
告别“扁平思维”:Qwen-Image-Layered 开启 AI 图片的图层革命
你是否有过这样的挫败感:想让 AI 把合照里的路人移开,结果路人消失了,背景却像被抹了一层浆糊;想改一下海报里的字体,结果 AI 把整张图的画风都重绘了。
这种“牵一发而动全身”的翻车现场,本质上是因为 AI 一直在用「扁平图片」思考世界。对模型而言,图片只是像素的堆砌,而非物体的组合。
近日, Qwen 团队发布的最新研究 Qwen-Image-Layered 正式宣告:AI 图像编辑的“图层时代”来了!
Technical Report:
https://arxiv.org/abs/2512.15603
Blog: https://www.modelscope.cn/papers/2512.15603
Github: https://github.com/QwenLM/Qwen-Image-Layered
Model: https://www.modelscope.cn/models/Qwen/Qwen-Image-Layered
Demo: https://www.modelscope.cn/studios/Qwen/Qwen-Image-Layered
范式转移:从“改像素”到“动图层”
传统的 AI 修图是全局重采样,就像在湿透的画纸上改色,颜色必然会渗开。而 Qwen-Image-Layered 提出了一种根本性的转变:将图像表示为一组语义解耦的 RGBA 图层。

通过将图片自动“剥洋葱”,每一层都拥有独立的颜色(RGB)和透明度(Alpha)。这种「内生可编辑性」 (Inherent Editability)带来了物理隔离的保护:
精准位移(Reposition): 移动文字或人物,不影响底图任何像素
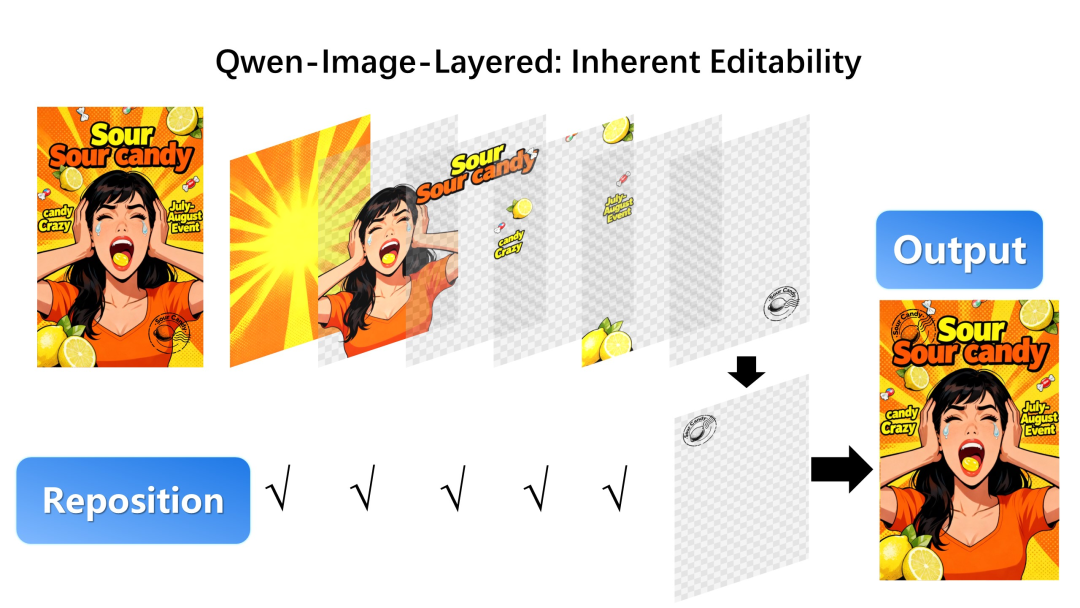
无损缩放(Resize): 放大主体,背景依然可以“钉”在原处
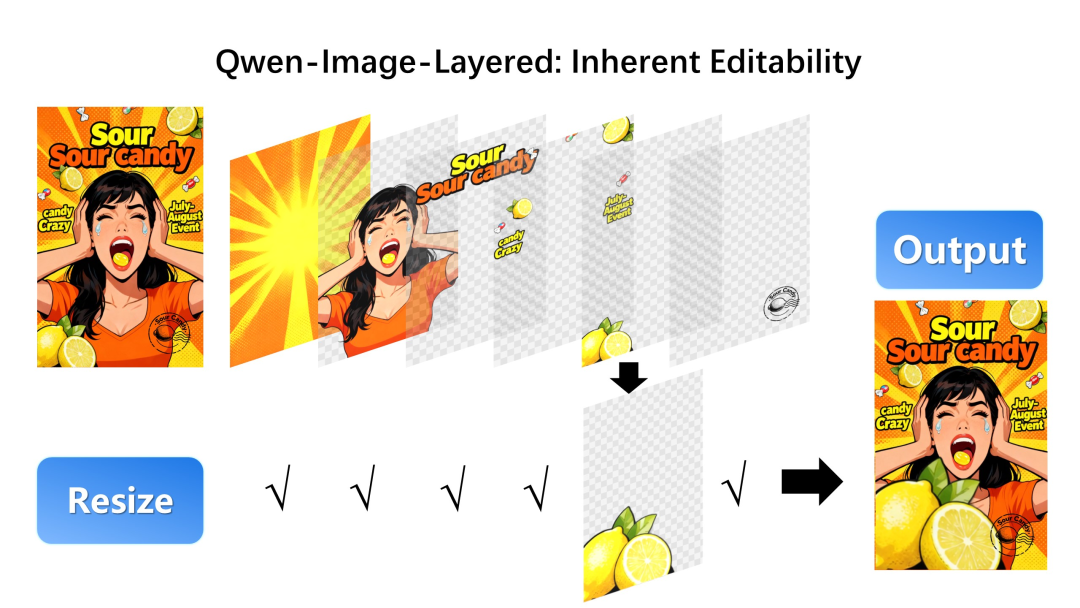
自由替换(Replace): 只换一件衬衫,不改变模特的脸型
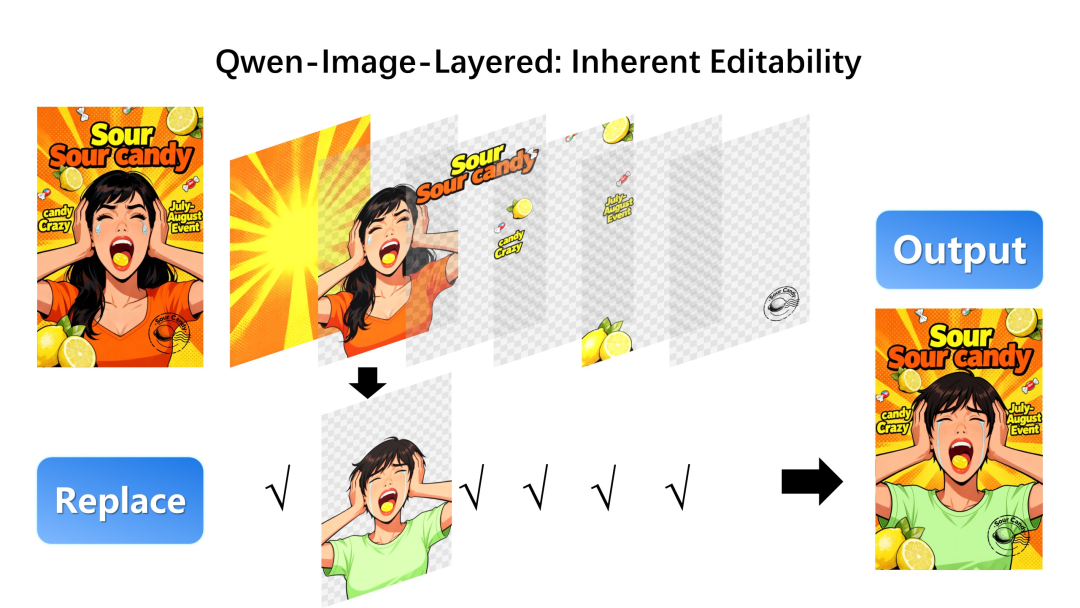
深度解析:像设计师一样“看图”
这项工作不仅是效果的提升,更是从底层重构了 AI 理解图像的逻辑 :
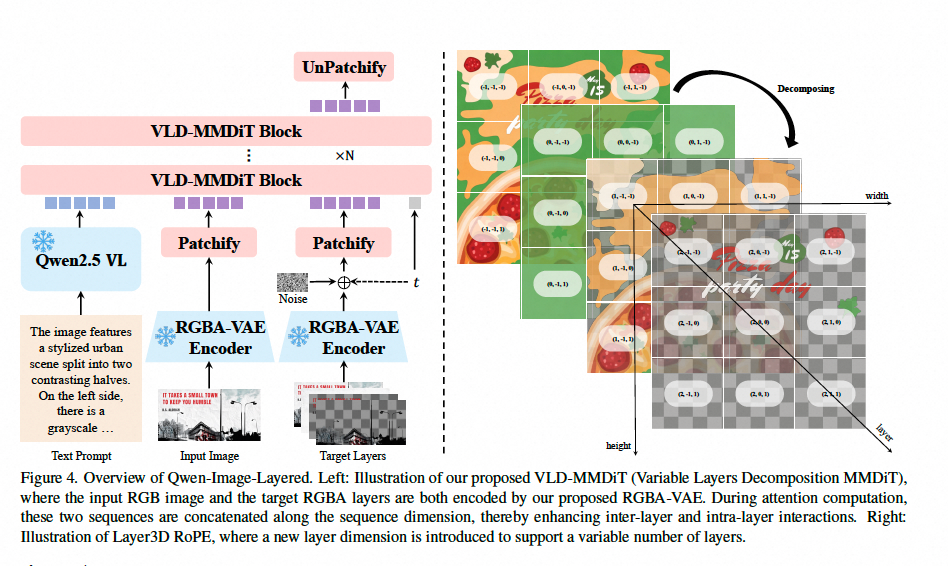
- RGBA-VAE:给 AI 装上“透明之眼”
传统的 VAE 只懂红绿蓝,Qwen 团队研发了全新的 RGBA-VAE,让 RGB 图像和带透明度的 RGBA 图层在同一个潜空间内“对话” ,解决了图层之间分布不均、边界模糊的顽疾。 - VLD-MMDiT:支持变长图层的“超级大脑”
现实世界的图层数是不确定的。VLD-MMDiT 架构能够一次性处理 3 层、10 层甚至更多图层,且层与层之间通过注意力机制协同,不再需要低效的递归拆解 。 - 多阶段进化:从生成到拆解
模型并非生而知之。它经历了从“生成单图”到“生成多层”,最后进化到“拆解任意 RGB 图像”的循序渐进过程,将强大的生成基因转化成了精准的理解力 。
实测代差:图层才是可编辑性的关键
在与主流方案(如 LayerD)的对比中,Qwen-Image-Layered 展示了惊人的统治力:
边界更干净: 在衡量透明度质量的 Alpha soft IoU 指标上显著领先。
背景更完整: 自动补全被遮挡的部分,且没有常见的“补丁”伪影。
编辑更稳定: 相比于 Qwen-Image-Edit 等全局编辑模型,它完全杜绝了像素级漂移。
即刻体验模型训练
魔搭社区的开源项目 DiffSynth-Studio 已率先支持 Qwen-Image-Layered 模型的训练。
Step 1: 安装 DiffSynth-Studio
项目链接:https://github.com/modelscope/DiffSynth-Studio
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
Step 2: 下载样例数据集
数据集链接:https://modelscope.cn/datasets/DiffSynth-Studio/example_image_dataset/tree/master/layer
modelscope download --dataset DiffSynth-Studio/example_image_dataset --local_dir ./data/example_image_dataset
Step 3: 开始训练 LoRA
accelerate launch examples/qwen_image/model_training/train.py
–dataset_base_path data/example_image_dataset/layer
–dataset_metadata_path data/example_image_dataset/layer/metadata_layered.json
–data_file_keys “image,layer_input_image”
–max_pixels 1048576
–dataset_repeat 50
–model_id_with_origin_paths “Qwen/Qwen-Image-Layered:transformer/diffusion_pytorch_model.safetensors,Qwen/Qwen-Image:text_encoder/model.safetensors,Qwen/Qwen-Image-Layered:vae/diffusion_pytorch_model.safetensors”
–learning_rate 1e-4
–num_epochs 5
–remove_prefix_in_ckpt “pipe.dit.”
–output_path “./models/train/Qwen-Image-Layered_lora”
–lora_base_model “dit”
–lora_target_modules “to_q,to_k,to_v,add_q_proj,add_k_proj,add_v_proj,to_out.0,to_add_out,img_mlp.net.2,img_mod.1,txt_mlp.net.2,txt_mod.1”
–lora_rank 32
–extra_inputs “layer_num,layer_input_image”
–use_gradient_checkpointing
–dataset_num_workers 8
–find_unused_parameters
更多信息,请参考 DiffSynth-Studio 的文档(https://github.com/modelscope/DiffSynth-Studio/blob/main/docs/zh/Model_Details/Qwen-Image.md)。
结语
AI 图像不应只是一张结果图,而应该是一种“结构化资产”。
当图像天然就是多图层时,AI 与 Photoshop 等专业设计工具的壁垒将被彻底打破。创作流程将从盲目的“抽卡试错”,变成像搭积木一样精准的操作。
Qwen-Image-Layered 补齐了这块缺失已久的地基。这不仅是一项技术的进步,更是图像生成范式的重塑。
点击直达模型:https://www.modelscope.cn/models/Qwen/Qwen-Image-Layered

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐

 0
0 0
0- 0



 已为社区贡献993条内容
已为社区贡献993条内容

所有评论(0)