
快来微调一个Qwen3-1.7b医疗大模型,大模型入门到精通,收藏这篇就足够了!
在本文中,我们会使用Qwen3-1.7b模型在delicate_medical_r1_data数据集上做全参微调以及Lora微调训练,实现让微调后的 Qwen3 支持对医学问题进行DeepSeek R1式的推理回复。
目录:
- 免费算力
- 数据准备
- 配置SwanLab训练记录工具
-
- 安装SwanLab
-
- 登录账号
-
- 开启一个实验并跟踪超参数
-
- 记录实验指标
-
- 在线查看可视化看板
- 加载模型
- 模型全参数微调
- 参数高效微调 (PEFT):LoRA
- 推理阶段
- 添加一个简单记忆功能
- 实现思路
- 总结
在本文中,我们会使用Qwen3-1.7b模型在delicate_medical_r1_data数据集上做全参微调以及Lora微调训练,实现让微调后的 Qwen3 支持对医学问题进行DeepSeek R1式的推理回复。训练中用到了transformers、datasets等工具,同时使用SwanLab监控训练过程、评估模型效果。
全参数微调需要大约32GB显存,如果你的显存大小不足,可以使用Lora微调,大约需要10G显存。
免费算力
魔塔社区
注册魔塔社区,会提供一张NVIDIA A10 24GB的显卡,可免费使用36小时
在mynotebook页面可以启动实例使用单卡进行训练

数据准备
本案例使用的是 delicate_medical_r1_data 数据集,该数据集主要被用于医学对话模型。
数据集链接:
https://modelscope.cn/datasets/krisfu/delicate_medical_r1_data
该数据集由2000多条数据组成,每条数据包含Instruction、question、think、answer、metrics五列:

- question:用户提出的问题,即模型的输入
- think:模型的思考过程。大家如果用过DeepSeek R1的话,回复中最开始的思考过程就是这个
- answer:模型思考完成后,回复的内容
我们的训练任务,便是希望微调后的大模型,能够根据question,给用户一个think+answer的组合回复,并且think和answer在网页上的展示有区分。
使用方法:
from modelscope.msdatasetsimportMsDataset
数据下载到本地之后,我们需要对数据集进行处理,以便模型训练
我们设计这样一个数据集样例:
{
数据处理的代码:
from modelscope.msdatasets import MsDataset
输出:
The dataset has been split successfully.
查看数据样本:
import json
输出:
{'instruction': '说明测定盐酸甲氧明注射液含量的具体步骤。',
完成后,你的代码目录下会出现训练集 train.jsonl和验证集 val.jsonl文件。
至此,数据集部分完成。
配置SwanLab训练记录工具
我们使用SwanLab来监控整个训练过程,并评估最终的模型效果。
SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,面向人工智能与深度学习开发者,提供了一个跟踪、记录、比较、和协作实验的平台。SwanLab同时支持云端和离线使用,并适配了从PyTorch、Transformers、Lightning再到LLaMA Factory、veRL等30+ AI训练框架。
链接:https://docs.swanlab.cn/
1. 安装SwanLab
使用 pip 在Python3环境的计算机上安装swanlab库。
打开命令行,输入:
pip install swanlab
按下回车,等待片刻完成安装。
如果遇到安装速度慢的问题,可以指定国内源安装:
pip install swanlab -i https://mirrors.cernet.edu.cn/pypi/web/simple
2. 登录账号
如果你还没有SwanLab账号,请在 官网 免费注册。
打开命令行,输入:
swanlab login
当你看到如下提示时:
swanlab: Logging into swanlab cloud.
在用户设置页面复制您的 API Key,粘贴后按下回车,即可完成登录。之后无需再次登录。
3. 开启一个实验并跟踪超参数
在Python脚本中,我们用swanlab.init创建一个SwanLab实验,并向config参数传递将一个包含超参数键值对的字典:
import swanlab
run是SwanLab的基本组成部分,你将经常使用它来记录与跟踪实验指标。
4. 记录实验指标
在Python脚本中,用swanlab.log记录实验指标(比如准确率acc和损失值loss)。
用法是将一个包含指标的字典传递给swanlab.log:
swanlab.log({"accuracy": acc, "loss": loss})
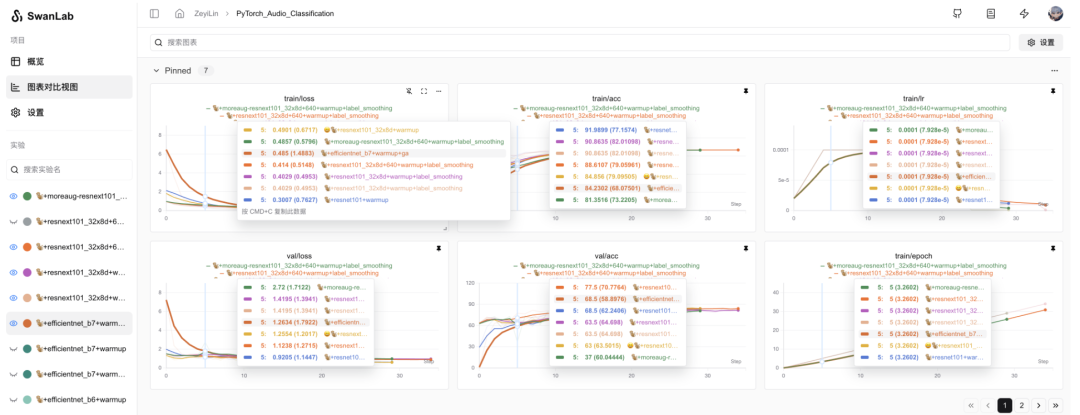
5. 在线查看可视化看板
访问SwanLab,查看在每个训练步骤中,你使用SwanLab记录的指标(准确率和损失值)的改进情况。
quick-start-1
加载模型
这里我们使用modelscope下载Qwen3-1.7B模型,然后把它加载到Transformers中进行训练:
import torch
模型全参数微调
模型的全参数微调代码如下:
import json
如果进行全参数微调的话,24G显存可能会爆显存,所以需要使用参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT)
参数高效微调 (PEFT):LoRA
代码如下:
import json
在Swanlab可以看到可视化训练以及预测结果:
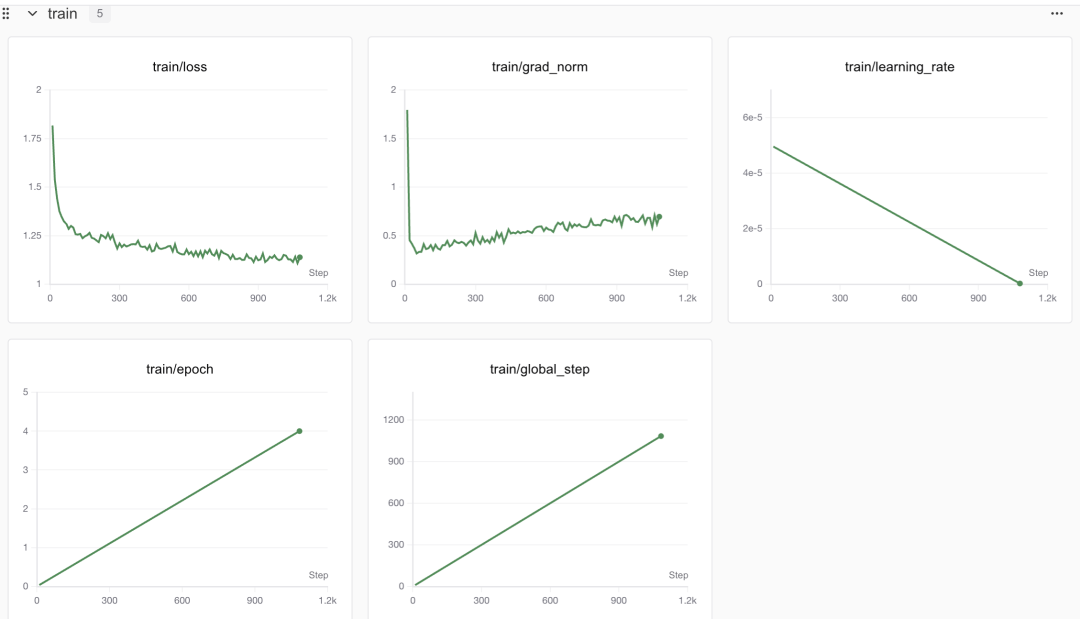

测试的结果如下:
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
推理阶段
为了更好的体验效果,我们把推理阶段改为流式输出
from peft import PeftModel
回答:<|FunctionCallBegin|>嗯,用户问的是头痛的常见原因有哪些,以及如何根据不同的原因选择合适的药物。首先,我需要回忆一下常见的头痛类型,比如紧张性头痛、偏头痛、丛集性头痛,还有其他类型比如血管性头痛或者颅内压增高引起的。然后,针对每种头痛类型,常见的治疗方法是什么,药物上有什么区别。
添加一个简单记忆功能
实现思路
- 维护一个
messages列表:这个列表不再是每次都重新创建,而是在整个程序运行期间持续存在。 - 启动一个聊天循环:使用一个
while True:循环来不断接收用户的输入。 - 追加对话历史:
- 每次用户输入后,将用户的提问(
role: "user")追加到messages列表。 - 调用模型获得回答后,将模型的回答(
role: "assistant")也追加到messages列表。
- 将完整的历史传给模型:在每次调用
predict_stream函数时,传入的都是包含从开始到现在的所有对话记录的messages列表。
import json
总结
本文围绕Qwen3 - 1.7b医疗大模型微调展开实践,利用免费算力,完成医疗数据准备,配置SwanLab训练记录工具(含安装、登录、实验创建、指标记录及可视化看板查看 );加载模型后,探索全参数微调与基于PEFT的LoRA高效微调策略;进入推理阶段,还为模型添加简单记忆功能(明确实现思路 ),全流程覆盖数据、工具、训练到功能增强,验证模型适配医疗场景可行性,后续可深化优化,进一步理解大模型。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 37
37 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)