
魔搭社区模型速递(8.10-8.16)

🙋魔搭ModelScope本期社区进展:
📟5285个模型:GLM-4.5V系列、Hunyuan-GameCraft、Baichuan-M2-32B系列、MiMo-VL-7B-RL-2508、EchoMimicV3等;
📁497个数据集:openai_harmony_vocab、Image-Vid-Finetune-Src、Mochi-Black-Myth等;
🎨59个创新应用:DocResearch-文档深度研究、HelloMeme-v2、MiDashengLM-7B等;
📄 9篇内容:
- ModelScope魔搭25年8月发布月报
- 腾讯混元最新开源:一张图,秒变游戏大片
- 9.24-9.26,与魔搭,云栖见!
- 本地也能玩转AI图片创作?腾讯3B开源模型实测:精准又轻便,统一生成理解,手把手教你部署
- LoRA 模型的全新玩法——AutoLoRA 带你体验 LoRA 检索与融合的魔法
- 直播预告 | Qwen-lmage 技术分享+实战攻略直播
- 原生支持QwenImage!FlowBench 正式开启公测!本地 + 云端双模生图,AI创作更自由
- 智谱发布GLM-4.5V,全球开源多模态推理新标杆,Day0推理微调实战教程到!
- 8月23日南京Unstructured Data Meetup 启动
01.模型推荐
GLM-4.5V系列
智谱近期发布了最新的 GLM-4.5V 开源工作——全球100B级效果最佳的开源视觉推理模型。GLM-4.5V 基于智谱新一代旗舰文本基座模型 GLM-4.5-Air(106B参数,12B激活),延续 GLM-4.1V-Thinking 技术路线,在 42 个公开视觉多模态榜单中综合效果达到同级别开源模型 SOTA 性能,涵盖图像、视频、文档理解以及 GUI Agent 等常见任务。
GLM-4.5V 通过高效混合训练,具备覆盖不同种视觉内容的处理能力,实现全场景视觉推理,包括:图像推理(场景理解、复杂多图分析、位置识别)、视频理解(长视频分镜分析、事件识别)、GUI 任务(屏幕读取、图标识别、桌面操作辅助)、复杂图表与长文档解析(研报分析、信息提取)、Grounding 能力(精准定位视觉元素)。同时,模型新增 “思考模式” 开关,用户可灵活选择快速响应或深度推理,平衡效率与效果,该开关的使用方式与GLM-4.5 语言模型相同。
模型合集:
https://modelscope.cn/collections/GLM-45V-8b471c8f97154e
示例代码:
- 环境安装
对于SGLang和transformers:
git clone https://github.com/zai-org/GLM-V.gitcd GLM-pip install -r requirements.txt
vLLM
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install transformers-v4.55.0-GLM-4.5V-previewvLLM推理
vllm serve zai-org/GLM-4.5V \
--tensor-parallel-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5v \
--allowed-local-media-path / \
--media-io-kwargs '{"video": {"num_frames": -1}}'
SGlang推理
python3 -m sglang.launch_server --model-path zai-org/GLM-4.5V \
--tp-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--served-model-name glm-4.5v \
--port 8000 \
--host 0.0.0.0
更多模型推理教程实战详参:
本地也能玩转AI图片创作?腾讯3B开源模型实测:精准又轻便,统一生成理解,手把手教你部署
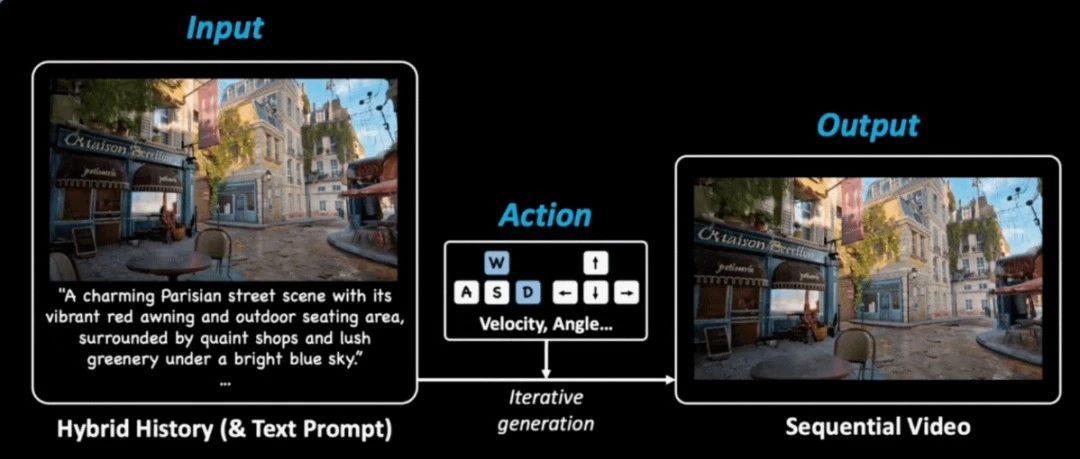
Hunyuan-GameCraft
腾讯混元最新开源的游戏视频生成工具Hunyuan-GameCraft,只需要输入一张图+文字+描述+动作指令(按键盘方向键),就能 输出高清动态游戏视频,无论是第一人称跑酷,还是第三人称探险,它都能实时生成流畅画面,仿佛你真的在游戏世界里自由穿梭。
Hunyuan-GameCraft具备三大优势:
- 自由流畅:统一连续动作空间,支持高精度控制(角度/速度),支持“边跑边转视角”的复杂操作;可以生成动态内容(例如主角和NPC运动、云层移动、雨雪、水流运动等);
- 记忆增强:生成长视频时,角色和环境保持稳定不“穿帮”;通过混合历史条件,实现历史帧记忆,避免长视频生成时不连贯;
- 成本骤降:无需人工建模或渲染,制作成本更低;对比现有的游戏模型闭源方案,泛化性强。阶段一致性蒸馏方案和DeepCache压缩推理步数,量化13B模型支持消费级硬件RTX 4090,无需高端服务器。
模型链接:
https://www.modelscope.cn/models/Tencent-Hunyuan/Hunyuan-GameCraft-1.0
效果示例详见:
Baichuan-M2-32B系列
Baichuan-M2-32B 是百川 AI 近期最新开源的的医疗增强推理模型,是百川发布的第二款医疗模型。该模型专为现实世界的医疗推理任务设计,在 Qwen2.5-32B 的基础上结合了创新的大型验证系统。通过对真实世界医疗问题进行领域特定微调,它在保持强大通用能力的同时实现了突破性的医疗性能。
Baichuan-M2的核心亮点:
- 全球领先的开源医疗模型:在HealthBench上超越所有开源模型以及许多专有模型,达到接近GPT-5的医疗能力;
- 医生思维对齐:基于真实的临床案例和患者模拟器训练,具备临床诊断思维和强大的患者互动能力;
- 高效部署:支持单RTX4090上的4位量化部署,在单用户场景下的MTP版本中,token吞吐量提高了58.5%。
模型链接:
- Baichuan-M2-32B:
https://www.modelscope.cn/models/baichuan-inc/Baichuan-M2-32B
- Baichuan-M2-32B-GPTQ-Int4:https://modelscope.cn/models/baichuan-inc/Baichuan-M2-32B-GPTQ-Int4
示例代码:
from modelscope import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-M2-32B", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-M2-32B")
# 2. Input prompt text
prompt = "Got a big swelling after a bug bite. Need help reducing it."
# 3. Encode the input text for the model
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
thinking_mode='on' # on/off/auto
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 4. Generate text
generated_ids = model.generate(
**model_inputs,
max_new_tokens=4096
)
output_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
][0].tolist()
# 5. parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
02.数据集推荐
openai_harmony_vocab
数据集可用于语言模型训练和自然语言处理任务,提供词汇表资源以优化文本生成与理解效果。
数据集链接:
https://modelscope.cn/datasets/ms15090385220/openai_harmony_vocab
Image-Vid-Finetune-Src
数据集主要用于视频生成模型的微调,提供图像和视频素材,帮助模型更好地学习视觉内容的生成和转换,提升视频生成质量。
数据集链接:
https://modelscope.cn/datasets/FastVideo/Image-Vid-Finetune-Src
03.创空间
DocResearch-文档深度研究
DocResearch 提供一站式文档深度研究服务,可把长文档秒变要点摘要、知识图谱与可交互问答。
体验链接:
https://modelscope.cn/studios/ms-agent/DocResearch
HelloMeme-v2
HelloMeme-v2 让一张照片秒变对口型、做表情的梗图视频,一键生成魔性表情包。
体验链接:
https://modelscope.cn/studios/zouwu0815/HelloMeme-v2
MiDashengLM-7B
可秒读财报、提炼研报要点并回答投资问题。
体验链接:
https://modelscope.cn/studios/midasheng/MiDashengLM-7B
04.社区精选文章
- ModelScope魔搭25年8月发布月报
- 腾讯混元最新开源:一张图,秒变游戏大片
- 9.24-9.26,与魔搭,云栖见!
- 本地也能玩转AI图片创作?腾讯3B开源模型实测:精准又轻便,统一生成理解,手把手教你部署
- LoRA 模型的全新玩法——AutoLoRA 带你体验 LoRA 检索与融合的魔法
- 直播预告 | Qwen-lmage 技术分享+实战攻略直播
- 原生支持QwenImage!FlowBench 正式开启公测!本地 + 云端双模生图,AI创作更自由
- 智谱发布GLM-4.5V,全球开源多模态推理新标杆,Day0推理微调实战教程到!
- 8月23日南京Unstructured Data Meetup 启动

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献712条内容
已为社区贡献712条内容

所有评论(0)