
新的LLM交互模式!大模型终于能自己生成交互式 UI 了
你有没有想过——
当大模型回答一个问题时,它不仅能写出内容,还能自动生成一个完整的网页界面,里面带地图、图表、小游戏、甚至实时交互功能?
这不是科幻,而是 Google Research 最新发布的 Generative UI(生成式用户界面)带来的真实能力。
🔥 从“文字墙”到“交互网页”,体验升级
过去,我们和大模型对话,得到的往往是这样的结果:
📘 一段 Markdown 格式的文字,可能带点 emoji、表格、代码块…… 虽然比纯文本友好,但仍然是静态、单向、缺乏体验感的“文字墙”。
而 Generative UI 彻底改变了这件事。
它让大模型不仅仅是“内容生成器”,更成为一个即时的产品经理 + UI 设计师 + 前端工程师,为你动态生成一个可交互的网页应用。
比如:
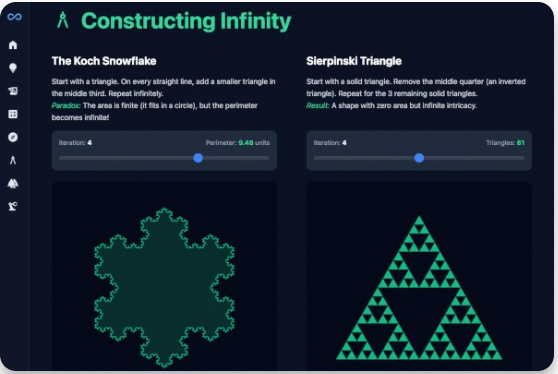
你问:“讲讲分形(Fractals)” → 它生成一个分形探索器:可拖拽的 Mandelbrot 集、实时联动的 Julia 集、维度计算器,甚至能一步步生成科赫雪花。
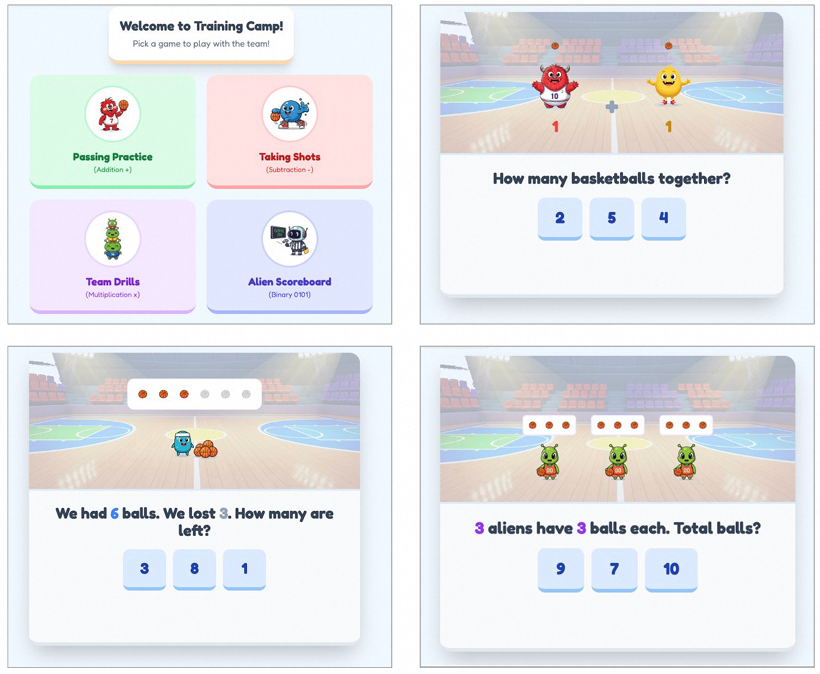
你问:“教我 5 岁孩子加减法” → 它做出一个篮球主题的数学小游戏,小怪兽投篮练加法,机器人计分练二进制。
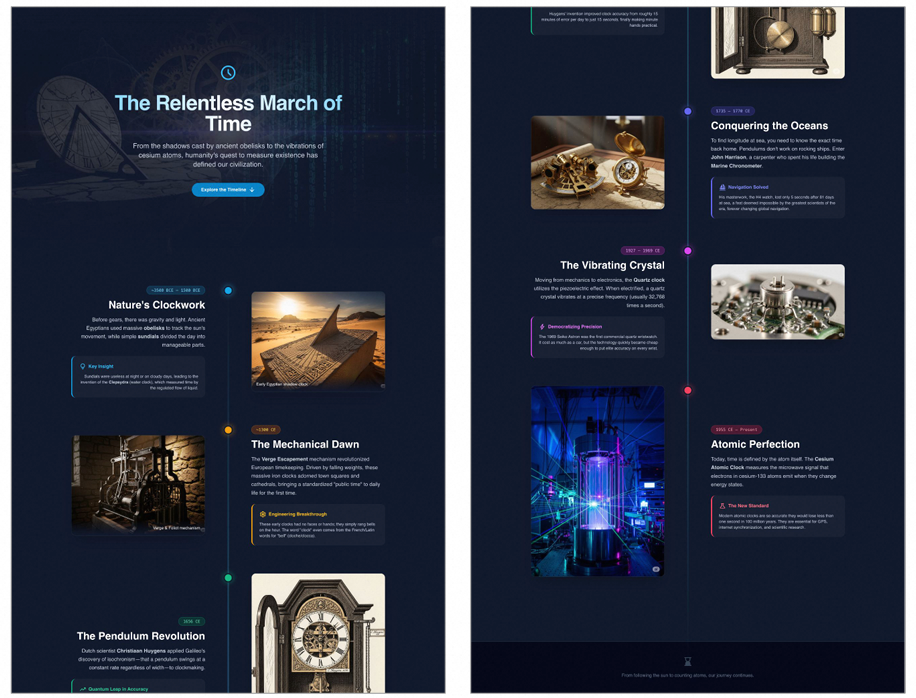
你问:“历史上有哪些计时工具?” → 它呈现一个垂直滚动的时间轴页面,从日晷到原子钟,每一段都配有生成的插图和关键突破说明。
这一切,无需人工设计,全由 LLM 一键生成。
📊 用户更爱 Generative UI
Google 在论文中做了严谨的人类偏好测试(基于 100+ 真实用户提问):
- Generative UI 被 82.8% 的用户认为显著优于传统 Markdown 输出
- 虽然仍比不上人类专家手作的网页,但在 44% 的场景中,质量已接近人类水平
更重要的是——这种能力是涌现的(emergent):只有在最新一代模型(如 Gemini 3)上才能稳定实现,旧模型错误率高、交互弱。
🛠️ 背后怎么做到的?
Generative UI 的实现并不依赖昂贵的定制系统,而是巧妙组合了三个低成本要素:
- 精心设计的系统提示(Prompt Engineering)
明确告诉模型:“你不是写文章,你是做一个可交互的 Web App”。 - 轻量工具链集成
模型可调用图像生成、搜索、地图等接口,通过标准<img src="/gen?...">等方式嵌入资源。 - 后处理纠错机制
自动修复 HTML/CSS/JS 常见错误,确保页面可运行。
整个系统完全基于开源技术栈(如 Tailwind CSS、标准 Web API),无需专有渲染引擎,非常适合本地部署或家用显卡环境实践。
🌐 动手试试看!
所有生成案例均已开源上线:
👉 https://generativeui.github.io
你可以在浏览器里直接体验这些 AI 生成的交互页面,感受“每个 prompt 都配一个专属应用”的未来。
同时,Google 还发布了 PAGEN 数据集——包含人类专家为相同问题手工制作的网页,供社区评估与对比。
💡 写给技术实践者的思考
Generative UI 的出现,再次验证了一个趋势:
未来的 AI 应用,不再是“内容 + 固定 UI”,而是“内容即 UI,UI 即应用”。
魔搭社区非常多的开发者关注低成本、高效率、可落地的开发者来说,这提供了一条新路径: 用一个强大 LLM + 简单工具链,就能替代传统产品-设计-开发的长流程,快速验证创意、服务长尾需求。
也许不久后,每个人的浏览器里,都会有一个“瞬时生成”的 AI 应用商店——你要的不是现成 App,而是“此刻最匹配你问题的那个界面”。
Paper: https://generativeui.github.io/static/pdfs/paper.pdf

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献984条内容
已为社区贡献984条内容

所有评论(0)