
阶跃开源 Step 3.7 Flash:面向生产级 Agent 的高效率 Flash 模型
阶跃星辰发布并开源Step 3.7 Flash,一款面向Agent生产化阶段的多模态Flash模型。采用稀疏MoE架构,总参数196B+1.8B(ViT),激活参数仅11B,最高生成速度400 Tokens/s。围绕Agent、Coding、Search与多模态工作流进行系统优化,支持云端和本地部署,已适配Claude Code、OpenClaw、Hermes Agent等主流Agent框架,现已上架魔搭社区。
开源地址:
- ModelScope:
https://modelscope.cn/models/stepfun-ai/Step-3.7-Flash
- GitHub:
https://github.com/stepfun-ai/Step-3.7-Flash
- Model Page:
https://static.stepfun.com/blog/step-3.7-flash/
核心特性
下一阶段的模型竞争,不只是峰值智能,而是可规模化的高效智能。随着 Agent 从 Demo 走向真实生产环境,模型不只要回答问题,更要理解复杂输入、主动搜索信息、稳定调用工具,并在多轮任务中持续保持执行轨迹。
这对底层基础模型提出了完全不同的要求,同时,模型能力的关键指标正在发生变化。Step 3.7 Flash 正是为此而来。
面向生产级 Agent 优化的四大能力:
- 原生多模态理解与执行:原生理解 UI、图表、文档、图片和应用界面,将复杂视觉信息转化为结构化结果、代码生成和可执行任务。
- 联网与视觉搜索增强:强化联网检索与图像搜索,使模型在开放信息环境中跨文本与图像主动获取并交叉比对多源证据。
- 高可靠工具调用与编排:在长程多轮 Agent 工作流中稳定调用 API、浏览器、终端、Office 工具和外部系统,保持任务轨迹一致,降低跑偏和执行失败。
- Agent 生态兼容优化:针对主流 Agent 框架(Claude Code / KiloCode / RooCode / OpenCode / Hermes Agent / OpenClaw 等)、MCP/Skills 等工具调用协议和开发链路进行兼容优化,降低模型接入和工作流编排成本。

柱状图中左一为 Step 3.7 Flash、左二为 Step 3.5 Flash(Multimodal 除外)
同时,Step 3.7 Flash 也在适配 OpenRouter、ZenMux 等海外模型聚合与开发者平台,相关体验入口陆续开放。
多模:原生多模态理解与执行
Step 3.7 Flash 具备原生多模态理解与搜索能力,能够在真实环境中边看、边查、边验证信息。
模型支持理解 UI、图表、文档、图片与应用界面,并可将复杂视觉内容转化为结构化结果与可执行任务。在面对复杂视觉问题时,模型还能够自主裁剪、放大、重读图像,并在信息不确定时主动发起搜索进行交叉验证。
通过将视觉感知、搜索与推理过程深度结合,Step 3.7 Flash 在 SimpleVQA (Search)、V* (Python) 等复杂视觉任务 Benchmark 上,展现出媲美更大规模旗舰模型的能力表现。
Case 1

用户输入“如何起飞”指令后,模型可自动框选驾驶舱范围,识别仪表、按钮等视觉信息,理解驾驶舱中的关键信息与操作逻辑,并生成“如何起飞”的分步骤教程,展示复杂界面理解与任务引导能力(黄色鼠标及其行动为模型自动生成)。
Case 2
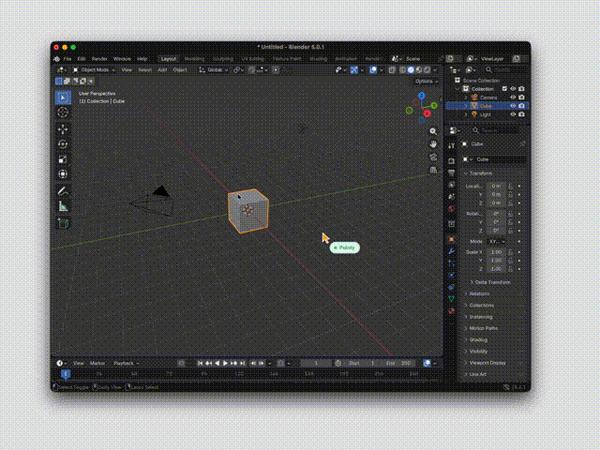
用户输入“怎么删除这个方块”指令,模型可自动框选 Photoshop 界面中,开始理解图层、工具栏与当前编辑状态,并给出删除画面中指定方块的具体操作步骤,展示对复杂专业软件界面与多步骤编辑任务的理解能力(黄色鼠标及其行动为模型自动生成)。
Case 3
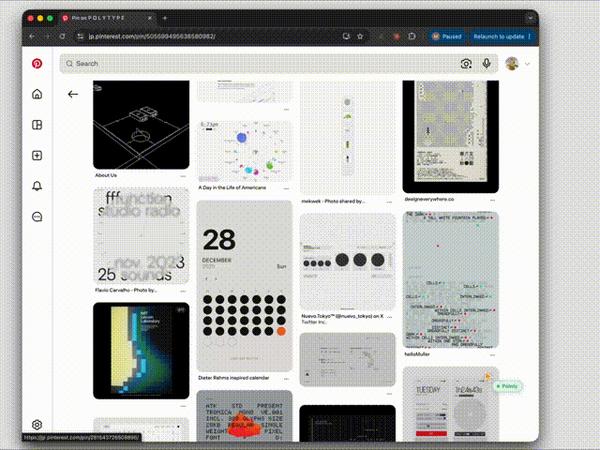
用户输入“这些设计有什么有趣之处”指令,模型可自动框选应用界面,开始识别信息内容、理解不同图片设计,最终生成专业分析(黄色鼠标及其行动为模型自动生成)。
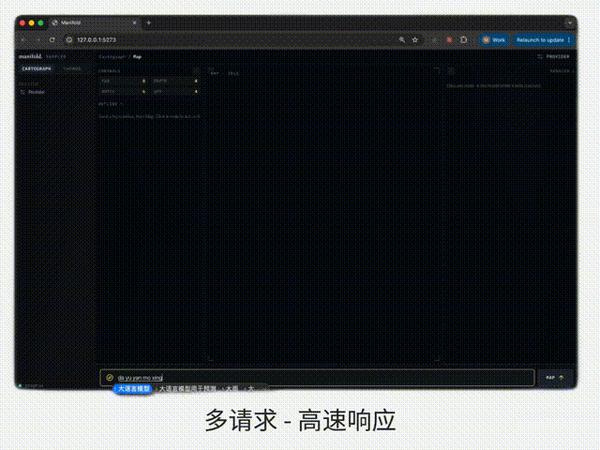
快速:单请求最高 400 TPS
Step 3.7 Flash 采用稀疏 MoE 架构,总参数 196B+1.8B(ViT)、激活参数仅 11B ,在模型能力、推理成本与执行效率之间实现更优平衡。
最高生成速度可达 400 Tokens/s,适合高频、多轮、低等待的 Agent 应用。 尤其适用于高频 Agent、Coding Agent、Search Agent、多模态 Agent 和企业知识工作 Agent。这意味着在同样单位时间内,Step 3.7 Flash 可以多看、多查、多想,迭代次数越多,结果越准确。
Case 1
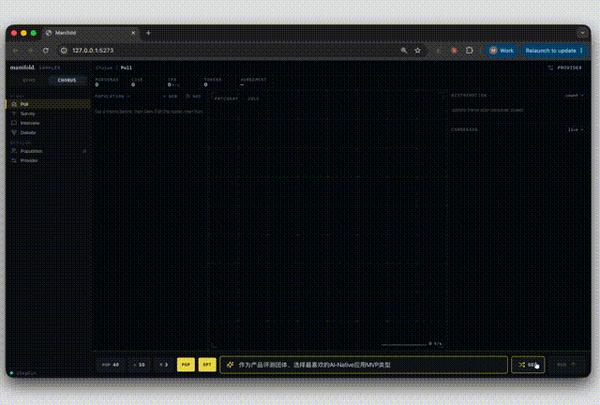
视频详情
构建 Agent 集群,让 40 个不同身份的虚拟 persona 扮演产品评测团,对一个产品问题进行并行判断,然后实时汇总它们对 5 个 MVP 方向的偏好。
Case 2
Agent 并行实时构建大型可互动知识图谱
好用:高可靠工具调用与编排
Step 3.7 Flash 在多轮 Agent 工作流中稳定调用 API、浏览器、终端、Office 和外部系统,保持任务轨迹一致,降低跑偏和执行失败。已适配Claude Code、OpenClaw、Hermes Agent、Kilo Code等主流Agent框架,支持MCP/Skills等工具调用协议,同时支持个人工作站本地部署
| 基准 | 得分 | 说明 |
| Toolathlon | 49.5% | 多工具协同 |
| ClawEval-1.1 | 67.1% | 真实环境自主任务执行 |
| GDPval | 45.8% | 横跨44种职业 |
| τ²-bench Telecom | >98% | 低/中/高三档推理难度 |
模型体验与部署
魔搭免费体验
在魔搭社区模型页面 APl-Inference 即可免费体验Step 3.7 Flash,无需配置环境:
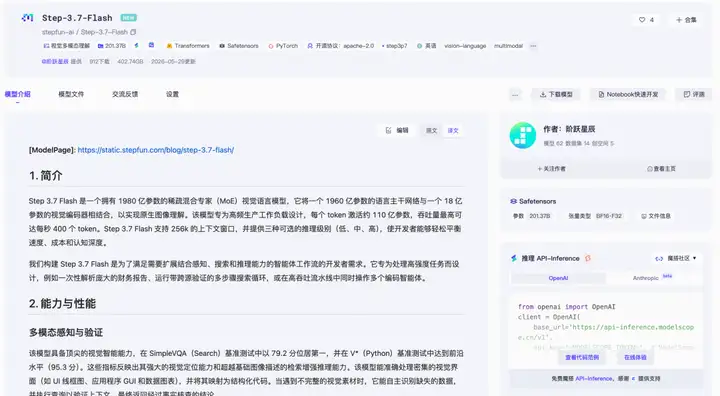
API调用
Step 3.7 Flash兼容OpenAI接口,国内和海外平台使用不同的base_url:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["STEP_API_KEY"],
base_url="https://api.stepfun.com/v1", # 海外请使用 https://api.stepfun.ai/v1
)
completion = client.chat.completions.create(
model="step-3.7-flash",
messages=[
{"role": "system", "content": "You are an AI assistant provided by StepFun."},
{"role": "user", "content": "Introduce StepFun's artificial intelligence capabilities."},
],
)
print(completion)
支持文本+图像多模态输入,在messages中传入
image_url
类型即可。vLLM部署
推荐使用StepFun提供的预构建Docker镜像:
docker pull vllm/vllm-openai:stepfun37
VLLM_USE_MODELSCOPE=true vllm serve stepfun-ai/Step-3.7-Flash \
--served-model-name step3p7-flash \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--reasoning-parser step3p5 \
--enable-auto-tool-choice \
--tool-call-parser step3p5 \
--trust-remote-code
同时提供FP8和NVFP4量化版本,NVFP4版本可在4卡上运行。SGLang部署
docker pull lmsysorg/sglang:dev-step-3.7-flash
sglang serve --model-path stepfun-ai/Step-3.7-Flash \
--tp 8 \
--reasoning-parser step3p5 \
--tool-call-parser step3p5 \
--enable-multimodal \
--trust-remote-code \
--host 0.0.0.0 --port 8000
支持EAGLE推测解码加速,添加
--speculative-algorithm EAGLE --speculative-num-steps 3
即可启用。llama.cpp本地部署
提供Q4_K_S(111.5GB)、IQ4_XS(105GB)、Q3_K_L(102.5GB)三种GGUF量化版本,最低需要120GB统一内存(如Mac Studio、NVIDIA DGX Station)。
Transformers推理
from transformers import AutoProcessor, AutoModelForCausalLM
processor = AutoProcessor.from_pretrained(
"stepfun-ai/Step-3.7-Flash", trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
"stepfun-ai/Step-3.7-Flash",
device_map="auto", dtype="auto", trust_remote_code=True
)
messages = [{"role": "user", "content": [
{"type": "image", "url": "https://example.com/photo.jpg"},
{"type": "text", "text": "What is in this picture?"}
]}]
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_dict=True, return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=128, do_sample=False)
print(processor.decode(output[0][inputs.input_ids.shape[1]:], skip_special_tokens=True))
注意:需要
transformers >= 5.0
。Transformers方式适合功能验证,生产环境推荐使用vLLM或SGLang。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献1038条内容
已为社区贡献1038条内容

所有评论(0)