
蚂蚁百灵全模态 Ming-flash-omni-2.0 开源!视觉百科+可控语音生成+全能型图像编辑,打破全模态“博而不精”
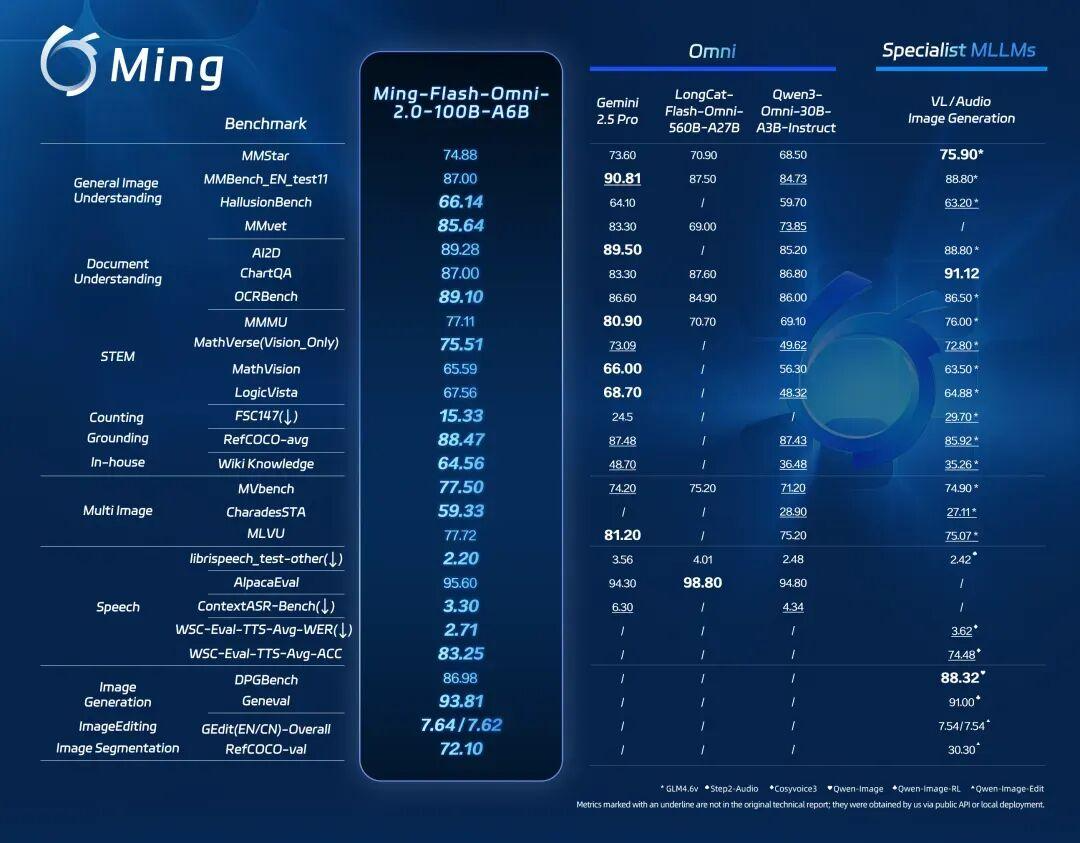
2月11日,蚂蚁百灵团队开源发布了百灵全模态大模型 Ming-flash-omni-2.0,基于 Ling-2.0(MoE 架构,100B-A6B)架构训练。相比之前发布的 Preview 版本,Ming-flash-omni-2.0 实现了全模态能力的代际跃迁,无论是在复杂的视觉理解、充满情感的语音交互,还是极具创意的图像编辑上,Ming-flash-omni-2.0 的实测表现均已跻身开源领先水准。
Ming-flash-omni-2.0 模型权重和推理代码已开源
Model:
https://www.modelscope.cn/models/inclusionAI/Ming-flash-omni-2.0
GitHub:
https://github.com/inclusionAI/Ming
长期以来,多模态大模型领域存在一个难题:通用的“全模态大模型”(Omni-MLLMs)往往在特定领域的表现不如“模态专用大模型”(Specialist MLLMs)。Ming-omni 系列的研发初衷,正是为了填补这道鸿沟。从 Lite 版本到 Flash Preview,百灵团队验证了模型规模对性能的提升作用;而从 Preview 到如今的 2.0 版本,则通过海量数据的精细化打磨,进一步触达了性能的天花板。Ming-flash-omni-2.0 的诞生证明了:一个统一架构的全模态模型,完全可以既是博学的通才,又是特定模态的专家。
模型结构:
特色能力
Ming-flash-omni-2.0 兼具领先的通用泛化性能与深度的领域专长,特别是在视觉百科知识力、沉浸式语音生成及高动态图像创作领域,展现出极强的专业竞争力。
视觉百科:看懂万物,更懂你所见
Ming-flash-omni-2.0 不仅仅是看见图像,更能调动背后的专家级知识库,实现“所见即所知”。它能:
- 懂自然:精准识别花草鸟兽,从珍稀植物的品种溯源、濒危动物的特征识别,科普知识随手可得;
- 懂生活:从解析地方名菜风味到全球地标的精准匹配,满足好奇心与实用性;
- 懂专业:文物古玩精准辨识,识别年代、器型与工艺细节,成为工作中的高效助手。
当博学的“百科全书”叠加了极致的“视觉捕捉”,Ming-flash-omni-2.0 展现出了极强的时空语义理解能力:
📎0bc3t4aaaaaapmafgwummnuvbh6dacpqaaaa.f10002.mp4
可控语音生成:有情绪,有温度,声临其境
告别机械的电子音,Ming-flash-omni-2.0 让声音充满了表现力。它不仅能说话,还能根据你的指令调整情绪、语调甚至背景氛围。
- 让文字拥有温度与情绪:你可以通过指令控制方言、语速、情感,同时支持普通话、粤语、四川话的自然切换。
- 千人千面的声音定制:支持基于自然语言描述的音色定义(涵盖年龄、性别、情感质感等维度),想要特定的音色?只需一段自然语言描述即可生成对应风格的音色,或者从内置的 100+ 精品音色与经典角色音色中挑选,它都能精准还原、自然演绎。
- 全能的声音艺术家:Ming-flash-omni-2.0 作为业界首个将语音、音效和背景音乐生成融为一体的模型,实现了三类声学信号统一自回归 + 连续音频表征来生成,营造出声临其境的听觉体验。
以下展示了 Ming-flash-omni-2.0 沉浸式的语音合成效果:
📎0bc3lubvkaaddyaaczep5vuvgxodkvoqgvia.f10002.mp4
图像创作:所想即所见,光影随心变
Ming-flash-omni-2.0 实现全能型图像处理能力,大幅提升生图、改图及分割的性能表现,赋予了你对画面的绝对掌控权。
- 氛围感重构:拒绝千篇一律的游客照。一句话,就能把平平无奇的照片变成“节日大片”或“故事感写真”,只需一句简单的指令——如烟花、海鸥、日出日落、花瓣雨、落叶纷飞、毛毛细雨或漫天飞雪,模型便能在完美保持人物与场景特征一致性的同时,为画面自然注入沉浸式的环境氛围。
- “任意门”般的场景合成:想去阿尔卑斯滑雪?无需P图高手,模型能精准理解你的指令,将人物无缝融入全新的背景中。
- 智能的“橡皮擦”:无论是杂乱的人群还是多余的物体,它都能精准移除,并自动补全背景细节,还原照片最纯净的美。
通过融合 Ming-flash-omni-2.0 的语音与图像生成能力,还可以实现“音画一体”的创作体验。所见有形,所感有声,让视觉的张力与听觉的温情在此刻深度交织。
📎0bc3pmabsaaareae2eemjnuva66ddf5qagia.f10002.mp4
技术深解
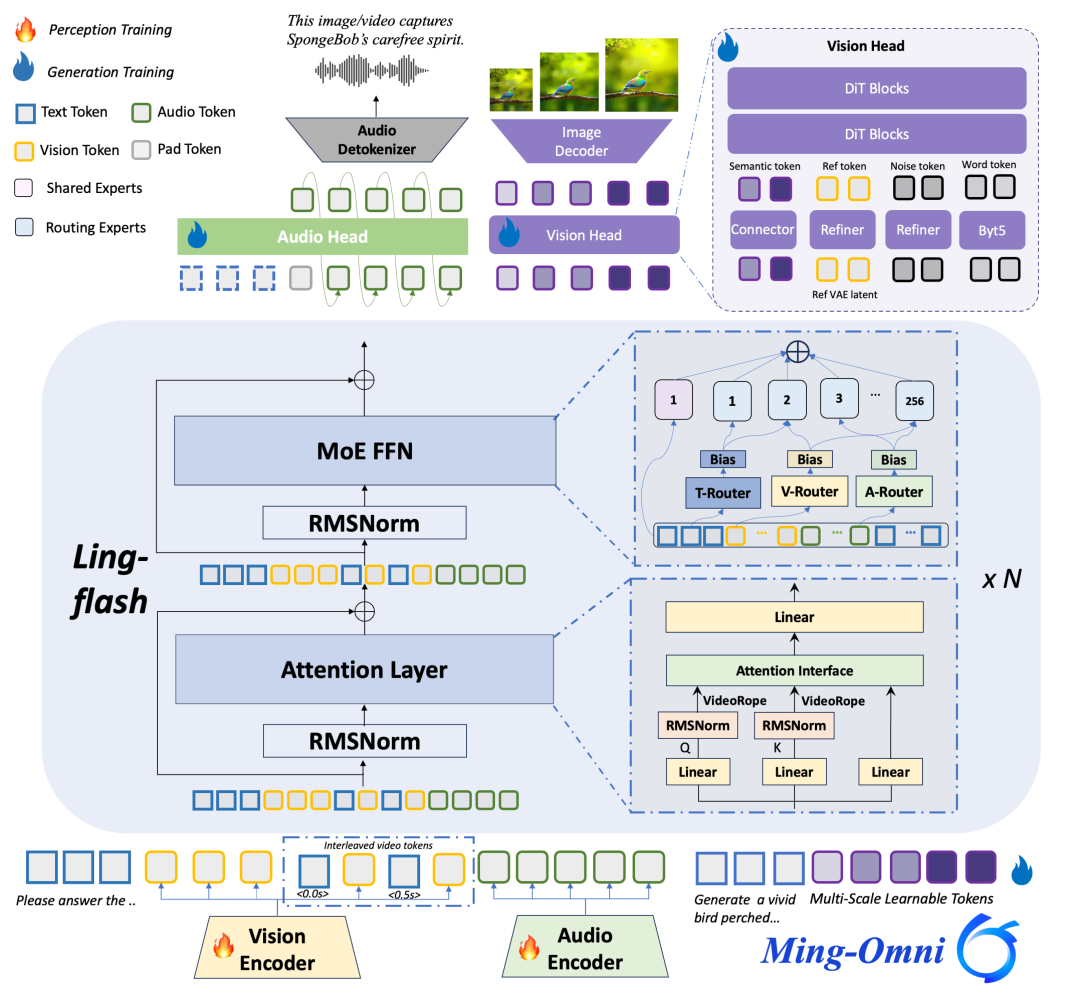
全模态感知的强化
- 像素级细粒度感知: 针对易混淆的图像(如珍稀动植物),官方引入了亿级高质量数据,并采用“难例挖掘”策略,通过将相似样本拼接为多图布局进行对比学习,促进模型在对比学习中学会分辨微小的特征差异。
- 音频细粒度感知增强: 引入高质音频-文本数据,对语音的年龄、性格、风格、语速、语调、职业、情绪、方言等维度进行精细标注,强化 Ming-flash-omni-2.0 对人声和音色的感知和可控生成能力。
- 结构化知识对齐: 通过引入知识图谱,将图像实体、音频描述与结构化的专家知识对齐,确保模型不仅“看到”,更能“懂得”。
- 视频时序建模: 引入 Time-Interleaved VideoRoPE 机制,就像给视频帧打上了精准的时间戳,显著增强了模型对动态事件的捕捉能力。
泛音频统一生成框架
Ming-flash-omni-2.0 作为业界首个全场景音频统一生成模型,可在同一条音轨中同时生成语音(Speech)、环境音效(Audio)与音乐(Music)。针对语音、音效与音乐在频带分布及序列长度上的显著差异的难题,百灵团队提出了异构音频信号联合建模方案:
- 低帧率/高保真连续表征:自研 12.5Hz 超低帧率连续语音 Tokenizer,实现了对高频 Audio/Music 信号的高保真重构。该机制不仅降低了特征冗余,更在统一的潜在空间内实现了异构音频信号的标准化表征。
- Patch-based 压缩与曝光偏差缓解:引入 Patch-by-Patch 四帧压缩策略,将生成序列长度进一步缩减。这一设计有效缩短了自回归建模的路径,显著缓解了超长音频生成任务中常见的曝光偏差累积问题,通过非对称的 DiT head condition 和 patch size 解决多种类型音频统一建模。
- 极低频推理优化:在推理阶段,模型实现了 3.1Hz 的业界极低推理帧率。这不仅极大降低了计算开销,而且使模型在保持高音质输出的同时,具备了实时的生成速度与极致的计算效率。
视觉生成、编辑和分割的深度融合
Ming-flash-omni-2.0 首创将生成、编辑、分割融入单一原生模型,实现架构级深度统一的同时,模型在生成、编辑及分割的典型指标上均达领先水平,并兼顾了生成图像的视觉真实感。
- 原生单流与动态感知:采用单流设计,在统一 Token 空间内利用全量注意力机制打通三大任务,并引入基于动作标签的平衡采样策略,针对高动态场景(如旅拍)实现任务间深度对齐。这一融合有效消除了复杂动作生成的僵硬感,确保了人物体态的自然与画面的动态张力。
- 扩散模型强化学习鲁棒性优化: 针对强化学习易出现的“奖励欺骗”问题,构建三重稳健机制。
1)冷启动:利用确定性的“编辑式分割”任务建立模型的基础空间认知与定位能力;
2)统一奖励空间建模:集成多维度评价指标,防止模型因过度优化单一奖励而陷入过拟合或退化解;
3)离线分布正则化:通过引入约束项,确保生成内容始终锚定在真实图像分布内,大幅提升结果的视觉保真度。
模型实战
第一步 环境准备
pip install -r requirements.txt
pip install nvidia-cublas-cu12==12.4.5.8 # for H20 GPU第二步 下载代码仓库
git clone https://github.com/inclusionAI/Ming.git
cd Ming第三步 下载模型
Download our model following Model Downloads
mkdir inclusionAI
modelscope download inclusionAI/Ming-flash-omni-2.0
ln -s /path/to/inclusionAI/Ming-flash-omni-2.0 inclusionAI/Ming-flash-omni-2.0第四步 模型推理
import os
import torch
import warnings
from bisect import bisect_left
warnings.filterwarnings("ignore")
from transformers import AutoProcessor
from modeling_bailingmm2 import BailingMM2NativeForConditionalGeneration
def split_model():
device_map = {}
world_size = torch.cuda.device_count()
num_layers = 32
layer_per_gpu = num_layers // world_size
layer_per_gpu = [i * layer_per_gpu for i in range(1, world_size + 1)]
for i in range(num_layers):
device_map[f'model.model.layers.{i}'] = bisect_left(layer_per_gpu, i)
device_map['vision'] = 0
device_map['audio'] = 0
device_map['linear_proj'] = 0
device_map['linear_proj_audio'] = 0
device_map['model.model.word_embeddings.weight'] = 0
device_map['model.model.norm.weight'] = 0
device_map['model.lm_head.weight'] = 0
device_map['model.model.norm'] = 0
device_map[f'model.model.layers.{num_layers - 1}'] = 0
return device_map
# Load pre-trained model with optimized settings, this will take ~10 minutes
model_path = "inclusionAI/Ming-flash-omni-2.0"
model = BailingMM2NativeForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map=split_model(),
load_image_gen=True,
load_talker=True,
).to(dtype=torch.bfloat16)
# Initialize processor for handling multimodal inputs
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
# Inference Pipeline
def generate(messages, processor, model, sys_prompt_exp=None, use_cot_system_prompt=False, max_new_tokens=512):
text = processor.apply_chat_template(
messages,
sys_prompt_exp=sys_prompt_exp,
use_cot_system_prompt=use_cot_system_prompt
)
image_inputs, video_inputs, audio_inputs = processor.process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
audio_kwargs={"use_whisper_encoder": True},
).to(model.device)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
with torch.no_grad():
generated_ids = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
use_cache=True,
eos_token_id=processor.gen_terminator,
num_logits_to_keep=1,
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return output_text
# qa
messages = [
{
"role": "HUMAN",
"content": [
{"type": "text", "text": "请详细介绍鹦鹉的生活习性。"}
],
},
]
output_text = generate(messages, processor=processor, model=model)
print(output_text)
# Output:
# 鹦鹉是一种非常受欢迎的宠物鸟类,它们以其鲜艳的羽毛、聪明的头脑和模仿人类语言的能力而闻名。鹦鹉的生活习性非常丰富,以下是一些主要的习性:
# 1. **社交性**:鹦鹉是高度社交的鸟类,它们在野外通常生活在群体中,与同伴互动、玩耍和寻找食物。在家庭环境中,鹦鹉需要与人类或其他鹦鹉进行定期的互动,以保持其心理健康。
# 2. **智力**:鹦鹉拥有非常高的智力,它们能够学习各种技能,包括模仿人类语言、识别物体、解决问题等。这种智力使它们成为非常有趣的宠物。
# ......
Ming-flash-omni-2.0 代表了百灵团队在全模态模型探索上的阶段性进展,在多项核心指标上取得了突破。但与大模型普遍存在的幻觉挑战类似,当前版本在知识准确性、特定 IP 内容的识别与生成,以及英文音色克隆的逼真度方面仍有提升空间。此外,指令遵循能力也需进一步优化,以更好地支持复杂任务的精准执行。未来百灵团队将持续优化 Ming-Omni 系列,向全模态智能的深水区挺进,在多任务融合中实现新的智能涌现。
点击即可跳转模型
https://www.modelscope.cn/models/inclusionAI/Ming-flash-omni-2.0

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献981条内容
已为社区贡献981条内容

所有评论(0)