
高德开源 DreamX-World 1.0:通用交互式世界模型,16 FPS 实时生成 1 分钟长视频
高德 DreamX 团队(AMAP-ML)开源 DreamX-World——一个面向交互式世界模拟的通用世界模型。它能生成多样化、高保真的世界,用户可通过键盘风格的相机动作与事件提示,对生成的世界进行探索、控制和变换,最长可在 16 FPS 下流式生成约 1 分钟的可交互视频。
📎0bc3eyaeoaaasealgrzqtfvfajwdi4taarya.f10002.mp4

本次开源包含两个变体:
DreamX-World-5B 是长时程自回归变体,基于 Wan2.2-TI2V-5B 构建,可根据输入图像、文本提示和键盘风格的相机动作指令生成视频;它采用分块因果自回归推理(chunk-wise causal autoregressive inference)并结合 KV 缓存,使长时程生成成为可能(16 FPS、约 1 分钟)。
DreamX-World-5B-Cam 则生成 24 FPS 的 5 秒视频,最长支持 7.5 秒。
开源地址:
- DreamX-World-5B:https://modelscope.cn/models/GD-ML/DreamX-World-5B
- DreamX-World-5B-Cam:https://modelscope.cn/models/GD-ML/DreamX-World-5B-Cam
- GitHub 仓库:
https://github.com/AMAP-ML/DreamX-World - Project Page:
https://dreamx-world.github.io
生成效果
长时程视频生成(Long-Horizon Video Generation)
DreamX-World 采用几何引导的记忆检索,将非局部的视觉证据重新引入生成过程。当相机重新回到此前观测过的区域时,检索到的记忆帧有助于保持场景布局、物体身份与局部外观,使长时程探索更具持续性与空间一致性。
📎0b2eemaoeaaariakzebtmfvfai6d4irqbyqa.f10002.mp4

在真实世界中导航与探索(Navigate and Explore Realistic Worlds)
DreamX-World 支持高保真、精确可控、动态丰富的交互式探索,并能在广泛的真实环境中泛化,包括室内场景、城市街道、自然景观和建筑空间。模型能够准确响应细粒度的动作输入,让用户或智能体以可控且符合物理规律的方式在生成环境中移动。
📎0bc3dmbqeaad24aeypbqvjvfgg6dainqgaqa.f10002.mp4

潜入梦境世界(Dive into Dream Worlds)
除真实环境外,DreamX-World 还释放了广阔的想象世界生成空间,支持奇幻世界、游戏化环境、科幻场景以及高度风格化的视觉领域,将世界生成从"仿真"延伸到"创造"。
📎0bc3cmaayaaa6qaefbjt45vfae6dbqjqadaa.f10002.mp4

第三人称视角生成(Generate in Third-Person View)
DreamX-World 同时支持沉浸式的第一人称交互与连贯的第三人称世界生成。除第一人称探索外,模型还能模拟第三人称体验——智能体在世界中移动,相机在空间与时间上始终保持连贯跟随。这一能力可支撑从动态户外穿行到游戏化角色控制的多种场景,并维持稳定的相机跟随、可控的智能体运动与连贯的场景演化。它对具身智能体、交互式仿真以及游戏化世界体验尤为重要。
📎0bc35iczsaaf5eanntrwvzvfl2wdthvalgia.f10002.mp4

可提示的世界事件(Promptable World Events)
除导航控制外,DreamX-World 还支持由提示驱动的世界事件,可动态改变所生成的环境。相比以往方法,DreamX-World 支持更灵活、可组合的事件生成,同时保持一致、可交互且时序连贯的世界演化。这一能力也为"从经验中学习"的智能体提供了坚实基础,使其能在动态环境中遭遇并适应突发情况。
- 单一事件(Single Event):
示例提示——接下来应该发生什么事件?"一场暴风雪来袭。"
📎0bc3s4craaafwiaf6brwvnvflf6dcclqkeaa.f10002.mp4

- 组合事件(Compositional Events):
示例提示——接下来应该发生什么事件?"一架 UFO 出现在头顶并射下激光,卷起一阵漫天飞舞的薰衣草花瓣。"
📎0bc33ycq2aafsyaeerjwwzvflxwdbxpakdia.f10002.mp4

DreamX-World 1.0 技术体系
DreamX-World 1.0 由五大核心技术构成,打通了从多源数据清洗、渐进式适配到实时流式推理的完整闭环(整体框架见图 1),按"数据引擎 → 高效相机控制 → 长程记忆持久化 → 自回归长视频训练 → 事件指令微调、强化学习与流式加速"的递进逻辑展开。
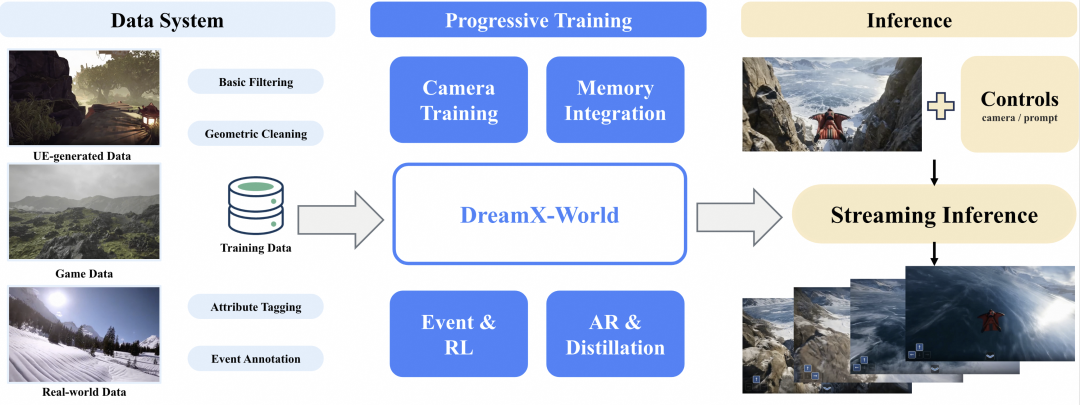
图1:DreamX-World 1.0 整体框架图
多源一体化数据引擎与清洗算法
构建通用的交互式世界模型,需要兼具多样视觉分布与精准几何/动作标注的视频底座 。然而,现实世界视频视觉丰富但缺乏高精度位姿,合成数据几何精确但泛化有限 。DreamX-World 设计了一套跨越三位一体的数据引擎:
在数据生成侧,团队在 Unreal Engine 5 中开发了双自主漫游引擎:
第一人称自由相机引擎利用 UE 的 NavMesh 导航组件自动探索空间,通过视角随机化、碰撞规避与卡死检测清洗高质量视轨;第三人称角色驱动引擎控制 Rigged 角色完成复杂寻路,相机以弹簧阻尼平滑跟踪,并自动记录角色世界坐标与键盘式动作向量(WASD/IJKL)。同时全面引入 SpatialVID、RealEstate10K 等海量真实与游戏数据,用 MegaSaM 在关键帧估计稀疏位姿并经球面线性插值(SLERP)稠密化,统一变换到 DreamX-World 标准相机坐标系。
所有视频流再经三阶段清洗与标注流水线:
- 基础过滤:基于 CLIP 嵌入的首尾帧余弦相似度丢弃低运动或画面完全静止的死帧,剔除带有黑边和多余文本的无效剪辑 。
- 几何异常剔除:自动化识别并剔除包含内参不一致、位移激增(Spikes)、垂直抖动、剧烈瞬时旋转的故障视轨 。
- 层级化实体标注:使用多模态模型为视频流打上美学分、运动强度、视觉风格等密集标签,并将场景严格切分为静态相机漫游(3D 空间)与相机+目标双运动(4D 时空)两大类别 。
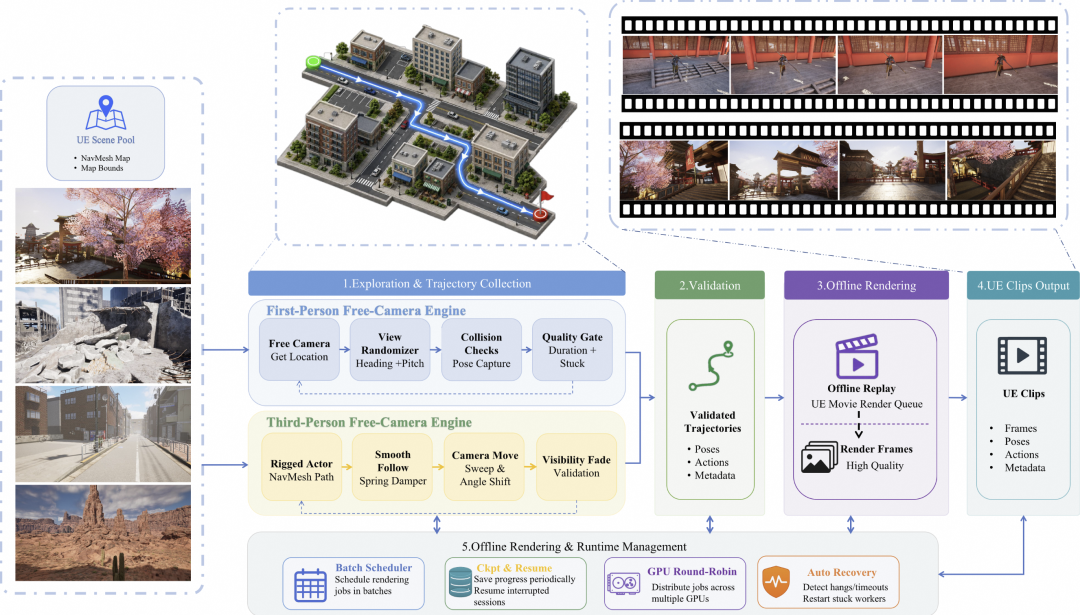
图2:数据构造流程图
高效几何相机控制 E-PROPE
要让模型顺从执行 6-DoF 相机运动,基础架构需引入投影位置编码(PROPE),但在每个 Transformer 块中塞入完整视锥投影注意力会让 DiT 计算成本骤增、推理延迟近乎翻倍。E-PROPE(Efficient PROPE)的核心见解是:相机轨迹控制主要依赖全局宏观的几何视空间相对关系,无需在满分辨率局部语义 Token 上做冗余计算。
具体地,对于包含 S 个视频 Token 的序列 X,E-PROPE 首先对其进行空间维度的下采样(Downsampling),并将通道降维到低维空间 d',得到缩减 Token 序列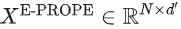 : 以 5 秒 720P 视频为例:
: 以 5 秒 720P 视频为例:
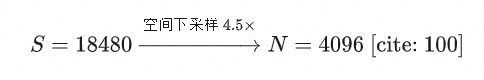
在此低阶空间中,模型仅应用空间几何的投影转换矩阵进行注意力计算(抛弃了冗余的标准旋转 RoPE 项,因为 DiT Backbone 的原生注意力已具备足够细粒度的时空归纳偏置):
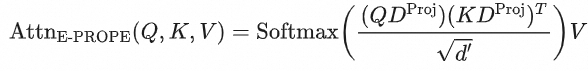
计算完成后,再通过上采样(Upsampling)模块将其残差无缝叠加回原版 DiT 注意力输出中 。在训练阶段,全量冻结 Wan2.2 的原有 backbone 参数,仅对 E-PROPE 模组的进行梯度回传 。
时空解耦的持久化场景记忆机制
自回归生成长视频时,早先画幅随滑窗滑出局部上下文后,模型便失去物理参照,相机调头或重访时极易"物是人非"。DreamX-World 设计了基于相机几何三维重叠度的非局部记忆检索算法 。输入至自回归 扩散模型的输入 Token 被构造为 :
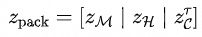

为了防止久远跨度的记忆帧打乱当前序列的时序建模,团队巧妙运用了 NTK-aware ROPE 缩放与 YaRN 随机化位置编码,对其强制附加了代表其原始生成时间点的时空锚定偏置 。
针对训练(参考帧来自干净 Ground-Truth)与推理(参考帧为模型自身生成、带预测微瑕)之间的曝光偏差,DreamX-World 采用残差循环扰动(Residual Recycling):
在训练去噪时,故意向作为条件的 z_{\mathcal{M}} 记忆 Token 注入特定的预测误差。这样可以逼迫模型建立自适应的过滤机制——当记忆精准时主动锚定记忆;当记忆出现显式预测错误时,能丝滑回撤并借助学到的世界先验保持画面稳定 。
带相机控制的自回归长视频生成训练
为实现少步数(Few-step)长视频生成,DreamX-World 将双向基础模型蒸馏为可基于已生成历史流式推理的自回归生成器。团队先在大规模高质量视频上用 Causal Forcing 训练少步数自回归模型,使其紧贴双向模型的原始视觉分布;随后引入 Infinity-RoPE 在长视频样本上微调,以支持更长上下文并缓解长视频常见的漂移、背景突变与指令/运动控制减弱。
在引入相机控制后,由于自回归过程采用分块(Chunk-wise)推理,在长序列上极易导致运动平滑度下降和相机可控性变差。为了攻克这一难题,团队针对性的修改了 DMD-forcing 训练流程。
- 时域窗口对齐:在长视频中采样出局部时域窗口,将带有相机控制的“学生模型”(Student Rollouts)与带有相机控制的“教师模型”在这些窗口内进行分布对齐。
- 图生视频(I2V)保真度增强:每个采样 DMD 窗口的第一帧潜在特征(Latent Frame)会通过 VAE 解码,并作为图像条件输入给教师模型,从而让教师模型能够在局部时域窗口内对自回归学生模型实施更准确的监督。
通过这一设计,DreamX-World 1.0 能够支持长达 1分钟 的流式稳定推理,并在跨分块生成中保持良好的相机控制能力与时空连贯性。
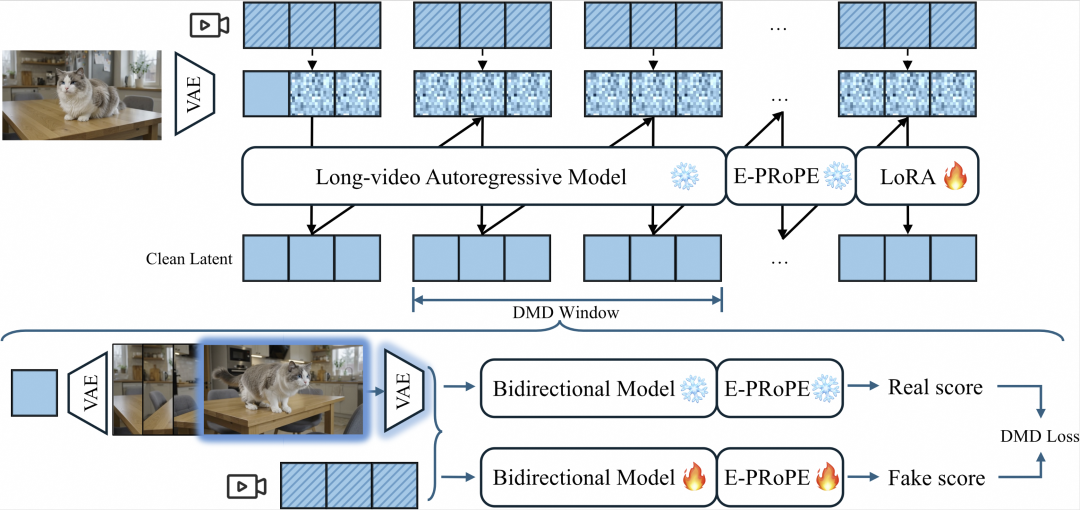
图3:DMD-forcing训练流程图
事件指令微调、强化学习与流式加速
一个真实的世界模型不仅相机能动,场景内部的物体更需要遵从人类指令发生物理演变(如“两车相撞”、“杯子碎裂”) 。DreamX-World引入了可组合层级事件指令微调 。利用构建的事件指令数据,团队在保持 Diffusion Transformer (DiT) 架构不变的前提下对其进行了全量微调:
- 文本条件接口注入:事件语义完全通过文本条件接口输入,结构化的事件指令被渲染为包含全局场景和逐个实体动态的自然语言 Prompt。
- 混合训练策略:在微调过程中,将事件指令样本与常规的非事件视频片段进行混合训练。这种做法在赋予模型对触发事件高度响应能力的同时,完美保留了其原有的通用世界生成能力。
- 严谨的梯度裁剪:采用保守的更新策略和严格的梯度裁剪(Gradient Clipping),以防止破坏模型预训练好的世界先验。
由于 aggressive 蒸馏(如 DMD 蒸馏)和长周期自回归微调往往会严重损伤大模型的视觉发散度、动态范围及相机响应敏感度 ,项目引入了最新的GRPO(Group Relative Policy Optimization)强化学习对齐。
团队设计了一套面向高动态世界仿真的导航感知风险敏感奖励函数(NARF, Navigation-Aware Risk-Sensitive Reward Function)。NARF 将世界模型的输出严格划分为三大质量反馈层级:

通过非对称的奖惩逻辑,显式教会模型“沉默远优于犯错”:在面临高度模棱两可或时空几何不可解的极端场景时,大模型会智能选择主动收敛或保持惯性,绝不冒险生成误导用户的几何色块 。
为了将世界模型推向工业级高并发落地,DreamX-World 在工程上实施了全栈联合优化 :
- 混精度 DiT 混合算子:对不敏感的长时记忆及事件 Prompt 文本编码全面应用 FP8/FP4 量化加速 。
- 残差深度重用(Residual Reuse):在自回归相邻帧的去噪迭代中,大幅度复用前序已经计算完毕的高阶时空特征,避免重复过 backbone 。
- 75% VAE 剪枝解码器:重构了计算卡脖子的 VAE 解码阶段,通过对高频空间残差通道进行 75% 的极化剪枝,直接榨干硬件效能 。
最终,在 8 卡 RTX 5090 组成的高性能分布式集群上,系统成功跑出了 16 FPS 的超实时超低延迟流式吞吐,标志着通用大模型交互式世界真正跨入工业可用门槛 !
📎0bc3rucfgaaeguabydbxjjvfjdodkogqiuya.f10002.mp4

📎0b2ewmaqeaabnyae3rrsozvfdm6dakzqcaqa.f10002.mp4

本地部署
环境与代码安装:
git clone https://github.com/AMAP-ML/DreamX-World.git
cd DreamX-World
pip install -r requirements.txt
模型下载:
modelscope download --model GD-ML/DreamX-World-5B --local_dir GD-ML/DreamX-World-5B
准备输入json:
{
"image_path": "./demo/your_image.png",
"caption": "Style: Photorealistic. A description of the scene...",
"action_seq": ["w", "wj"],
"action_speed_list": [4, 6]
}
然后运行脚本
sh inference_dreamx_5b.sh
直达模型

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐

 0
0 0
0- 0



 已为社区贡献997条内容
已为社区贡献997条内容

所有评论(0)