Pro)相当甚至持平。
🔥 关键结果速览
与其他开源模型 baseline 相比,SkyJM-Gen-9B 在三个 benchmark 上分别提升 +2.8 / +0.7 / +0.3 分。
| 模型 | MMRB2 | GenAI-Bench | GenAI-Bench-Verified |
| HPSv3 | 60.2 | 70.9 | 81.0 |
| UnifiedReward-Think-9B | 65.5 | 72.8 | 81.7 |
| UnifiedReward-Flex-8B | 69.2 | 73.4 | 84.2 |
| SkyJM-Gen-4B(Ours) | 70.5 | 73.2 | 83.1 |
| SkyJM-Gen-9B(Ours) | 72.0 | 74.1 | 84.5 |
开源地址:
- Github:https://github.com/SKYLENAGE-AI/SKYLENAGE-JUDGER
- modelscope:https://www.modelscope.cn/collections/SKYLENAGE/SkyJM
为什么要做“动态 Rubric”?
文生图奖励模型大致经历了三代:
- CLIP 类指标(如 CLIPScore):高效但对复杂语义、组合关系、推理类 prompt 不敏感;
- 偏好打分模型(HPSv2、PickScore、HPSv3、ImageReward、PickAPic 等):在大规模人类偏好数据上训练,但接口仍然是一个标量分数,好就是好、差就是差,缺乏"为什么";
- 多模态判别 / 推理模型(如 UnifiedReward、UnifiedReward-Think):用 MLLM 输出一段评估推理,但评估维度通常是预先固定的,不同类型的 prompt 被强制按同一套维度打分。
现存问题:不同的指令本应有不同的评估重点:
- "一张写实人像,傍晚光线" → 看人脸结构、光影质感、皮肤细节;
- "一张赛博朋克风格的霓虹街景" → 看风格统一性、构图、氛围;
- "Logo: 写一个反向的 R 字" → 看文字渲染、几何精度,连人脸结构都不该出现在评分维度里。
把所有 prompt 都塞进同一个固定打分模板,本身就是一种"评估失配"。
SkyJM-Gen 的核心思路:让模型自己根据指令"先写打分细则,再打分"。
动态 Rubric 范式:从"标量分"到"可解释偏好"
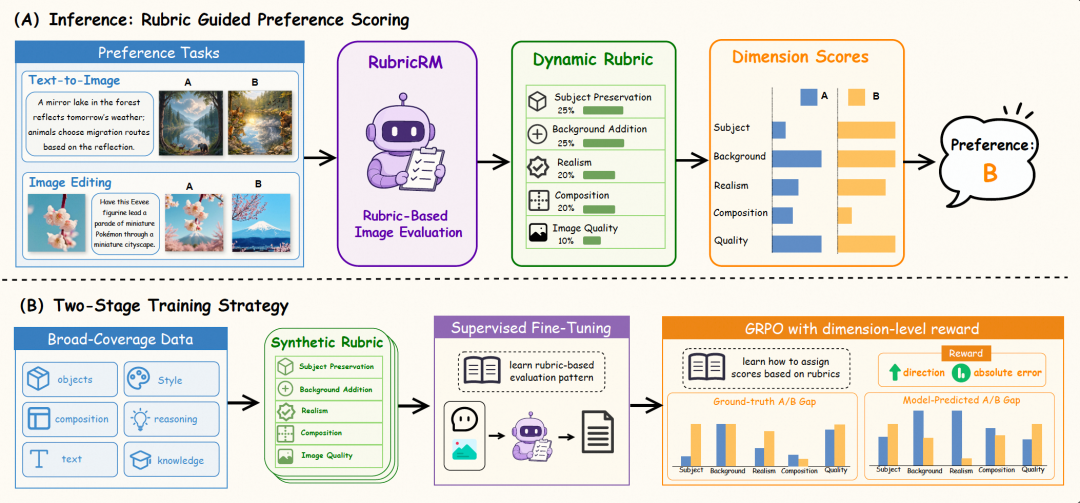
模型的单次前向推理会依次产出:

模型输出的最终偏好结果是通过比较S(I_A) 与 S(I_B) 的大小获得的。所有结果都是结构化的分数,可以详细查看模型的打分逻辑。
训练数据:覆盖 6 大类 42 子类
训练数据统计
| 指标 | 数值 |
| 总样本对 | 31,835 |
| SFT / RL 拆分 | 16,835 / 15,000 |
| 一级 / 二级类目数 | 6 / 42 |
| 平均标签数 | 3.3 |
| 多标签样本占比 | 94.9% |
| 平均 Rubric 维度数 | 3.9 |
| A / B 偏好比 | 51.6 / 48.4 |
数据来源及构建方式
- 公开数据:HPD v3、Open Image Preferences(OIP)、EvalMuse-40K;
- 长尾数据合成:分析数据后发现 Text Rendering(6.5%)、Logical Reasoning(9.0%)、World Knowledge(15.8%)等类目在公开数据中偏少。针对长尾数据,我们首先使用 DeepSeek-V3.2 合成了一批 prompt, 然后由人工筛选其中的高质量prompt,最后再用 10 个图像生成模型(包括 GPT-Image、Gemini-3.1-Pro、Seedream-5.0、Wan-2.6 等)渲染候选图;
- 专家三人评审:每张图按 10 分制独立打分,仅保留分差 > 5 且三人一致的样本对,确保偏好信号清晰。
Rubric 轨迹合成:用人类偏好锚定teacher模型
为了既有结构化的 Rubric 轨迹,又不被teacher模型自身的偏好偏置污染,我们采用偏好标签条件下的轨迹合成:
- teacher模型:Gemini 3.1 Pro;
- 合成时把人类偏好标签 y_j 一并喂给teacher模型,让它输出"任务意图分析 + 维度 & 权重 + 分级标准 + 逐维打分"五段式轨迹;
- 结构化校验:维度齐全、分数在 [0,4]、权重和 = 100%;
- 方向一致性校验:如果老师轨迹的加权总分与人类偏好方向矛盾,整条样本丢弃。
这样teacher模型不再是"独立的偏好标注员",而是把人类偏好翻译成结构化 Rubric的编排器。
两阶段训练:SFT 立"范式",GRPO 校"刻度"
Stage 1:Rubric Trajectory SFT — 学会"先写细则再打分"
输入 (prompt, image_A, image_B),目标轨迹是teacher模型合成的完整结构化 Rubric。模型要同时掌握:
- 拆解指令意图;
- 选择合适的维度并给权重;
- 为每个维度写出 0–4 分的分级标准;
- 输出逐维打分与最终偏好。
Stage 2:维度级 GRPO — 让"维度上的偏好"也对齐
只判断最终偏好的奖励信号过于稀疏:两个 trajectory 哪怕维度打分一塌糊涂,只要最后选对了 A/B,最终奖励都是一样的。因此我们把奖励下沉到维度级。
为了让 rollout 的维度能与参考 trajectory 一一对应,我们在训练时固定 Rubric 部分(推理阶段仍由模型端到端生成 Rubric):
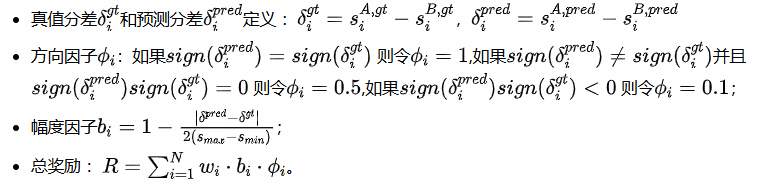
上述公式这意味着不同的情况给予不同程度的惩罚,这种方案优先考虑方向是否正确,然后再奖励对分数差异的精确逼近。
实验结果:4B 已超越所有同级 baseline,9B 全面登顶
文生图benchmark上的结果
| 模型 | MMRB2 | GenAI-Bench | GenAI-Bench-Verified |
| 闭源 MLLM 裁判 | |||
| Claude Sonnet 4.6 | 70.8 | 65.8 | 75.3 |
| GPT-5.4 | 67.5 | 64.2 | 74.2 |
| Gemini 2.5 Pro | 70.5 | 67.8 | 77.4 |
| Gemini 3.1 Pro | 74.4 | 73.9 | 84.8 |
| 开源 MLLM 裁判 | |||
| Qwen3-VL-8B | 61.2 | 63.3 | 72.5 |
| Qwen3-VL-235B-A22B | 66.6 | 61.5 | 69.7 |
| Qwen3.5-9B | 66.3 | 63.3 | 70.7 |
| Qwen3.5-397B-A17B | 72.7 | 66.2 | 77.0 |
| 专用奖励模型 | |||
| HPSv2 | 55.0 | 68.8 | 78.1 |
| PickScore | 57.6 | 70.0 | 79.2 |
| HPSv3 | 60.2 | 70.9 | 81.0 |
| UnifiedReward-9B | 57.9 | 69.2 | 72.8 |
| UnifiedReward-Think-9B | 65.5 | 72.8 | 81.7 |
| UnifiedReward-Flex-8B | 69.2 | 73.4 | 84.2 |
| 🟢 SkyJM-Gen-4B(Ours) | 70.5 | 73.2 | 83.1 |
| 🟢 SkyJM-Gen-9B(Ours) | 72.0 | 74.1 | 84.5 |
亮点:
- 9B 模型在三个 benchmark 上全部位列专用奖励模型第一,相对最强 baseline UnifiedReward-Flex-8B 提升 +2.8 / +0.7 / +0.3 分;
- 4B 模型也已在 MMRB2 上超过最强 baseline,说明 Rubric 范式能让小模型把容量花在更有效的地方;
- 在 GenAI-Bench-Verified 上,SkyJM-Gen-9B(84.5)几乎与 Gemini 3.1 Pro(84.8)持平,但参数量小了一个数量级。
两阶段消融:SFT 立范式,RL 稳定再上一台阶
| 配置 | MMRB2 | GenAI-Bench | GenAI-Bench-Verified |
| Qwen3.5-4B(base) | 63.3 | 61.9 | 69.7 |
| + SFT | 70.1 ↑6.8 | 72.0 ↑10.1 | 82.9 ↑13.2 |
| + RL | 70.5 ↑0.4 | 73.2 ↑1.2 | 83.1 ↑0.2 |
| Qwen3.5-9B(base) | 66.9 | 63.4 | 72.5 |
| + SFT | 70.3 ↑3.4 | 73.0 ↑9.6 | 83.2 ↑10.7 |
| + RL | 72.0 ↑1.7 | 74.1 ↑1.1 | 84.5 ↑1.3 |
Rubric SFT 阶段贡献了绝大部分性能提升,这进一步说明:让模型学会"先写细则再打分"这件事本身,比只用偏好标签做监督更关键。维度级 GRPO 在此基础上对刻度进行校准。
Label-only vs Rubric-based SFT
我们把 Rubric 轨迹换成只用偏好标签的标准 SFT,结果显示:在 4B/9B 两个 backbone 上,去掉 Rubric 监督会让 MMRB2 / GenAI-Bench / GenAI-Bench-Verified 一致下降 1.9–5.1 分。收益不是来自"看了更多数据",而是来自"学会了 Rubric 这套评估范式"。
可解释性 Case:Rubric 把判断过程"摊开来"
Prompt:A cranberry bog flooded for harvest with visible red berries, featuring geese flying in V-shaped flocks during autumn.
Image A

Image B

模型对这条 prompt 自动生成的 Rubric 与逐维打分(节选):
- Prompt Adherence (30%):A 包含红色蔓越莓、V 字形雁阵、秋日氛围;B 雁群非 V 字、"flooded" 渲染成奇怪的横向条纹 → A 4/4,B 2/4
- Visual Realism & Detail (30%):A 浆果质感、雁的剪影自然;B 浆果像低分辨率重复贴图、雁的翅膀畸变 → A 4/4,B 1/4
- Composition & Aesthetics (20%):A 透视与秋色对比好;B 构图扁平、横向条带突兀 → A 4/4,B 1/4
- Logical Consistency (20%):A 浆果合理漂浮在水面;B 出现"水上散步"的雁等违反物理的元素 → A 4/4,B 0/4
加权总分:A = 4.00,B = 1.10 → 偏好 A。
这就是 Rubric 范式的价值:你不再被动接受"A 比 B 好 0.3 分",而是看到模型究竟在哪些维度做了什么样的判断,模型输出结果可被审查、可被反驳、可被复用为下游 RL 的 dense reward。
本地部署
环境安装:
git clone https://github.com/SKYLENAGE-AI/SKYLENAGE-JUDGER
cd SKYLENAGE-JUDGER
uv venv .venv --python 3.11
source .venv/bin/activate
uv pip install -r requirements.txt
# For vllm backend
uv pip install "vllm>=0.19.0"模型下载:
modelscope download --model SKYLENAGE/SkyJM-Gen-4B --local_dir SKYLENAGE/SkyJM-Gen-4B文生图的评估(4B模型):
# Text-to-image evaluation with 4B model
python run_inference.py \
--judge SkyJM-Gen-4B \
--model-path SKYLENAGE/SkyJM-Gen-4B \
--backend vllm \
--input t2i_data.json \
--output result.jsonl \
--tensor-parallel-size 2图像编辑评估(4B模型):
# Image editing evaluation with 4B model
python run_inference.py \
--judge SkyJM-Edit-4B \
--model-path SKYLENAGE/SkyJM-Gen-4B \
--backend transformers \
--input edit_data.json \
--output result.jsonl 晓天衡宇·评测社区
https://skylenage.net/sla/home

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献1001条内容
已为社区贡献1001条内容

所有评论(0)