
面壁智能端侧双响开源:MiniCPM5-1B以1B打败2B,BitCPM-CANN释放6倍显存红利
面壁智能联合清华大学、OpenBMB开源社区,在端侧大模型开源周中连续发布两款模型。MiniCPM5-1B仅1B参数,在AA-Index上超越所有2B以下模型(包括Qwen3.5-2B),INT4量化后权重仅0.5GB,可跑在手机、浏览器甚至纯CPU环境上。BitCPM-CANN是完全基于华为昇腾端到端训练的1.58-bit三值大模型,覆盖0.5B/1B/3B/8B四个规格,相比BF16释放约6倍显存红利,能力保留率90%-97.2%。
开源地址:
- MiniCPM5:
https://modelscope.cn/collections/OpenBMB/MiniCPM5 - BitCPM-CANN:
https://modelscope.cn/collections/OpenBMB/BitCPM-CANN
MiniCPM5-1B:1B参数,2B以下AA榜单第一
MiniCPM5-1B再次刷新模型的智能密度上限:仅以1B参数规模,在AA-Index上超越了所有2B参数以下模型;相比3个月前发布的Qwen3.5-2B,MiniCPM5-1B不仅效果更优,参数量还减少了一半。
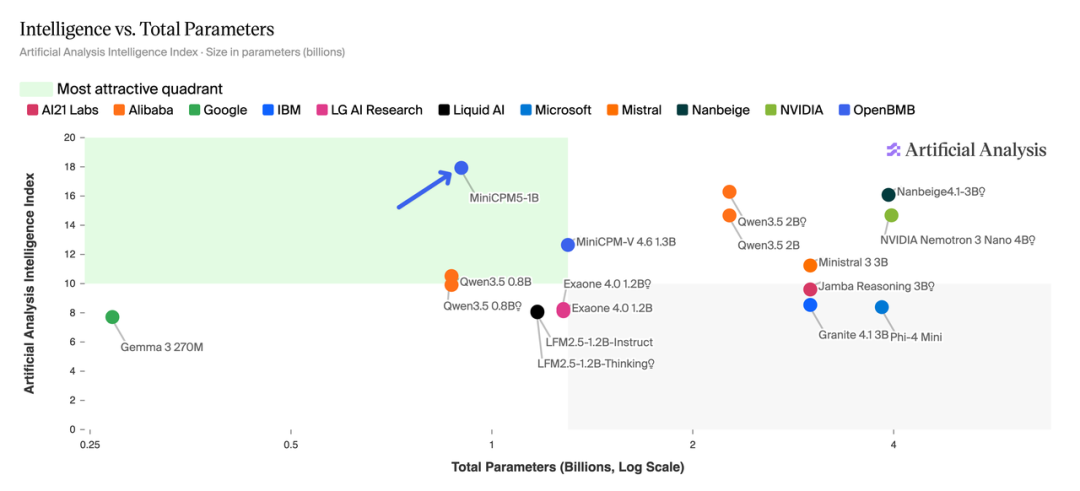
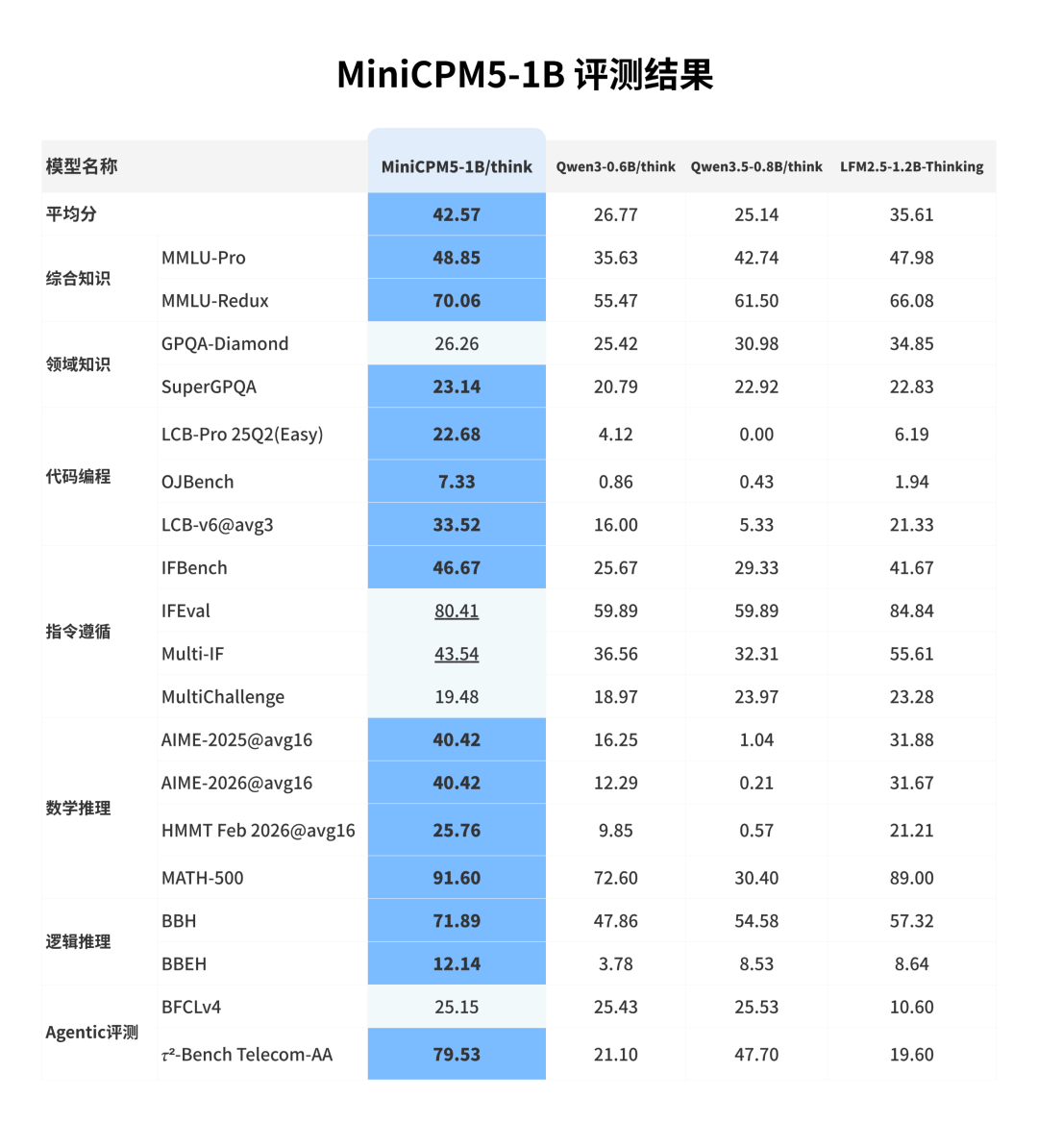
在知识、数学推理、代码推理、工具调用等维度上,MiniCPM5-1B全面超越Qwen3.5-0.8B、LFM2.5-1.2B-Thinking等同尺寸基座模型。在AA榜单上得分17.9,位于"小尺寸模型"榜单第一,超过Qwen3.5-2B(16.3分)。
这一结果进一步验证了持续观察到的密度定律:大模型的智能密度正在以约每3.5个月翻一番的速度持续提升。更小的模型,正在承载更高的智能密度。
高智能密度:数据决定模型的上限
1B模型要达到出色的性能,训练数据的质量比参数量更重要。
MiniCPM5-1B在训练过程中构建了一套分级数据治理体系,将预训练数据按照质量从低到高划分为L0至L4五个等级,每一级对应不同的清洗、筛选和质量控制标准。
在此基础上,研究团队针对三个关键语料方向开展了大规模的高质量预训练数据合成:
- 高知识密度中文网页语料
- 高知识密度英文网页语料
- 高质量数学合成语料
核心理念是:与其用海量低质数据灌出一个模型,不如用精选高密度数据养出一个模型。在1B参数规模下,每一条训练数据的质量都直接影响最终性能——这也是MiniCPM5-1B能够全面超越同级模型的关键原因之一。
高质量合成数据集Ultra-FineWeb-L3将随模型一起开源,供社区使用和研究。
AI制造AI
MiniCPM5-1B的Base Model版本由面壁智能自研的AI训练框架ForgeTrain在华为昇腾上预训练完成。
ForgeTrain是完全由AI编写的生产级大模型训练框架——全部代码由AI生成,人类工程师零代码介入。在H100上训练速度超越英伟达Megatron框架,比Megatron快了10%,相当于训练成本下降10%。
一个完全由AI编写的训练框架,训出了2B以下AA榜单排名第一的文本基座模型——这表明"AI制造AI"的递归自改进智能(RSI)不是设想,而是正在产出真实的、可验证的、性能领先的成果。
端侧普适:几乎所有设备都能跑
端侧模型的核心问题:用户手边的设备能不能跑?MiniCPM5-1B的答案是几乎都能。
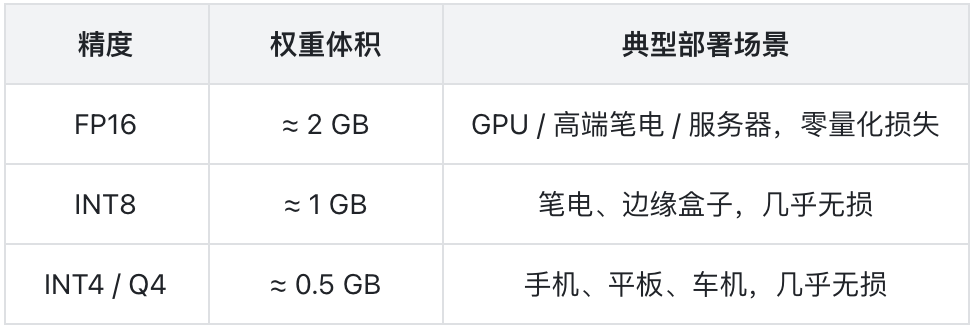
INT4量化后权重仅0.5GB,比一部短视频还小。运行环境广泛兼容:
- 有GPU:直接跑FP16,性能拉满
- 只有CPU:使用自研推理框架ArcLight(http://github.com/OpenBMB/ArcLight),专门为纯CPU环境做了深度优化,没有显卡也能流畅对话
- 不想配环境:MiniCPM5-1B可以直接在浏览器中运行,打开网页就能用,零安装零配置
主流框架全覆盖:支持SGLang、vLLM、llama.cpp、Ollama、Llama-Factory、ms-swift。此外还提供了配套的桌宠应用——1B参数也能驱动有趣的端侧应用。
BitCPM-CANN:6倍显存红利,打破端侧AI天花板
长期以来,内存的物理瓶颈——包括容量、带宽与成本——是大模型走向端侧设备时最严峻的挑战。
2-bit量化将模型权重压缩6-8倍,使其能存入手机闪存:4GB内存能放16B参数,配合MoE与激活范围约束可达32B;若内存扩大到8GB,则能将模型参数扩大到60B。在内存价格飞涨、端侧设备资源始终受限的情况下,低比特量化成为手机厂商未来竞争力的关键——谁能最早用更低的成本将手机做得更智能,谁就能掌握大模型时代的主动权。
行业的传统解法是后训练量化(PTQ),即先用高精度(如BF16)完成模型训练,再将权重压缩至INT8或INT4。这本质上是一种"事后补救",一种"以精度换内存"的工程妥协,压缩越狠性能损失越大。
BitCPM-CANN彻底颠覆了这一路径。它采用量化感知训练(QAT)路线——模型并非在训练完成后才被动压缩,而是在训练的初始阶段就主动学习如何用1.58-bit的三值权重(-1, 0, +1)来承载和表达知识。这不再是简单的精度丢弃,而是从根本上让模型在极低比特位宽的约束下"原生生长",迫使每一个bit发挥出最大的信息密度和知识承载效率。

BitCPM-CANN与同尺寸MiniCPM4全精度模型家族在常识、阅读理解、学科知识、数学与推理等11项任务上进行1:1性能对照:
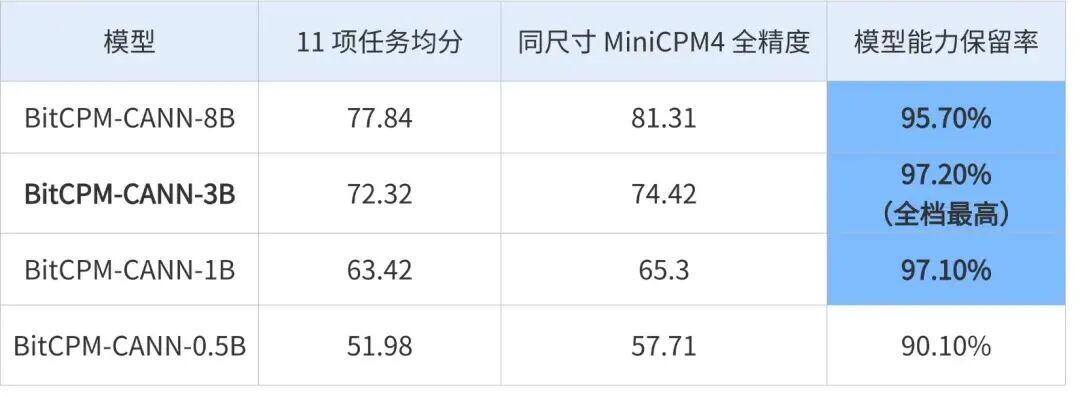
三个较大规格的能力保留率在95.7%-97.2%区间,即使最小的0.5B也达到90%以上。这个结果表明:低比特训练的技术路线具备系统性、可扩展性和工程可复现性。
对手机产业来说,6倍的显存红利意味着一个8B参数的BitCPM-CANN大模型可以轻松运行在当前主流旗舰手机之上。若进一步结合MoE架构,将50B乃至100B参数的模型装入终端,已拥有清晰的实现路径。
对芯片生态来说,以高通骁龙8 Gen 4为代表的新一代端侧芯片,已在硬件层面原生支持2-bit推理。然而硬件的就绪需要高质量、可直接落地的低比特模型来匹配。
BitCPM-CANN填补了端侧芯片在低比特模型"供给侧"的空档,为软硬件协同发展提供了关键弹药。
基于昇腾,攻克国产算力极低比特训练难题
BitCPM-CANN 的另一个重磅意义,在于它 完全基于国产算力平台完成训练。
从最底层的量化算子、QAT(量化感知训练)算法,到完整的并行策略和训练框架,BitCPM-CANN 的整个训练链路均在华为昇腾上原生完成。
这是昇腾平台上 首个公开的、端到端完成 1.58-bit 训练并进行全精度对照评测的成果,且模型规模一次性推进至 8B 级别。
这项技术的门槛远超「把一个 GPU 上训好的模型搬到昇腾上跑推理」。过去,国产 NPU 阵营验证低比特训练,通常需要先在 CUDA 上完成再迁移,链路漫长且损耗巨大。
BitCPM-CANN的成功,意味着 国产 NPU 阵营第一次拥有了自己的 1.58-bit 低比特训练栈。
面壁智能基于 MindSpeed × Megatron-LM 主干搭建了完整的低比特训练底座,包含环境适配、32K长序列支持、并行策略、融合算子等完整工程体系。从此,所有面向昇腾的低比特训练工作,都可建立在同一套公共基础设施之上。
BitCPM-CANN 用事实回答了一个行业关切的问题:昇腾不仅能训大模型,更能完成世界级的极低比特训练。
「国产芯片只能跑推理」的刻板印象,从此可以正式翻篇。
模型部署
MiniCPM5-1B
vLLM部署:
pip install "vllm>=0.21"
VLLM_USE_MODELSCOPE=true vllm serve openbmb/MiniCPM5-1B --port 8000
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openbmb/MiniCPM5-1B",
"messages": [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}],
"max_tokens": 128,
"temperature": 0.7
}'SGLang部署(推荐用于工具调用):
pip install "sglang[srt]>=0.5.12"
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server \
--model-path openbmb/MiniCPM5-1B --port 30000 \
--tool-call-parser minicpm5
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openbmb/MiniCPM5-1B",
"messages": [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}],
"max_tokens": 128,
"temperature": 0.7
}'Transformers推理:
pip install -U "transformers>=5.6" accelerate torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "OpenBMB/MiniCPM5-1B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id, torch_dtype="auto", device_map="auto"
)
messages = [{"role": "user", "content": "Who are you?"}]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
enable_thinking=False, return_tensors="pt"
).to(model.device)
outputs = model.generate(inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0][inputs.shape[-1]:], skip_special_tokens=True))推荐采样参数:Think模式temperature=0.9, top_p=0.95, enable_thinking=True;No Think模式temperature=0.7, top_p=0.95, enable_thinking=False。
MiniCPM5-1B采用标准LlamaForCausalLM架构,还支持llama.cpp、Ollama、LM Studio、MLX、ArcLight等部署方式,以及TRL、LLaMA-Factory、ms-swift、Unsloth、xtuner等微调框架。详细指南请参考GitHub。
BitCPM-CANN
模型下载:
# 以1B为例,可选0.5B/1B/3B/8B
modelscope download --model OpenBMB/BitCPM-CANN-1BBitCPM-CANN采用伪量化格式,可以像标准全精度模型一样直接使用:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'OpenBMB/BitCPM-CANN-1B'
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
# User can directly use the chat interface
responds, history = model.chat(tokenizer, "Write an article about Artificial Intelligence.", temperature=0.7, top_p=0.7)
print(responds)
模型微调
ms-swift 支持了 MiniCPM5 系列模型的微调。ms-swift是魔搭社区官方提供的大模型训练框架,开源地址:https://github.com/modelscope/ms-swift
环境准备:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
pip install "transformers>=5.6" -U可直接运行训练脚本如下:(如需保留模型的思考能力,请在训练数据中混入一定比例的带思考数据。)
# 10GiB
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model OpenBMB/MiniCPM5-1B \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--tuner_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--loss_scale ignore_empty_think \
--add_non_thinking_prefix true \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_aligner true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataset_num_proc 4 \
--dataloader_num_workers 4
写在最后
BitCPM-CANN和MiniCPM5-1B分别从低比特训练和智能密度两个方向推高了端侧大模型的能力天花板。
BitCPM-CANN用1.58-bit QAT在国产算力上实现了6倍显存压缩且能力保留超过90%,从量化算子到训练框架全链路在昇腾原生完成,为端侧芯片的低比特模型供给补全了关键一环。
MiniCPM5-1B以1B参数在AA榜单上超越所有2B以下模型,用分级数据治理和高质量合成数据证明了小模型的智能密度仍有巨大提升空间,ForgeTrain的成功更验证了"AI制造AI"的路径可行性。
两款模型的共同指向是:不是等硬件变强来适应模型,而是让模型变聪明来适应硬件。从MiniCPM到BitCPM-CANN,面壁智能在端侧AI上的信念始终没有变。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献1029条内容
已为社区贡献1029条内容

所有评论(0)