
MiniMax-M2 发布!10B激活,专为高效编码与Agent工作流而生
今天,Minimax正式发布并开源 MiniMax-M2,一款专为Max级编码与智能体打造的模型。
MiniMax-M2 是一款轻量、快速且极具成本效益的 MoE 模型(230B 总参数,10B 激活参数)。它在保持强大通用智能的同时,专为编码和智能体任务进行了深度优化。凭借仅 10B 的激活参数,它提供了开发者期待的端到端工具使用性能,同时其小巧的“身材”也更易于部署和扩展。
01核心亮点
卓越智能
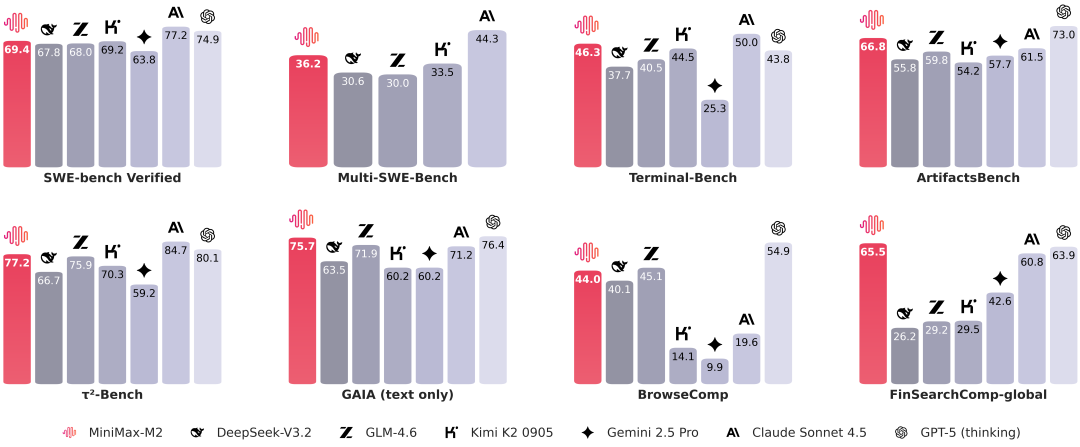
根据 Artificial Analysis 的评测结果,MiniMax-M2 在数学、科学、指令跟随、编码和智能体工具使用方面,展现了极具竞争力的通用智能,综合分数在全球开源模型中排名第一。
精通编码
MiniMax-M2具备强大的端到端开发能力,包括多代码文件处理、执行“编码-运行-调试”的完整循环,以及通过测试验证来自动修复代码。它在 Terminal-Bench 和 (Multi-)SWE-Bench 等基准测试中取得了出色的表现,并且在实际生产环境中,展现出很强的实用价值。
强大的Agentic能力
MiniMax-M2能够出色地规划并执行复杂的工具链,协同调用 Shell、浏览器、Python代码执行器和各种MCP工具。在 BrowseComp 评测中,它不仅可以挖掘到难以查找的信息源,还能保持信息来源的可追溯性,并具备自我纠错与恢复的能力。
高效设计
这款仅有10B激活参数(总参230B)的轻量级模型,在保持卓越性能的同时,实现了更低的延迟与成本,以及更高的吞吐效率,完美契合了新兴多智能体工作流对高效协同与快速响应的需求。它的出现顺应了模型发展的新趋势,即业界正积极转向那些“易于部署,且在编码和智能体任务上表现卓越”的解决方案。
02基准测试概览
MiniMax-M2 在一系列强调端到端编码和智能体工具使用的基准测试中表现优异。这些任务(如 SWE-bench, Terminal-Bench, BrowseComp, HLE (w/ tools), FinSearchComp-global 等)的性能与开发者在终端、IDE 和 CI 中的日常体验高度相关。
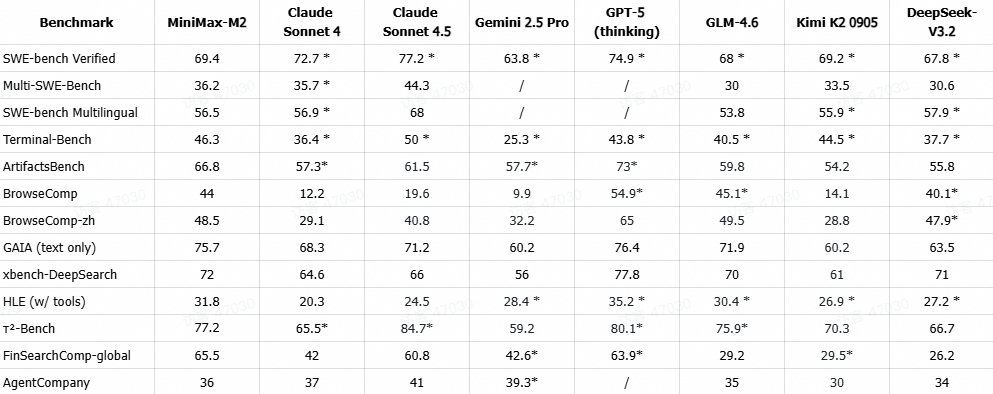
评测说明:带*的指标为直接援引自官方指标,其他指标通过以下方法测试得到:
- SWE-bench Verified: 在 OpenHands 基础上,使用了与 R2E-Gym (Jain et al. 2025) 相同的测试框架评估智能体在软件工程(SWE)任务上的表现。所有得分均在我们的内部设施上验证,配置为 128k 上下文长度、100 步最大限制,且未使用测试时扩展(test-time scaling)。所有 git 相关内容均被移除,以确保智能体仅能看到问题发生点的代码。
- Multi-SWE-Bench & SWE-bench Multilingual: 所有得分均使用 claude-code 命令行工具(最大步数 300 步)作为测试框架,测试 8 次取平均值。
- Terminal-Bench: 所有得分均使用 Terminal-Bench 原始仓库(commit 94bf692)中的官方claude-code版本进行评估,测试 8 次取平均值。
- ArtifactsBench: 所有分数均使用ArtifactsBench的官方实现计算,并采用Gemini-2.5-Pro作为评判模型,最终结果为 3 次运行的平均值。
- BrowseComp & BrowseComp-zh & GAIA (text only) & xbench-DeepSearch: 所有得分均使用了与 WebExplorer (Liu et al. 2025) 相同的智能体框架,仅对工具描述进行了微调。我们使用与WebExplorer (Liu et al. 2025) 相同的103个样本的GAIA纯文本验证子集。
- HLE (w/ tools): 所有得分均通过使用搜索工具和 Python 工具获得。其中,搜索工具采用了与 WebExplorer (Liu et al. 2025) 相同的智能体框架,而 Python 工具则在 Jupyter 环境中运行。我们使用HLE的纯文本子集。
- τ²-Bench: 所有得分均采用了“带工具使用的扩展思维”(extended thinking with tool use)模式,并使用 GPT-4.1 作为用户模拟器。
- FinSearchComp-global: GPT-5-Thinking、Gemini 2.5 Pro 和 Kimi-K2 报告的是官方结果。其他模型的评估则使用了开源的 FinSearchComp (Hu et al. 2025) 框架,配备搜索和 Python 工具,所有工具均同时启动以确保一致性。
- AgentCompany: 报告的所有得分均使用 OpenHands 0.42 智能体框架。
在 Artificial Analysis (AA) 综合智能基准测试中,MiniMax-M2表现卓越,总分位列全球开源模型榜首。该评测体系全面覆盖了模型在数学、科学与编码等多个核心领域的能力。
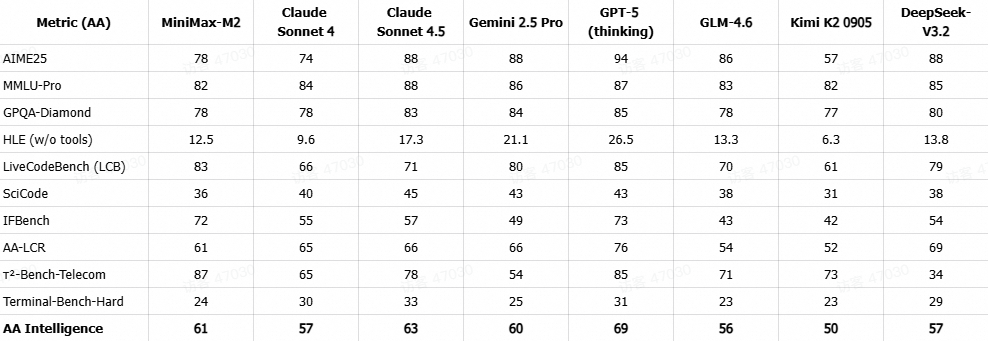
以上得分均直接引用Artificial Analysis官方评测结果 (https://artificialanalysis.ai/)
03 10B激活:智能体时代的理想之选
将激活参数规模保持在10B,能够极大提升智能体工作流中 “规划 → 行动 → 验证” 这一核心链路的运转效率。
这意味着:
✅ 更快的反馈循环: 在“编辑-运行-测试”或“检索-浏览-引用”等任务流中,获得更敏捷的响应;
✅ 更高的成本效益: 同等预算下,可支持更多并发任务(如回归测试、多路径探索等),每一分投入都物超所值;
✅ 更从容的资源规划: 单次请求的内存占用更小,且延迟表现更加稳定,能有效避免高峰期的性能瓶颈,让容量规划更轻松。
04模型使用
基于MiniMax-M2的通用Agent产品MiniMax Agent现已全面开放使用,并限时免费:https://agent.minimaxi.com/
MiniMax-M2 API已在MiniMax开放平台开放使用,并限时免费:https://platform.minimaxi.com/docs/guides/text-generation
MiniMax-M2模型权重已开源,可以本地部署使用:https://modelscope.cn/models/MiniMax/MiniMax-M2
05模型推理
ms-swift
你也可以使用ms-swift对MiniMax-M2进行推理交互体验,首先你需要安装ms-swift和vLLM:
uv pip install 'triton-kernels @ git+https://github.com/triton-lang/triton.git@v3.5.0#subdirectory=python/triton_kernels' vllm --extra-index-url https://wheels.vllm.ai/nightly --prerelease=allow
pip install git+https://github.com/modelscope/ms-swift.git
推理命令如下:
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift infer \
--model MiniMax/MiniMax-M2 \
--vllm_max_model_len 8192 \
--vllm_enable_expert_parallel \
--vllm_tensor_parallel_size 4 \
--infer_backend vllm
推理参数
推荐使用以下推理参数以获得最好的性能:temperature=1.0, top_p = 0.95,top_k = 40
06总结
如果您希望兼得旗舰级的编码与智能体能力,同时避免高昂的成本与复杂的部署流程,那么 MiniMax-M2 将是实现最佳性能-成本平衡的理想选择。它以轻量化的参数规模,展现出强大的端到端工具调用能力与流畅的运行速度,并具备极高的部署灵活性。
想要了解更多,请点击跳转模型链接~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献983条内容
已为社区贡献983条内容

所有评论(0)