
Qwen3-Coder-Next开源!推动小型混合模型在智能体编程上的边界
近日,Qwen团队开源发布了 Qwen3-Coder-Next,一款专为编程智能体与本地开发设计的开源权重语言模型。该模型基于 Qwen3-Next-80B-A3B-Base 构建,采用混合注意力与 MoE 的新架构;通过大规模可执行任务合成、环境交互与强化学习进行智能体训练,在显著降低推理成本的同时,获得了强大的编程与智能体能力。
Github:https://github.com/QwenLM/Qwen3-Coder
Model:https://www.modelscope.cn/collections/Qwen/Qwen3-Coder-Next
Blog:https://qwen.ai/blog?id=qwen3-coder-next
扩展智能体训练
Qwen3-Coder-Next 不依赖单纯的参数扩展,而是聚焦于扩展智能体训练信号。官方使用大规模的可验证编程任务与可执行环境进行训练,使模型能够直接从环境反馈中学习。训练过程包括:
- 在以代码与智能体为中心的数据上进行持续预训练
- 在包含高质量智能体轨迹的数据上进行监督微调
- 领域专精的专家训练(如软件工程、QA、Web/UX 等)
- 将专家能力蒸馏到单一、可部署的模型中
该配方强调长程推理、工具使用以及从执行失败中恢复,这些对现实世界中的编程智能体至关重要。
在编程智能体基准上的表现
面向智能体的基准结果
下图汇总了在多个广泛使用的编程智能体基准上的表现,包括 SWE-Bench(Verified、Multilingual、Pro)、TerminalBench 2.0 和 Aider。
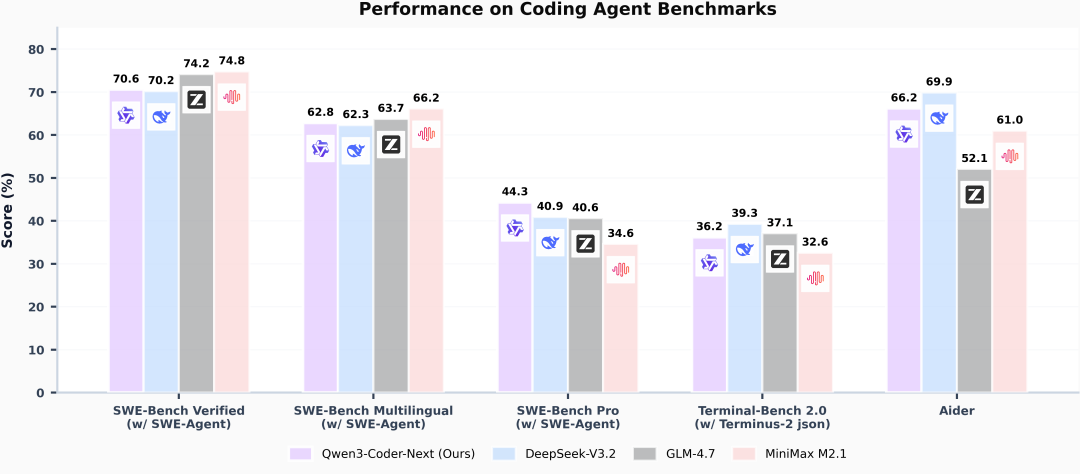
图中表明:
- 使用 SWE-Agent 框架时,Qwen3-Coder-Next 在 SWE-Bench Verified 上达到 70% 以上。
- 在多语言设置以及更具挑战的 SWE-Bench-Pro 基准上保持竞争力。
- 尽管激活参数规模很小,该模型在多项智能体评测上仍能匹敌或超过若干更大的开源模型。
效率与性能的权衡
下图展示了 Qwen3-Coder-Next 如何在效率与性能之间取得更优的帕累托权衡。
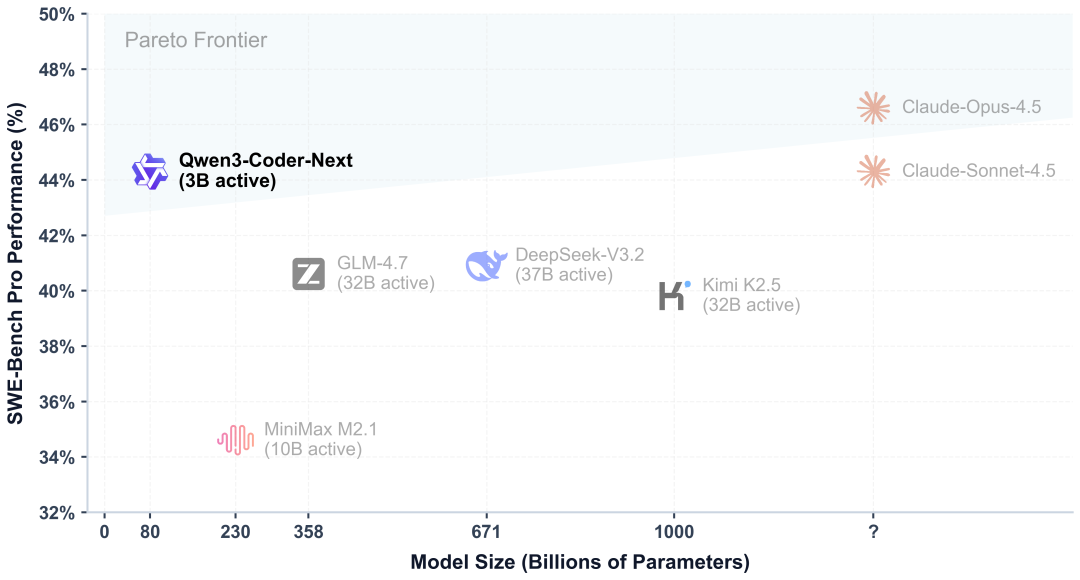
这一对比清晰体现了效率优势:
- Qwen3-Coder-Next(3B 激活)的 SWE-Bench-Pro 表现可与激活参数量高 10×–20×的模型相当。
- Qwen3-Coder-Next 在面向低成本代码智能体部署方面具有较为明显的优势。
模型实战最佳实践
模型推理
为获得最佳性能,官方推荐以下采样参数:temperature=1.0、top_p=0.95、top_k=40。
以下代码片段展示了如何基于给定输入使用该模型生成内容。
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-Next"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)注意:如果遇到内存不足(OOM)问题,请考虑将上下文长度缩短至较小值,例如 32,768。
对于本地使用,Ollama、LMStudio、MLX-LM、llama.cpp 和 KTransformers 等应用也已支持 Qwen3。
模型部署
部署时,可以使用最新版 sglang 或 vllm 创建兼容 OpenAI 的 API 端点。
SGLang
SGLang 是一个面向大语言模型和视觉语言模型的高速服务框架。 SGLang 可用于启动提供 OpenAI 兼容 API 服务的服务器。
Qwen3-Coder-Next 要求 sglang>=v0.5.8,可通过以下命令安装:
pip install 'sglang[all]>=v0.5.8'以下命令可在 2 块 GPU 上使用张量并行,创建一个最大上下文长度为 256K token 的 API 端点,地址为 http://localhost:30000/v1。
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model Qwen/Qwen3-Coder-Next --port 30000 --tp-size 2 --tool-call-parser qwen3_coder默认上下文长度为 256K。如果服务器启动失败,请考虑将上下文长度减小至更小的值,例如 32768。
vLLM
vLLM 是一个高吞吐量且内存高效的 LLM 推理与服务引擎。 vLLM 可用于启动提供 OpenAI 兼容 API 服务的服务器。
Qwen3-Coder-Next 要求 vllm>=0.15.0,可通过以下命令安装:
pip install 'vllm>=0.15.0'以下命令可在 2 块 GPU 上使用张量并行,创建一个最大上下文长度为 256K token 的 API 端点,地址为 http://localhost:8000/v1。
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-Coder-Next --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coder
NOTE
默认上下文长度为 256K。如果服务器启动失败,请考虑将上下文长度减小至更小的值,例如 32768。
智能体编码
Qwen3-Coder-Next 在工具调用能力方面表现卓越,可以像下面示例一样简单地定义或使用任意工具。
# Your tool implementation
def square_the_number(num: float) -> dict:
return num ** 2
# Define Tools
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
from openai import OpenAI
# Define LLM
client = OpenAI(
# Use a custom endpoint compatible with OpenAI API
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-Next",
max_tokens=65536,
tools=tools,
)
print(completion.choices[0])模型微调
我们推荐使用ms-swift对Qwen3-Coder-Next进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。ms-swift开源地址:https://github.com/modelscope/ms-swift
环境准备:
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
# 避免后续代码改动导致的不兼容问题
git checkout d2a67bf8cd6159faa74e5b109a80970eb81e1b6d
pip install -e .以下为使用自我认知数据集训练的Demo训练脚本:
# 8 * 55GiB
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=8 \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
megatron sft \
--model Qwen/Qwen3-Coder-Next \
--load_safetensors true \
--save_safetensors true \
--merge_lora true \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--load_from_cache_file true \
--tuner_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--expert_model_parallel_size 4 \
--moe_permute_fusion true \
--moe_grouped_gemm true \
--moe_shared_expert_overlap true \
--moe_aux_loss_coeff 1e-3 \
--micro_batch_size 2 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 1 \
--max_epochs 1 \
--finetune true \
--cross_entropy_loss_fusion true \
--lr 1e-4 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-5 \
--save megatron_output/Qwen3-Coder-Next \
--eval_interval 200 \
--save_interval 200 \
--max_length 2048 \
--num_workers 8 \
--dataset_num_proc 8 \
--no_save_optim true \
--no_save_rng true \
--sequence_parallel true \
--attention_backend flash \
--model_author swift \
--model_name swift-robot自定义数据集格式如下,修改训练脚本中的
{"messages": [{"role": "system", "content": "<system>"}, {"role": "user", "content": "<query1>"}, {"role": "assistant", "content": "<response1>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
对训练后的模型进行推理:
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift infer \
--model megatron_output/Qwen3-Coder-Next/vx-xxx/checkpoint-xxx-merged \
--stream true推送模型到ModelScope:
swift export \
--model megatron_output/Qwen3-Coder-Next/vx-xxx/checkpoint-xxx-merged \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'
模型链接:https://www.modelscope.cn/collections/Qwen/Qwen3-Coder-Next

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献984条内容
已为社区贡献984条内容

所有评论(0)