
Z-Image:冲击体验上限的下一代图像生成模型
🔥过去一年,AI 文生图赛道“卷”得风生水起。从 Stable Diffusion、Flux、Qwen-Image到闭源的Nano-Banana,大家都在追求一个目标——更快、更强、更丝滑的使用体验。
来自通义实验室的 Z-Image(造相)模型 正式亮相,引发了业内广泛关注。它不仅在性能上直接对标国际一线模型,还在 速度、显存占用、中文能力、编辑体验 上表现出了惊人的能力,被许多人评价为:
“最值得关注的开源文生图模型之一。”
今天,我们就用一篇文章,带大家了解这款新模型为何备受期待✨
什么是 Z-Image?
Z-Image 是一个 6B 参数的高效图像生成基础模型,目前主要有三个版本:
- Z-Image-Turbo(已开源)
https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo - Z-Image-Base(即将开源)
- Z-Image-Edit(即将开源)
其中最受关注的是 Turbo 版本,它是社区最期待的“小步数、低延迟”大模型之⼀。
Turbo 有多强?
根据官方 README 中的介绍:
- 只需 8 步,生成速度亚秒级
- 能跑在 16GB 显存 的消费级设备上
- 中英双语文本渲染能力极强
- 真实感、构图、美学表现均接近或超过国际主流开源模型
简单说就是:快、稳、轻、准。
特别是 Turbo 版本在 真实感 + 可控性 + 文字渲染 三方面的综合表现,让不少体验者直言“有内味了”。


为什么 Z-Image? 生成又快又好?
Z-Image 的技术亮点可以概括为一句话:
它不是更“堆料”,而是更“聪明”。
单流架构:Scalable Single-Stream DiT(S3-DiT)
README 中提到,Z-Image 的架构是 单流(Single-Stream)Diffusion Transformer。
什么意思?
简单说,许多模型把文字、图片 Token 分开处理,需要复杂的跨模态交互;Z-Image 则直接把文本 Token、视觉语义 Token、VAE Token 全部拼成一个序列,让模型 “一条龙处理”。
这种设计带来的效果非常明显:
- 参数更高效利用
- 推理更快
- 结构更简洁,训练更稳定
业内许多人认为,单流 DiT 会成为未来文生图模型的重要方向。
8 步生成背后的“魔法”:Decoupled-DMD & DMDR
如今的小步数模型越来越多,但 Z-Image 能做到“快得离谱、好得惊人”,最重要的技术突破来自:
1、Decoupled-DMD
这是 Z-Image Turbo 核心的 蒸馏方法,其亮点是:
- 把以前大家混在一起理解的 DMD 机制拆开研究
- CFG 增强(CA)负责“推着模型往前冲”
- 分布匹配(DM)负责“纠错与稳定”
这种“发动机 + 稳定器”的组合让模型:
- 少步数但不失真
- 速度快但场景保持力强
- 画面一致性、美学评分全面提升
2、DMDR:把 RL 与 DMD 合在一起
在更高阶段的训练中,他们又把 强化学习(RL) 和 DMD 蒸馏 合并,提出 DMDR。
一句话总结:RL 释放创造力,DMD 保证稳定性。
这也是为什么 Z-Image 在 语义对齐、结构保持、高频细节 上表现非常好。
中文场景的“天生强者”:文字渲染 & 中文编辑
和许多海外模型不同,Z-Image 在设计之初就兼顾了中英双语场景。
README 展示的例子中,复杂的中文字体渲染清晰可控,这在许多开源模型上都是难点。
网络上体验过 Z-Image 的用户也普遍反馈:
- 中文理解能力强
- 中文风格图像生成准确
- 对中国文化元素(国风、山水、艺术)表现优异
特别是即将发布的 Z-Image-Edit,支持精准的自然语言编辑(inpainting、局部改动、风格迁移等),搭配 Turbo 的速度,很可能成为中文 AI 图像编辑领域的新标杆。
实际效果如何?从社区反馈看真实力
Z-Image在ModelScope上做开源首发之前,就提前接入了ModelScope的AIGC专区,供开发者试用。调试期间,模型短暂开启了“申请制”要求,在AIGC专区体验了模型及其强大的效果之后,众多的开发者排队求申请通过,甚至玩起了梗:
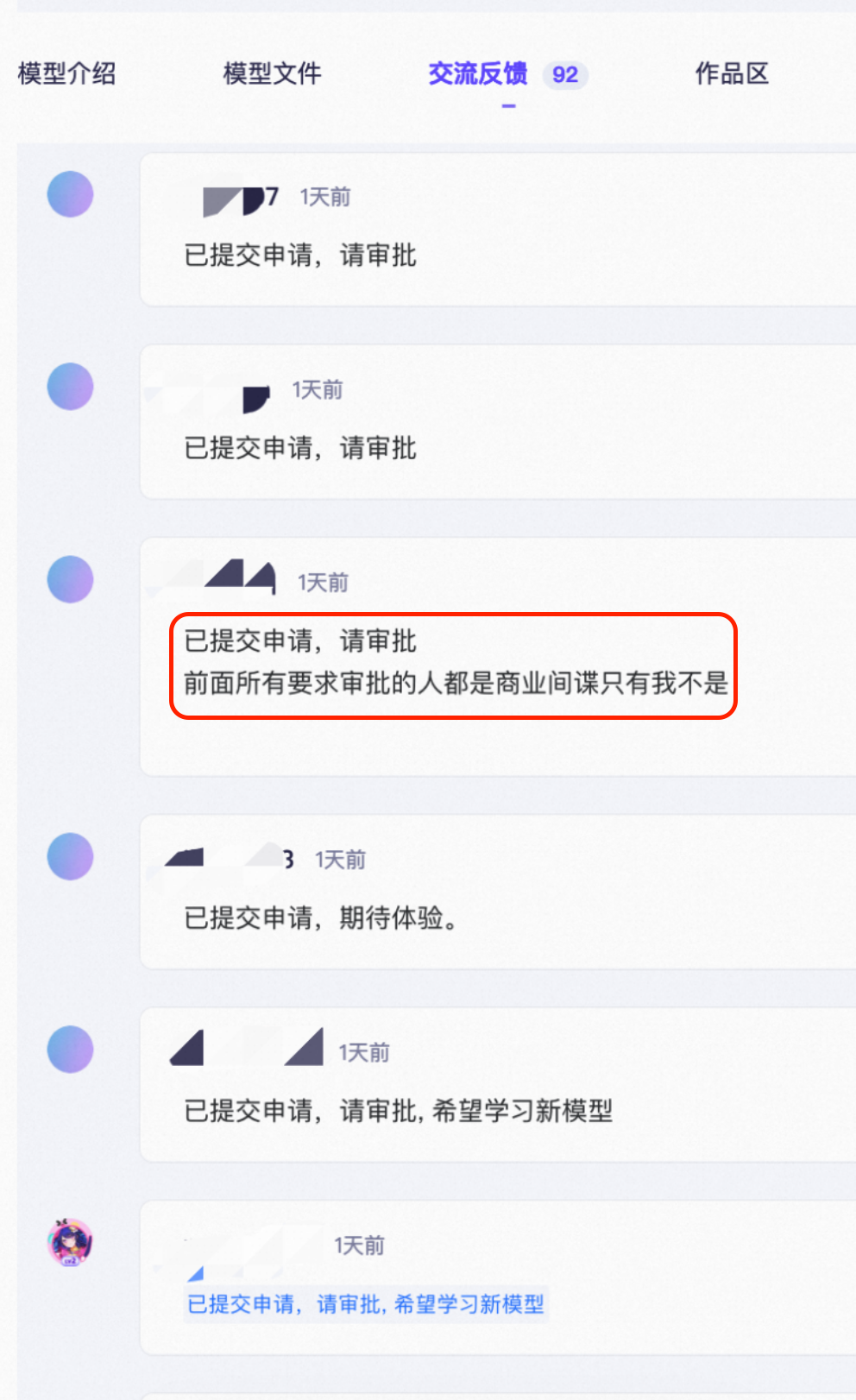
当然,申请制只是在模型开源准备期间的临时配置,现在模型已经正式对外开放下载,给更多开发者带来了惊喜,从目前网络讨论与社区 Demo 来看,Z-Image 的亮点包括:
✔️ 真实感强,光影自然
无论人物、室内、风景,都有非常优秀的质感。
✔️ 文字渲染强(尤其是中文)
相比许多模型渲染中文容易“乱码”,Z-Image 的表现稳定。
✔️ Prompt 理解精准
特别是复杂提示词、多元素、多主体场景,遵循度高。
✔️ 速度惊人
体验者普遍反馈:“第一次觉得开源模型能做到这么快。”
魔搭玩家:如何开始使用?
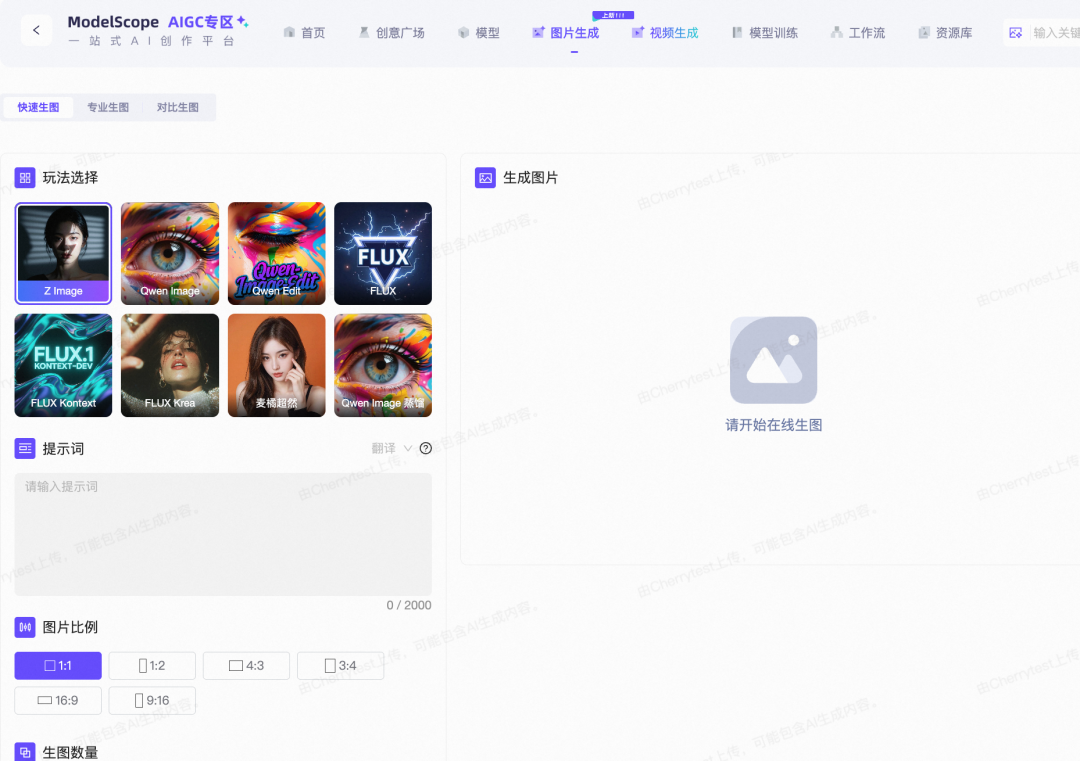
1、魔搭社区AIGC专区
点击下方链接,直接进入魔搭社区AIGC专区的“图片生成”页面:
🔗https://modelscope.cn/aigc/imageGeneration
Z-Image已经是默认生图模型
可以根据需求,在“快速生图”或“专业生图”模式中切换:
-快速生图:适合想要即刻看到结果,对参数要求不高的朋友。
-专业生图:适合追求极致细节和个性化效果的“进阶玩家”。
2、魔搭社区API Inference
点击下方链接,进入 造相-Z-Image-Turbo 的官方模型卡片页面: 🔗https://modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo
一键复制代码,本地/云端自由部署 在页面右侧的“推理 API-Inference”侧边栏,你可以直接看到并一键复制完整的Python调用代码!
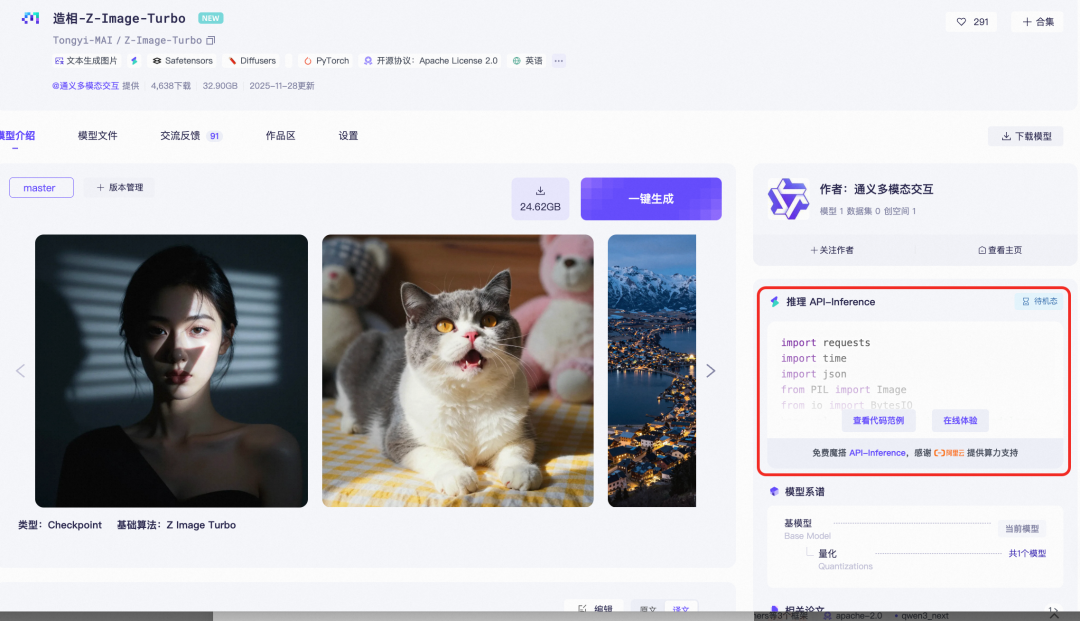
这意味着你可以:
- 在自己的本地电脑或Jupyter Notebook中,轻松调用API进行推理。
- 将Z-Image的能力无缝接入到你的开发项目中。
- 与ComfyUI等主流工作流平台结合,打造更复杂的自动化创作流程。
免费算力支持
魔搭社区还提供了免费的API-Inference服务,让你无需担心服务器成本,就能畅快体验!
Z-Image 的意义
Z-Image 的出现,正在让开源文生图模型的“体验差距”被大幅缩小。
特别是 Turbo 版本,让人第一次感觉到:
“速度、美学、中文、稳定性,这些优点可以同时具备。”
未来如果 Base、Edit 全面开放,Z-Image 很可能成为:
- 国内 AIGC 技术社区的底座模型
- 创作者/设计师常用工具
- 各类图像产品的核心能力组件
- 二次精调、行业落地的最佳起点
更重要的是,它给了开源社区一个新的方向:
更轻、更快、更智能,而不是单纯更大。
它不仅是技术升级,更是体验升级。
如果说 2024–2025 是“多模态大模型之争”,
那么 2025 年之后,可能就是:
“谁能把 AI 图像做得更快、更准、更好用”之争。
而 Z-Image,无疑是其中最亮眼的选手之一。
点击即可跳转模型链接造相:https://modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献985条内容
已为社区贡献985条内容

所有评论(0)