
开源大模型部署
目前流行的部署方法分为:1.通过大模型官网API进行模型调用 2.在相关下载模型进行本地部署。我将详细讲解这两种方式的实现流程。
目录
前言:目前流行的部署方法分为:1.通过大模型官网API进行模型调用 2.在相关下载模型进行本地部署。我将详细讲解这两种方式的实现流程。
一、大模型
指参数规模庞大、训练数据量巨大、具有强泛化能力的人工智能模型,经典代码有:GPT,BERT、PaLM等。它们通常基于深度神经网络,特别是Transformer架构,在自然语言处理、图像识别、代码生成等任务中表现出色。
1.基本概率:
大模型是指在超大规模数据集上训练、拥有数十亿到千亿以上参数的人工智能模型,具备多任务、多模态能力,并能通过少量样本甚至零样本完成新任务
2.主要特征:
参数规模庞大
模型参数量可达数亿甚至数千亿级别,庞大的参数容量为其强大的表达与泛化能力奠定了基础。海量训练数据
训练过程通常依托于大规模文本、图像、音频等多模态数据,显著提升模型的通用性和适应能力。以Transformer为核心架构
当前主流大模型普遍采用Transformer结构,其自注意力机制赋予模型优异的表示学习和长程依赖建模能力。强大的泛化与迁移能力
通过一次预训练即可适应多种下游任务,如对话生成、代码编写、文本润色等,实现“一模型多用”。涌现出意料之外的能力
当模型规模超过某一临界点时,常展现出未在训练中明确设定的能力,例如复杂推理、创造性生成和跨任务泛化。灵活高效的调优机制
支持包括全参数微调(Fine-tuning)、提示学习(Prompt Learning)以及参数高效方法(如LoRA、Adapter)在内的多种优化策略。多模态融合成为趋势
大模型正逐渐从纯文本处理扩展至图像、语音、视频等多模态理解与生成,代表性模型包括GPT-4V、DeepSeek-Vision、Grok等。
二、API调用部署:
API调用是目前最常见,也是最便捷的使用方式,无需训练模型,只需调用接口即可利用AI的能力
1.基本流程:
获取 API 权限
注册平台账号(如 OpenAI、DeepSeek、阿里通义、讯飞星火等)
获取
API Key或Access Token准备请求参数
选择模型
设置请求体
发起 API 请求
使用编程语言(如 Python、JavaScript)通过 HTTP 协议调用接口
解析响应结果
获取模型返回内容(如文本、图片链接、结构化数据等)
可与前端、应用系统集成使用
2.具体操作:
这里我以DeepSeek为例,
2.1 准备工作


-
访问deepseek官网,并注册账号:DeepSeek官网
-
注册账号并且充值
-
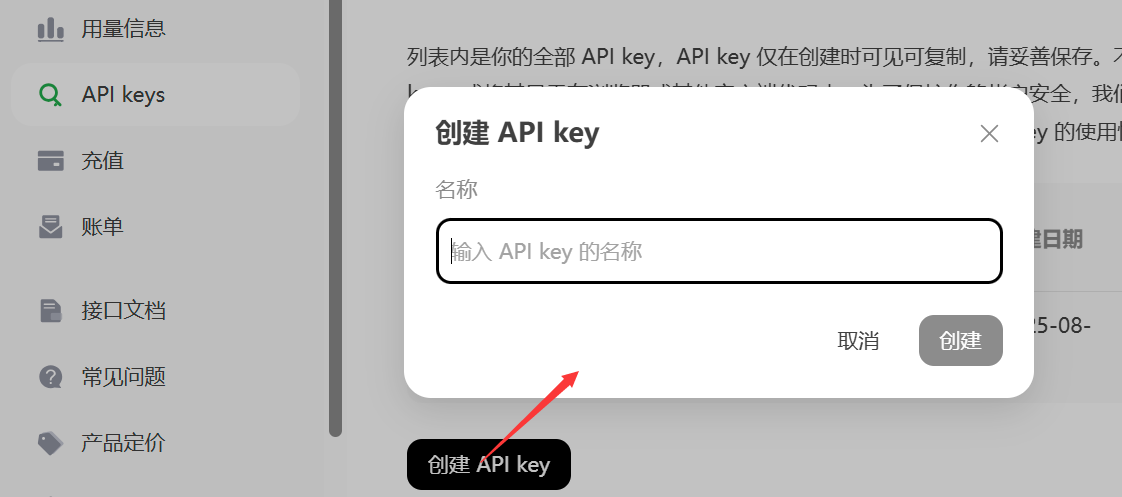
创建API-key
-
==仅在创建时可见可复制==
-
查看使用手册
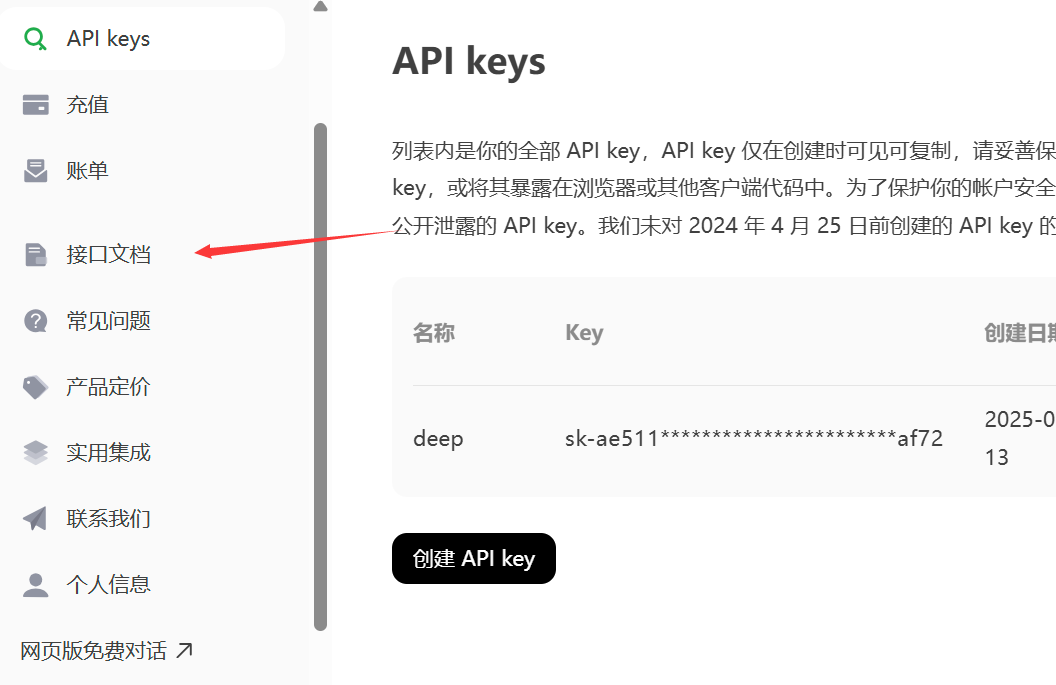
进入后有对应的调用方法:这里我以python为例
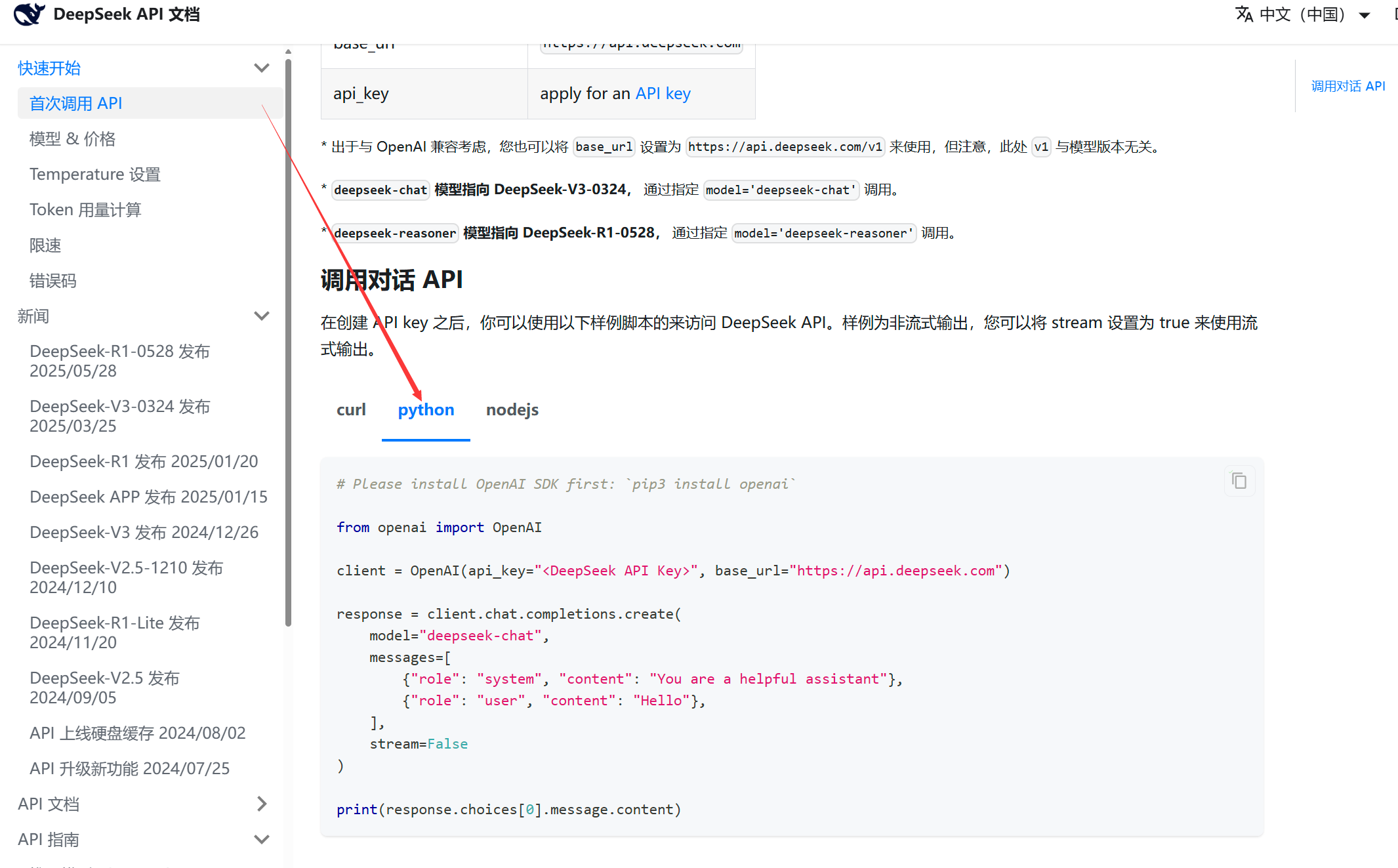
2.2 输出方式
其中输出方式分为:流式输出(stream=True)和非流式输出(stream=False)
区别:
2.2.1流式输出
服务器将响应内容一段一段地实时返回,适合长文本、对话、写作等需要即时反馈的场景。
-
特点
-
优点
-
响应快:无需等全部生成完毕,先生成先返回
-
体验佳:像人打字一样流畅,常用于对话机器人
-
可中断:用户可随时打断流式响应过程
-
-
缺点
-
编程稍复杂,需要处理数据流拼接
-
不易直接使用普通 HTTP 请求工具(如 Postman)
-
-
2.2.2非流式输出
等模型生成完整结果后一次性返回,适合短文本、结构化内容提取等任务。
-
特点
-
优点:
-
使用简单,一次性拿到完整结果
-
适合分析处理、摘要抽取、短文本问答等
-
-
缺点:
-
响应时间长,特别是文本很长时
-
体验较差,用户需要等待全部生成完才能看到内容
-
-
3.具体案例
环境安装:
pip install openai
采用非流式输出:
from openai import OpenAI
#deep
url="https://api.deepseek.com/v1"
api_key="your_key"
#建立连接
client = OpenAI(api_key=api_key,base_url = url)
prompt = "给出讲个故事"
message =[
{"role":"system","content":"你是一个helpful的助手"},
{"role":"user","content":prompt}
]
response = client.chat.completions.create(
model ="deepseek-chat",
messages=message,
max_tokens=512,
temperature=0.5,
stream =False,#流式输出
)
print(response.choices[0].message.content)采用流式输出:
from openai import OpenAI
#deep
url="https://api.deepseek.com/v1"
api_key="your_key"
#建立连接
client = OpenAI(api_key=api_key,base_url = url)
prompt = "给出讲个故事"
message =[
{"role":"system","content":"你是一个helpful的助手"},
{"role":"user","content":prompt}
]
response = client.chat.completions.create(
model ="deepseek-chat",
messages=message,
max_tokens=512,
temperature=0.5,
stream =True,#流式输出
)
#采用获取断点,逐步输出断点的方式输出
for chunk in response:
print(chunk.choices[0].delta.content,end='')效果如下:

总结步骤:
使用大模型库,并使用openai的模型来调用
大模型获取地址:deepseek开发版,通义,元宝.....,硅基流动代码实施步骤:
1.获取key和url
2.建立连接
3.创建prompt和message[]->prompt为用户输出的问题,message则定义大模型的模式,用户输出的问题是什么
4.推理->cient.chat.completions.create
5.输出显示
三、本地部署
各种大模型下载地址:
国类开源网站,类似huggingface,好处不用梯子。点击模型库--模型文件--SDK下载
镜像:HF-Mirror
1.本地部署步骤
1.1 模型下载
魔塔:
若在魔塔下载,需安装魔搭组件
pip install modelscope==1.18.1
将模型下载在本地cache_dir目录
from modelscope.hub.snapshot_download import snapshot_download
llm_model_dir = snapshot_download('Qwen/Qwen3-0.6B',cache_dir='models')
Huggingface
组件下载
pip install huggingface_hub
from huggingface_hub import snapshot_download
llm_model_dir = snapshot_download('Qwen/Qwen3-0.6B',cache_dir='models')
或在终端下载:
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir ./deepseek-1.5B
1.2 具体案例
from sympy.printing.pytorch import torch
from transformers import AutoTokenizer,AutoModelForCausalLM
model_dir = './models/Qwen/Qwen3-0___6B'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#定义模型
model = AutoModelForCausalLM.from_pretrained(model_dir)
model.to(device)
#加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_dir)
#
prompt="请讲一个故事"
message = [
{"role":"system","content":"你是一个helpful助手"},
{"role":"user","content":prompt}
]
#将输入的字符串转为token
inputs = tokenizer.apply_chat_template(
message,
tokenize = True,
add_generation_prompt = True,
return_tensors = "pt",
add_special_tokens = True,
)
inputs = inputs.to(device)
#inputs.shape()->为(1,token数)
#定义推理参数
keywords = dict(
do_sample = True,# 是否采样
top_k = 10,#选取10个最大概率的词
top_p = 0.8,#概率阈值,
temperature = 0.6,#用于控制输出的随机性,0-1之间,越小输出越稳定,如果重复性过高时可适当增加
max_length =512, #最大输出长度
)
#模型推理
with torch.no_grad():
outputs = model.generate(inputs,**keywords)
# 通过解码器将token转为词输出
input_length = inputs.shape[1]
new_inputs = outputs[0][input_length:]
response = tokenizer.decode(new_inputs,skip_special_tokens=True)
print(response)效果展示:

代码实现步骤总结:
推理使用模型:transformers
步骤:
导入两个关键库,transformers.AutoTokenizer,AutoModelForCausalLM
1.模型选择;model_path
2.加载模型;
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AutoModelCausalLM.from_pretrained(model_path,torch_dtype="auto",device=device)
3.定义tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
4.定义prompt和message[]
5.将输入字符串转为token标签->
使用tokenizer.apply_chat_template(
message,
tokenize,#是否转为token
add_generation_prompt,#是否添加生成词
return_tensor,
add_special_tokens=True,
)
6.设定推理参数
gen_kwargs = dict(
do_sample= ,
top_k,#选择前k个概率最大的词
top_p,
temperature=,
max_length=,)
7.开始模型推理
梯度清零调用模型
outputs = model(input,**gen_kwargs)
response = tokenizer.decode(outputs[0],skip_special_tokens=True)
print(response)

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)